T-MAC
T-MAC:用查表让 CPU 重新适合低比特边缘 LLM
Jianyu Wei, Shijie Cao, Ting Cao, Lingxiao Ma, Lei Wang, Yanyong Zhang, Mao Yang
USTC, UCAS, Microsoft Research
EuroSys 2025
Presenter: wzw
Date: 2026-03-24
TL;DR
- 瓶颈:
low-bit weight虽然省了存储,但执行端仍要做W{1,2,3,4}A16的 mpGEMV/mpGEMM,现有 CPU kernel 往往退回dequantize + higher-precision compute。 - 方法: T-MAC 把 mixed-precision 乘法改写成
bit-serial LUT lookup + accumulation,并围绕 CPU 寄存器 / SIMD / layout 做系统化优化。 - 结果: 相比
llama.cpp,kernel 最多快6.6x、端到端吞吐最高约2.8x~6.7x,能耗下降20.6%~61.2%,BitNet-3B 在M2 Ultra上可到71 tok/s。
现有 low-bit 为何不香
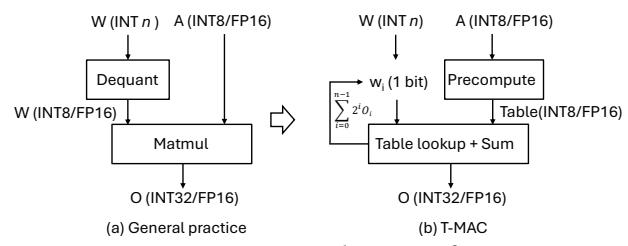
- 传统路径是: 先解码 / 反量化低比特权重,再用硬件支持的数据类型做高精度 GEMM。
- 这会同时带来两类损失:
dequantization overhead,以及 每种 bitwidth 都要单独写 layout + kernel。
bit 降低不一定更快
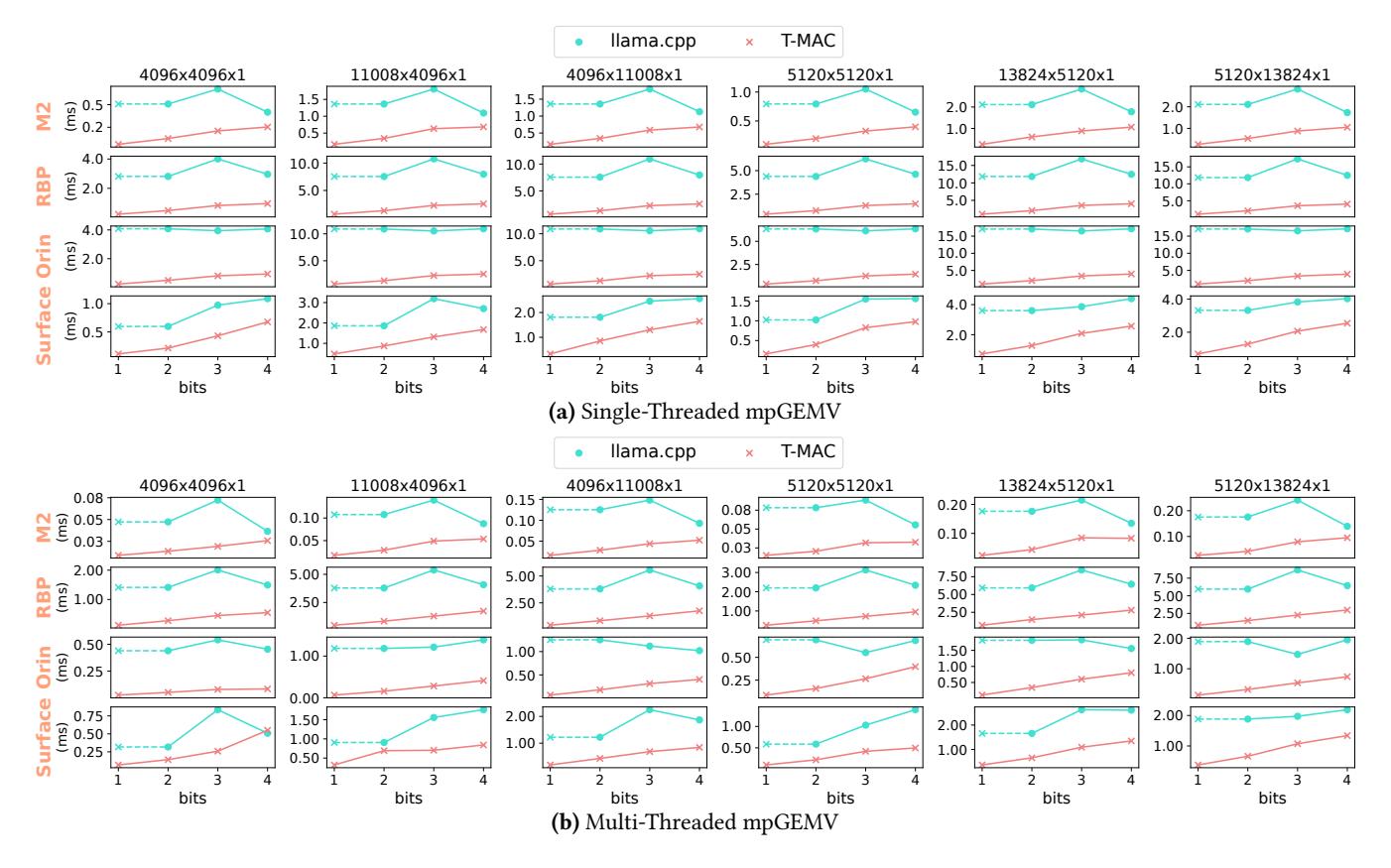
- Figure 6 的关键信号是:
llama.cpp从4-bit -> 2-bit并没有线性提速,3-bit甚至会比4-bit慢约15%。 - 所以真正的问题不是“权重够不够低”,而是 mixed-precision kernel 的执行路径根本没跟着变轻。
核心观察
$$ AW = \sum_i 2^i AW_i $$
为什么这很关键
INT4 / INT3 / INT2的差异被收敛成 bit-plane 个数差异。- 统一接口后,
A × W_i才能继续改写成 “预计算 activation + 运行时查表”。
T-MAC 全景图
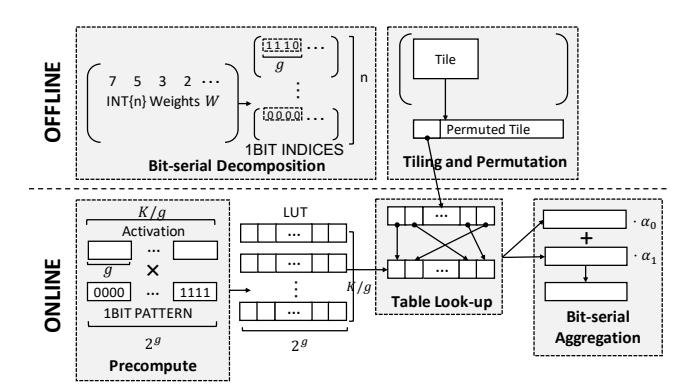
- Offline: 把权重拆成 bit-plane,并重排成便于加载与查表的格式。
- Online: 对 activation 的每个
[1,g]子向量预计算 LUT,再用权重 pattern 作为 index 查表并累加。 - 论文真正做的不是一个 kernel trick,而是一套 algorithm + layout + ISA-aware implementation。
一次 mpGEMM 如何改写
