STFL-DDR: Improving the Energy-Efficiency of Memory Interface
STFL-DDR:提升内存接口能效
Payman Behnam, Mahdi Nazm Bojnordi
University of Utah
IEEE TC 2020
Presenter: wzw
Date: 2026-03-31
三句话看懂
- 瓶颈: DRAM
data bus的能耗很高,DDR4靠 termination 和高频率拿带宽,LPDDR3靠 unterminated wires 省电,但会明显掉带宽。 - 方法: STFL-DDR 用
LPDDR3 data wires + DDR4 clock/mode wires + transition-based encoding,强制相邻周期不连续翻转,在低功耗线上跑高参考时钟。 - 结果: 仅优化 DRAM 接口时,interface energy 相对 LPDDR3 再降
17%;同时优化 LLC + DRAM 后,system energy / EDP / performance 分别改善8% / 15% / 9%,且性能达到 HP baseline 的98%。
为什么值得看

- Fig.1 说明:LLC + DRAM I/O 合起来约占系统能耗
33%,data movement 已经不是边角料。 - 其中 off-chip wires 既要高带宽,又要低能耗,正好把 DDR-style 高性能接口和 LPDDR-style 低功耗接口推到冲突面。
传统接口的两难
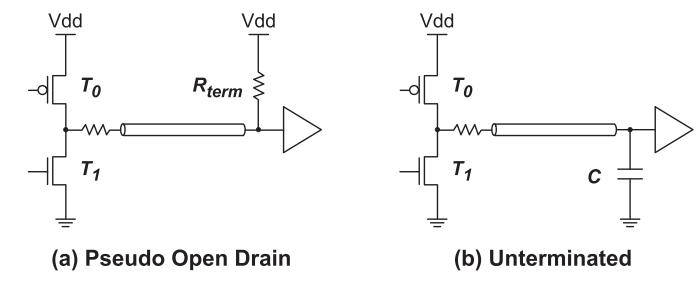
- DDR4 / pseudo open drain: 有 termination,能跑高数据率,但
read/write都要付出额外功耗。 - LPDDR3 / unterminated: 把 termination power 几乎清掉,但 wire 速度慢,系统容易被 bandwidth loss 反噬。
- 所以问题不是“怎么再省一点 bit flips”,而是能不能保留 LP 的低功耗,同时尽量拿回 DDR 的吞吐。
关键观察
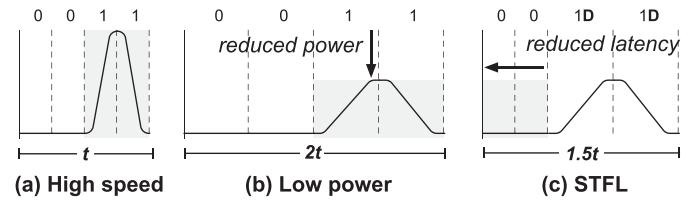
- Fig.3 的核心不是让低功耗线“真的更快翻转”,而是把
1编成 transition、0编成 no-transition。 - 每出现一次
1,下一拍强制插入 dummy0,从而保证 不会有连续两拍翻转,信号完整性才撑得住。 - 这让 STFL 变成一个新 tradeoff: 功耗接近 LP,传输时间明显短于 LP。
总体方案
- 数据线: 借用
LPDDR3 @ 800 MHz的 low-power unterminated wires。 - 时钟与 mode bit: 借用
DDR4 @ 1600 MHz的 high-performance wires。 - 新增逻辑: 每组 8 根 data wires 前后各加
encoder / transmitter / receiver / decoder,controller 负责管理编码与模式位。
机制 1:发送端怎么工作
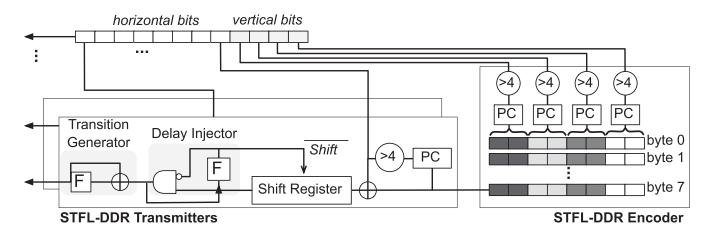
- 先对每个 byte 计算
