Sectored DRAM
Sectored DRAM:一种实用的高能效高性能细粒度 DRAM 架构
Ataberk Olgun, F. Nisa Bostanci, Geraldo Francisco de Oliveira Junior, Yahya Can Tugrul, Rahul Bera, Abdullah Giray Yaglikci, Hasan Hassan, Oguz Ergin, Onur Mutlu
ETH Zurich, TOBB University of Economics and Technology
TACO 2024
Presenter: wzw
Date: 2026-03-31
三句话看懂
- 瓶颈: 处理器常常只真正使用
cache line中少数几个word,但 DRAM 仍按 整块传输 + 整行激活 工作,造成数据搬运和 activation 双重浪费。 - 方法: Sectored DRAM 用
Sectored Activation (SA)+Variable Burst Length (VBL)同时细化 activation 和 transfer,并用sectored cache + LSQ Lookahead + SP控住 sector misses。 - 结果: 对高 MPKI workload,DRAM energy 平均
-20%、性能平均+17%、system energy 平均-14%;DRAM chip area overhead 仅1.72%。
背景:今天的 DRAM
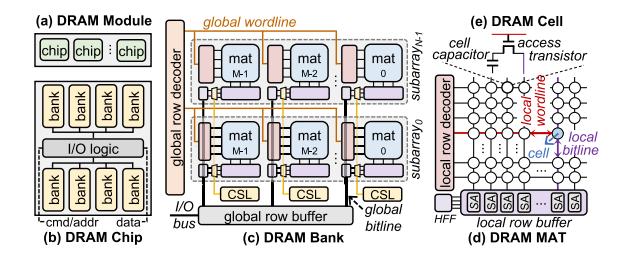
- DRAM 模块由
chips -> banks -> subarrays -> mats组成,但 memory controller 看不到 mat。 - 结果是访问一个 8B word,也往往要走 64B cache block transfer 和 整 row activation。
瓶颈:粗粒度失配
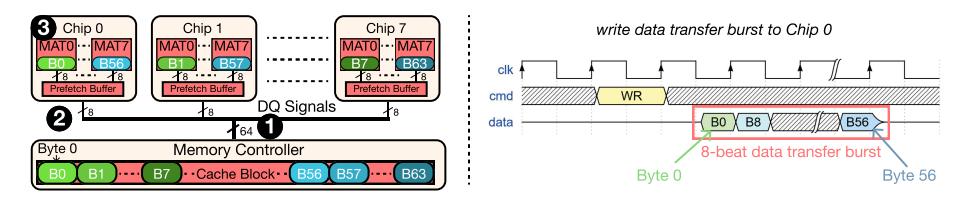
- Fig.2 说明 today 的 burst 按 beat 依次搬整块数据,即使后续只会用其中 1-2 个 words。
- 论文测得:粗粒度 transfer 的能耗是 fine-grained transfer 的
1.27×;粗粒度 activation 的能耗是 fine-grained activation 的1.04×。 - 所以真正浪费的不是某一个电路,而是 channel over-transfer + row over-activation 的叠加。
关键观察
- Observation 1: DRAM row 物理上本来就被多个
mats切开,因此 activation granularity 不一定非得是整 row。 - Observation 2: DRAM I/O 已经在用
Read FIFO / burst counter逐 beat 选择输出,因此 burst length 不一定非得固定为 8 beats。 - 核心洞察: 只要把这两个“芯片内部已有的细粒度结构”暴露给 controller,就能同时削减 activation 和 transfer 浪费,而不必重做 DRAM PHY。
总体方案
- DRAM 侧新增两件事:
SA只开需要的 sectors,VBL只传需要的 beats。 - 处理器侧新增三件事:
sectored cache跟踪部分有效 line,LSQ Lookahead合并近未来 word 请求,SP预测本 line 的 useful words。 - 整条链路的目标都是让请求携带
sector mask m,使有效 burst 长度退化成BL_eff = ||m||_1,而不是固定 8 beats。
SA:把 row 切成 sectors
- 设计上,作者给每个 sector 增加
sector latch + sector transistor + extra LWD stripe,让ACT不再默认打开所有 mats。 - controller 把 8-bit sector mask 编进