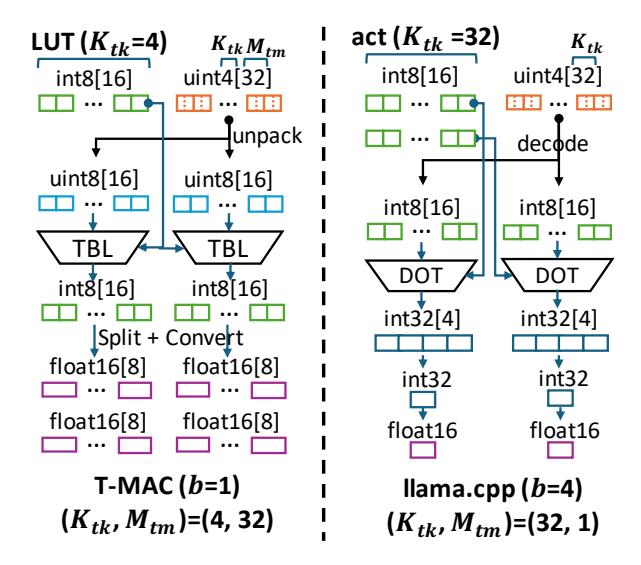
g=4时,每组 1-bit 权重只有16种 pattern,因此 activation 可先预计算成一张长度16的 LUT。- 在线阶段只做
unpack index + lookup + add,不再显式做decode + multiply-accumulate。
机制1:LUT 先放寄存器
- 局部问题: LUT lookup 是随机访问,如果仍走普通 cache / memory path,查表收益会被访存延迟吃掉。
- 做法: T-MAC 明确把 LUT 放进
on-chip memory,优先是 registers,并调用NEON TBL或AVX2 PSHUF做并行查表。 - 关键配套: loop order 从传统的
N/M first改成先沿K构表,再在M方向复用同一张 LUT。 - 结论: 这一步决定了 T-MAC 不是“理论上少乘法”,而是“实际上查得到快表”。
机制2:layout 也得改

- Weight permutation: 按 tile 访问顺序离线重排权重,让 DRAM load 更顺序化。
- Weight interleaving: 解决 little-endian unpack 时的额外重排,尽量把 index 直接展开成查表所需顺序。
- 论文里 interleaving 本身就能再给 最高
1.42x,说明 T-MAC 的收益很大一部分来自 memory-format co-design。
机制3:把 LUT 缩到能放下
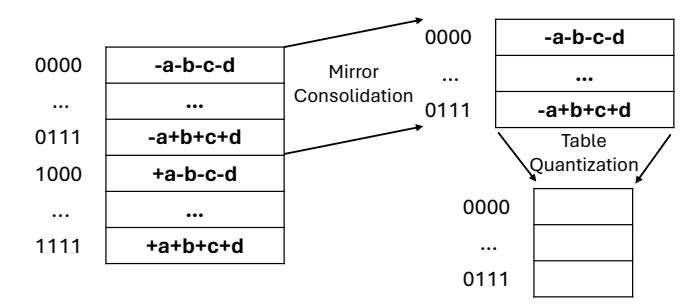
- Mirror consolidation: 利用 LUT 的正负对称性,只存一半表项,另一半通过 sign flip 恢复。
- Table quantization: 再把 LUT value 从
fp16压成int8,减少寄存器与带宽压力。 - 两者合起来可把 LUT footprint 压到 原来的
1/4,这是“寄存器驻留”能否成立的硬约束。
实现细节决定成败
- Codegen: 用
TVM + LLVM + AutoTVM为不同 shape / 平台生成 kernel,而不是手写一份静态实现。 - ISA mapping:
NEON vqtbl1q_u8/AVX2 _mm256_shuffle_epi8做 lookup;量化后还能用vrhaddq_u8/_mm256_avg_epu8做 fast aggregation。 - 工程坑点: 直接把 TVM runtime threadpool 嵌进
llama.cpp会冲突,作者最终改成 生成 C++ 单线程 block kernel,再挂到 llama.cpp threadpool。 - 设计点:
g=4很重要,因为它正好让 LUT 与 SIMD width 匹配;更大g会明显抬高寄存器与指令开销。
实验方法