Hamming weight,若大于 4 就先取反,保证一条 data wire 上发送的1不会超过 4 个。 - 然后
shift register + transition generator把 bitstream 变成 wire flips。 delay injector在每个1后插入 dummy0,把最大 transition rate 压到安全范围内。
机制 2:接收端怎么还原
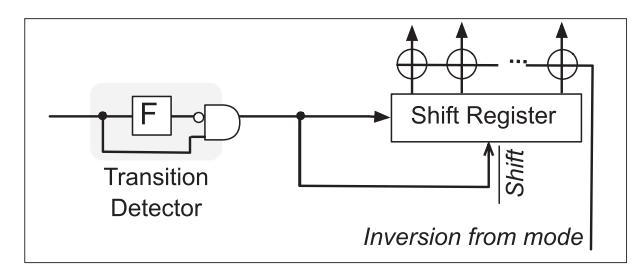
transition detector用XOR + flip-flop把“有翻转”恢复成1,没翻转恢复成0。- receiver 看到
1时暂停 shift,相当于把前一拍插入的 dummy0覆盖掉。 - 最后再按 inversion bit 做
XOR,把原始 byte 还原回来。
机制 3:二维编码
- 仅靠“每个 byte 自己取反”还不够,STFL-DDR 还对每个
8 x 8数据块做两阶段编码。 - Phase 1: 对相邻列做
XOR,如果结果HW > 4,就翻转左列并设置 vertical mode bit,提高列间相似性。 - Phase 2: 对每一行单独看
HW,若HW > 4,就翻转该行并设置 horizontal mode bit。 - 这一步的目标不是最优压缩,而是给 signaling 一个稳定的输入分布。
为什么要压到 4 个 1
- 关键硬约束是
HW(row) <= 4。 - 每条 data wire 上,8-bit 数据最坏只需插入 4 个 dummy
0。 - 所以传输长度和最大 transition rate 都能被上界化,编码也就成了 signaling 的 correctness guard。
一次传输怎么走
- Step 1: 输入的
8 x 8数据块先做两阶段编码,得到 data bits 和 mode bits。 - Step 2: 每条 data wire 把
1变成 transition、把0变成 no-transition,并在每个1后自动插入 dummy0。 - Step 3: 所有 mode bits 走独立的 DDR4-style mode wire,data 走 LPDDR3-style unterminated wires。
- Step 4: receiver 检测 transition、删除 dummy
0、恢复 inversion 后的原始数据。 - 一句话: STFL-DDR 把“wire 太慢”这个物理问题,改写成“编码后每条 wire 的
1必须足够稀疏”。
带宽怎么算回来
- STFL-DDR 用
1600 MHzreference clock,但要求实际 transition 频率不超过800 MHz。 - 关键吞吐计算是
8 bits / 6 cycle times ≈ 1.33 bits per cycle time。 - 对应的有效带宽约为
2.13 Gbps。
这个带宽点位意味着什么
- STFL-DDR 的目标不是追平最强 speed bin 的 DDR4,而是用更低能耗逼近一个中高档 DDR 点位。
- 所以它的 headline 不是 peak bandwidth,而是 energy-efficiency at a useful operating point。