PRE的未使用编码位;后续ACT只打开 mask 选中的 sectors。 - 本质上,Sectored DRAM 把原来“4 次 full-row activation 的
tFAW预算”重新解释成 固定数量 sector activations 的预算。
VBL:burst 长度按需变
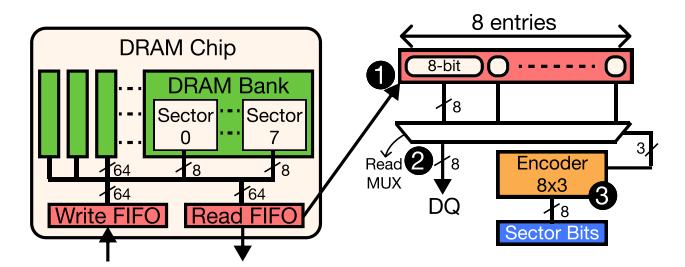
Read FIFO本来就按 beat 输出条目;VBL 只是把固定的burst counter选择逻辑改成由sector bits驱动的 encoder。- controller 和 DRAM 两侧各加一个 8-bit popcount,据此决定本次
READ/WRITE的实际 burst 长度。 - 关键收益是 只传 useful words,而不是先把整块拉上 channel 再在片上丢掉。
Cache 也要跟着变
- 如果主存能按 word 取数,cache 也必须能表示“这条 line 只有部分 words 有效”。
- 论文选择最保守的方案:每个 cache block 只额外加 8 个 valid bits,而不是把 line size 直接缩到 8B。
- 这一步很关键,因为它用很小的 metadata 成本,避免了 tag storage 爆炸,同时为后面的 sector miss 处理打基础。
LSQ + SP 控住 sector miss
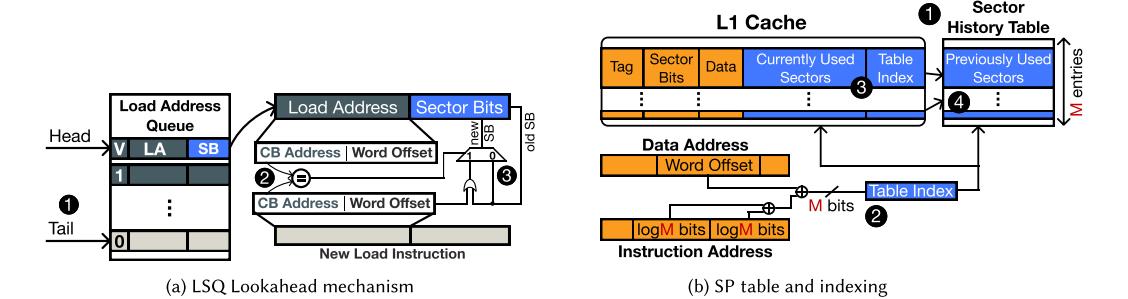
- LSQ Lookahead: 在 load/store queue 中向后看,把同一 cache block 的年轻请求合并进本次 miss。
- Sector Predictor (SP): 记录一个 static load/store 过去实际触碰过哪些 words,下次 miss 时直接把这些 sectors 一起带上。
- 没有这两步,fine-grained DRAM 会把 line miss 放大成多次 sector miss,性能会被反噬。
一次请求怎么走
- Step 1: L1 中访问某个 word,若
tag hit + sector miss,请求带上 demand sector bits 往下走。 - Step 2:
LSQ Lookahead追加近未来会用到的 sectors,SP再追加历史上常用的 sectors,形成最终 mask。 - Step 3: memory controller 用 mask 驱动
SA + VBL;DRAM 只激活相关 sectors、只返回对应 beats。 - Step 4: sectored cache 回填这些 words,减少未来重复的高延迟 DRAM accesses。
硬件账单
- DRAM chip area: Sectored DRAM 只增加
1.72%;按 bank 看,额外开销约0.39 mm²。 - Processor area: sector bits +
SP使 8-core 处理器面积增加1.22%;其中 SP 仅1088 B/core。 - 对比 prior work: HalfDRAM / HalfPage 的 chip overhead 分别是
2.6% / 5.2%,面积账单更重。 - 实现风险:
PRE编码承载 sector bits、LSQ 比较逻辑、以及更多 memory requests 对调度器的压力,都是现实落地要面对的验证点。
方法学
- Infrastructure: 修改后的
Ramulator + DRAMPower + Rambus Power Model + CACTI。 - Workloads: 共 41 个,来自
SPEC2006 + SPEC2017 + DAMOV;并按 LLC MPKI 分成High / Medium / Low三类。 - System:
1-16 cores @ 3.6GHz,32KiB L1 / 256KiB L2 / 8MiB L3,DDR4-3200,4 ranks,16 banks/rank,8 sectors/subarray。 - Default knobs:
128-entry LSQ Lookahead,512-entry SP。
证据 1:按 sector 读写更省电
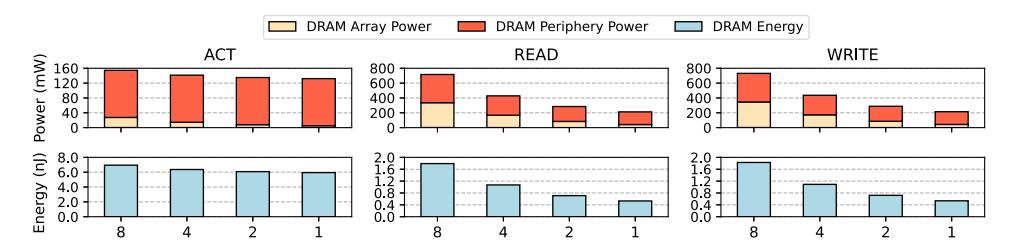
- Fig.6 看的是
ACT / READ / WRITE在 8/4/2/1 sectors 下的 power 与 energy。 - 读写一个 sector 相比读写八个 sectors,功耗分别下降
70.0%和70.6%。 - 但
ACT总功耗只下降12.7%,说明整篇 paper 的大头收益其实更多来自 reduced transfer, 不只是 reduced activation。
证据 2:系统优化不可省

- Fig.7 的纵轴是 LLC MPKI;
Basic表示只有 Sectored DRAM,没有 LSQ / SP。 - 结果非常刺眼:
Basic的 LLC MPKI 平均变成 baseline 的3.1×。 LA128-SP512把 Basic 的 LLC misses 压回-52%,说明 系统 integration 不是配菜,而是主菜。
性能:谁受益最大
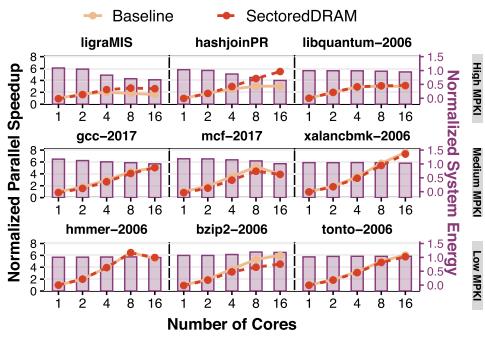
- Fig.9 的主结论:高 MPKI、多核、低 row-buffer locality 的 workload 最受益。
- 对 16-core 高 MPKI,平均 parallel speedup 为
+26%;根因是tFAW放松后能更快发出 ACT。 - 对 low/medium MPKI,额外 sector misses 会放大 memory requests;single-core 平均仍有
5.41%性能损失。
对比:性能与能效 tradeoff
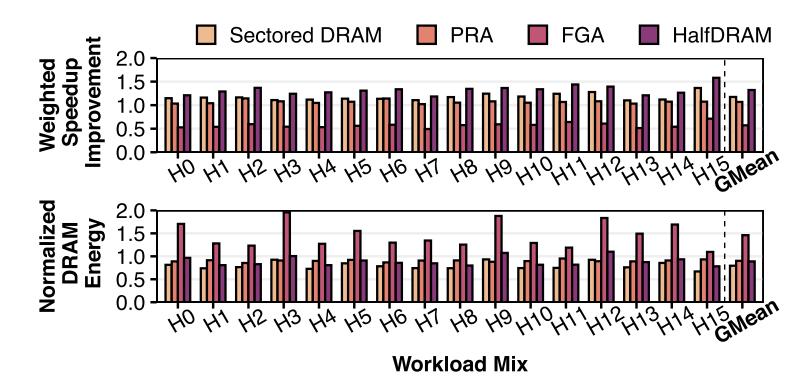
- Fig.10 上半部分看 weighted speedup,下半部分看 DRAM energy,baseline 归一化为 1。
- 对高 MPKI mixes,Sectored DRAM 达到
1.17× avg / 1.36× max;相对 FGA / PRA 的平均 speedup 是2.05× / 1.10×。 - 相比 HalfDRAM,它只有
0.89×性能,但 energy 更低12%、面积更小34%,卖点是 更平衡。
能量拆解:VBL 是大头

- Fig.11 左图做 energy breakdown,右图看系统能耗。
- VBL 让
RD/WR energy平均下降51%,并把 memory-controller 与 DRAM 间传输字节数平均减少55%。 - SA 只让
ACT energy平均下降6%;最终 system energy 的 headline 是-14% avg / -23% max。
总结
- 这篇工作最重要的贡献,不是“把 DRAM 切得更细”,而是同时把 activation granularity 和 transfer granularity 都细化。
- 真正让设计成立的不是 SA/VBL 本身,而是
sectored cache + LSQ Lookahead + SP把 fine-grained DRAM 接回现有 cache-block-based system。 - 如果只记一句话:Sectored DRAM 用很小的硬件代价,换到了高 MPKI workload 上更低的数据搬运浪费与更高的 activation 并行度。
我的评价
- 优点: 问题定义很准,也明确承认 high-MPKI 才是 sweet spot。
- 最强点: 同时解决
activation与transfer两个粗粒度问题,比只做 FGA 更完整。 - 局限: “practical” 仍停留在 architecture-level 假设,且没有 silicon 证据。
- 后续: 更强的 useful-word predictor,或把它做成可动态开关的 memory mode。