- Platforms:
M2 Ultra,Raspberry Pi 5,Jetson AGX Orin,Surface Book 3。 - Models:
Llama-2-7B/13B的4/3/2/1-bit,以及BitNet 1-bit / 1.58-bit。 - Baseline:
llama.cppb2794 (May 2024);mpGEMM 场景额外对比llama.cpp (BLAS)。 - Kernel eval: warmup 后重复
100次;model eval: 生成64 tokens × 20轮。 - 一个优点: 覆盖了 Apple Silicon、Intel、ARM Cortex 和 Raspberry Pi,确实是在验证 “edge CPU”。
Kernel 结果很强
- 单线程 mpGEMV 下,T-MAC 在
1/2/3/4-bit上最高分别达到11.2x / 5.8x / 4.7x / 3.1x。 - 多线程时会更受 memory bandwidth 约束,但
2-bit仍能在四个平台上拿到4.0x / 4.0x / 5.3x / 2.5x。 - 这证明 T-MAC 的亮点是: bit 越低,收益越接近线性释放。
端到端吞吐也成立
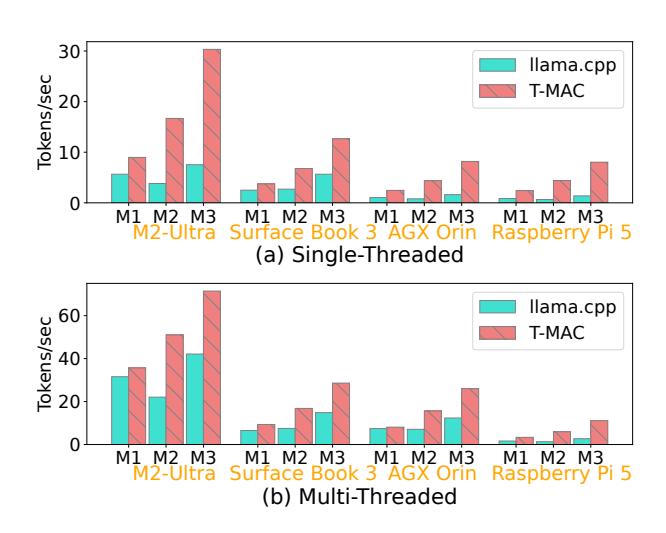
- 集成到
llama.cpp后,单线程 Raspberry Pi 5 上三种模型分别有2.8x / 6.7x / 5.8x的 speedup。 - headline 数字是: BitNet-b1.58-3B 在 M2 Ultra 单核
30 tok/s、8 核71 tok/s,在 Raspberry Pi 5 上也能到11 tok/s。
能耗收益很实在
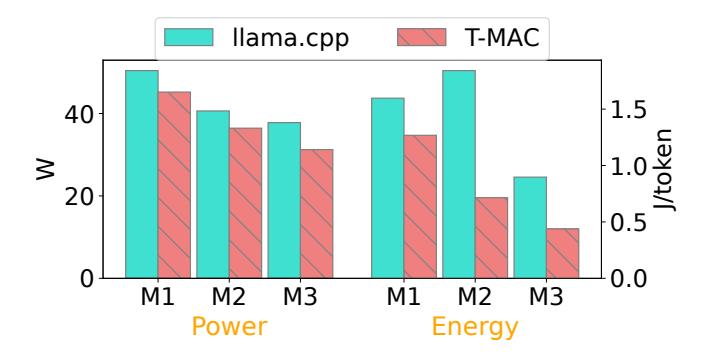
- 在
M2 Ultra多线程上,三种模型的功耗分别下降10.3% / 10.3% / 17.3%。 - 叠加吞吐提升后,总能耗进一步下降
20.6% / 61.2% / 51.3%。 - 这说明 T-MAC 并不是“用更多硬件换时间”,而是 去掉无效 dequantization 与乘法后,time 和 energy 一起下降。
优化拆解说明真因
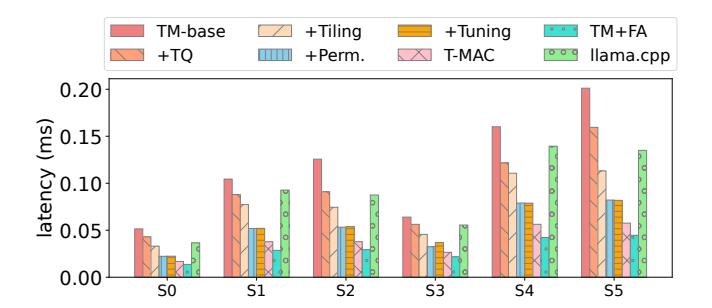
TM-base只有 intrinsic lookup,但最多仍比 baseline 慢17%;说明“想到 LUT”本身并不够。table quantization先把性能拉回 baseline 附近,随后tiling、permutation、interleaving分别继续带来1.45x、1.39x、1.42x。- 所以论文最强的地方不是算法式子,而是 一整套让 LUT 真能在 CPU 上跑快的 layout / implementation stack。
精度边界讲得很诚实
- 不开