- 后面的能耗、性能、EDP 结果,本质上都在验证这个 operating point 是否值得。
硬件账单
- 综合结果: 对 64-bit DRAM interface,
STFL encoder面积约1642 um^2、延迟0.831 ns、功耗0.49 mW。 STFL decoder面积约102 um^2、延迟0.071 ns、功耗0.71 mW。- 相比
BD和CAFO,STFL 的编码/解码硬件 面积更小,延迟和功耗也在同一量级。 - 真正的风险不在 combinational logic,而在 混合 PHY 假设: 论文复用了
LPDDR3 data wires + DDR4 clock/mode wires,工业落地需要更细的 SI / validation 证据。
方法学
- Infrastructure:
ESESC + HSPICE + PTM 22nm + CACTI IO + Micron power calculator + DRAMPower + McPAT。 - Processor:
4-core OoO @ 3.2GHz,32KB L1,4MB shared LLC,2 DRAM channels。 - Baselines: binary encoding、
DBI、BD、CAFO、DESC、SETS,以及LP baseline。 - Workloads: 共
12个并行 benchmark,来自NAS OpenMP + SPLASH-2 + Phoenix。 - 关键假设: DRAM core timing 统一按
DDR4-2133建模,但t_BURST = 6for STFL-DDR,4for others。
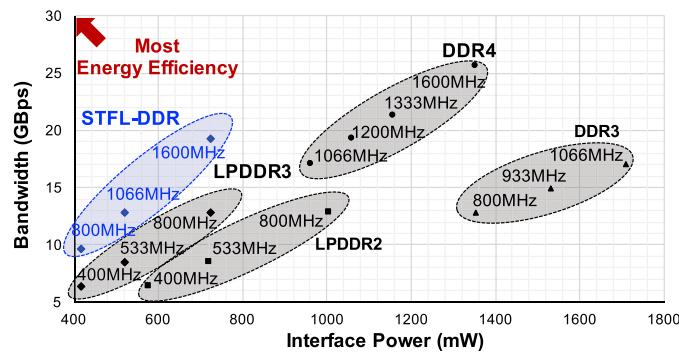
结果 1:接口能耗
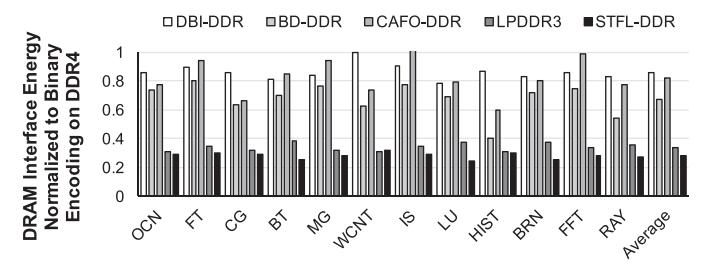
- Fig.14 看的是 仅优化 DRAM I/O 时的 interface energy。
- STFL-DDR 相对传统高性能接口,平均把 DRAM interface energy 压到
28%左右,也就是-72%。 - 相对 LPDDR3 baseline,STFL-DDR 还能继续下降
17%,说明收益不只是“换成 unterminated wires”,还来自 编码降低 switching。
结果 2:DRAM 总能量
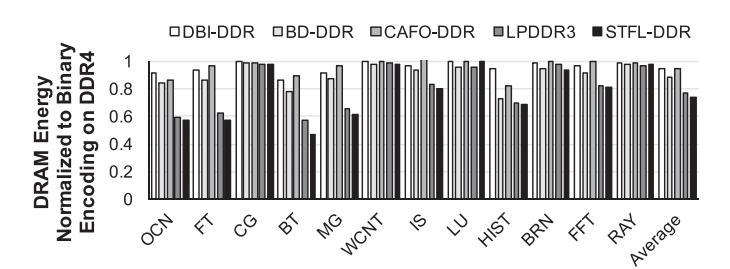
- Fig.15: 仅看 DRAM,总能量平均
-26%;但对多数应用,LPDDR3 也有-22%,说明很多 workload 对带宽不敏感。 BT这类高带宽应用是例外:LP 虽然更省 DRAM energy,但会因带宽不足拉长时间,静态能耗反而更高。
结果 3:系统功耗
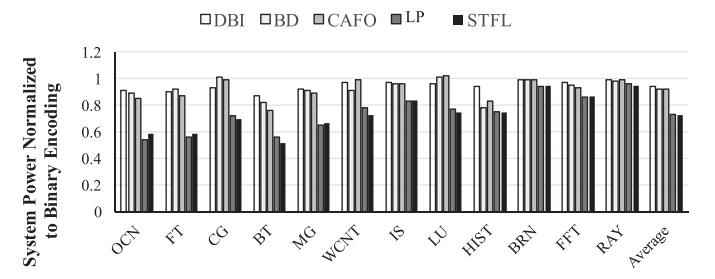
- Fig.16: 同时优化 LLC + DRAM 后,STFL 的 average system power 与 LP 非常接近。
- 但 execution time 更短,所以最终 system energy 和 EDP 都更好。
- 这说明 STFL 的价值不是“功耗更低很多”,而是在接近 LP 功耗下跑出更接近 HP 的时间。
结果 4:只改 DRAM 的性能