Fast Aggregation时,T-MAC 与llama.cpp的模型质量几乎一致。 - 例如
Llama-2-7B-4bit单线程上,llama.cpp = 5.65 tok/s,T-MAC = 7.34 tok/s,但WikiText2 PPL都是5.96,WinoGrande都是70.8。 - 开启
Fast Aggregation后吞吐可到8.97 tok/s,但WikiText2 PPL变成6.38、WinoGrande降到67.8。 - 论文的态度很清楚: 精度安全版本已经能赢,进一步的激进近似只是可选项。
和 GPU / NPU 比如何
- 在
Jetson AGX Orin上,T-MAC 的 CPU kernel 在W1A16上明显优于 GPU,在W2A16/W3A16上也接近 GPU。 - 端到端
Llama-2-7B-2bit上,T-MAC CPU = 15.62 tok/s,llama.cpp CPU = 7.08,llama.cpp GPU = 20.03;虽然吞吐仍落后 GPU,但 每 token 能耗只有0.66 J,远低于 GPU 的1.54 J。 - 更激进的是 Table 7:
Surface Laptop 7上2-bit能到31.83 tok/s,约为 NPU 的3x;OnePlus 12上相对 Adreno GPU 最多9.7x。 - 但注意这不等于“CPU 全面压过 GPU/NPU”,它成立的前提是 低 bit + decode-like + memory-bound。
结论
- T-MAC 抓对了问题: edge low-bit LLM 真正卡的是 dequantization 与 mixed-precision kernel mismatch。
- 论文的关键贡献不是单纯“用 LUT”,而是 bit-serial rewrite + LUT-centric layout + storage reduction + ISA-aware implementation 一起闭环。
- 如果只记一句话: 它证明了在低比特 decode 这个点上,CPU 可以通过查表范式重新变得有竞争力。
我的评价
- 最强点: 它不是空谈“lookup 比 multiply 高效”,而是把寄存器驻留、SIMD intrinsic、threadpool 集成这些落地问题都认真处理了。
- 主要局限: baseline 主要围绕
llama.cpp,对 preprocessing cost 与更新代 CPU kernel 的比较还不够充分。 - 边界条件: 这条路线更适合
sub-4-bit、decode-dominant、memory-bound场景;prefill 或更高精度下优势会收缩。 - 后续方向: 可以继续走向
CPU ISA extension / tiny LUT accelerator,或者和KV-cache optimization / speculative decoding做更完整的系统协同。