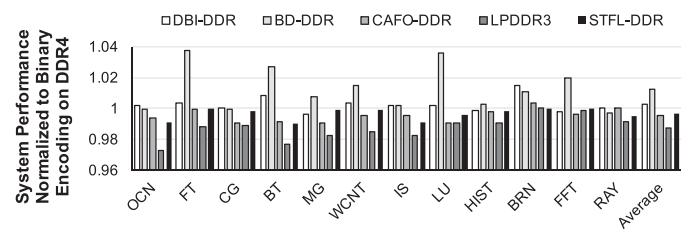
- Fig.17: 只改 DRAM I/O 时,STFL-DDR 的性能几乎追平 HP DRAM;少数应用上
BD还会快1%-4%。 - 这说明 STFL-DDR 至少没有像传统 LP 接口那样,把低功耗直接换成明显的性能下滑。
结果 5:端到端性能
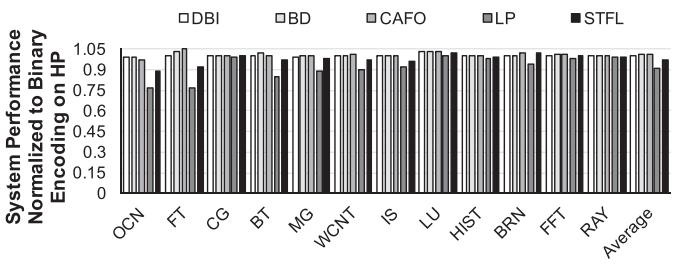
- Fig.18: 同时改 LLC + DRAM 后,STFL 相对 LP 把 end-to-end execution time 再降
7%。 - LP 会带来约
10%的时间损失,而 STFL 把这个损失压到< 2%。 - 最终,STFL 达到 HP baseline 的
98%性能。
结果 6:EDP 与带宽

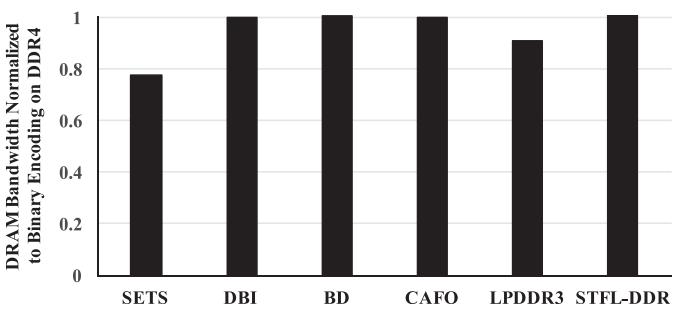
- Fig.19: STFL 把 system
EDP相对 binary encoding 在 LP/HP wires 上分别改善15% / 25%。 - Fig.22: STFL-DDR 的平均带宽基本与 DDR4 持平,而
LPDDR3 @ 800 MHz明显掉带宽。 - 这两张图一起说明: STFL 的核心价值是把 LP 的能耗优势和 HP 的带宽优势拼在同一个 operating point 上。
哪些场景更吃香
- 对 bandwidth-sensitive 的应用,STFL 相对 LP 的优势最明显,例如论文举的
BT,DRAM 带宽需求约15 GBps。 - 在
BT上,LPDDR3 虽然 DRAM energy 下降更多,但会因带宽不足拉长执行时间,增加 static energy。 - 反过来,对很多带宽压力不高的 workload,STFL 相对 LP 的 system-energy 增益就不会很大。
- 所以这个设计的 sweet spot 很明确: 需要 LP 级低功耗线,但又不能接受 LP 级带宽损失的系统。
总结
- STFL-DDR 最重要的贡献,是把 low-power signaling、transition-based coding、DDR-style clocking 做成了一个可闭环的接口设计。
- 它没有试图让低功耗线拥有更高物理 transition speed,而是通过“
1稀疏化”规避连续翻转。 - 结果上,它实现了一个很有吸引力的 operating point: 接近 LP 的功耗,接近 HP 的吞吐。
我的评价
- 最强点: 这是一个很典型的 cross-layer paper,真正把 wire physics、编码约束和 full-system evaluation 串起来了。
- 最值得怀疑的地方: “复用 LPDDR3 data wires + DDR4 clock/mode wires” 很聪明,但也让 industrial deployability 变得不那么直接。
- 缺的实验: 没有真正把
ECC、高熵数据、更新一代的 DDR speed bin 纳入实测或更严密的 sensitivity study。 - 后续方向: 做成 adaptive interface mode 会更有现实感,根据 workload 的 bandwidth demand 在 LP-like / STFL / HP-like 模式间切换。