PD-Swap
Prefill-Decode Logic Swapping for End-to-End LLM Inference on Edge FPGAs
Yifan Zhang, Zhiheng Chen, Ye Qiao, Sitao Huang
University of California, Irvine
2025 preprint
Presenter: wzw
Date: 2026-03-24
TL;DR
- 核心瓶颈:
prefill是 compute-bound,decode是 memory-bound,static attention 很难兼顾两者。 - 核心创新: 用
DPR在运行时交换 attention logic,保留TLMM + weight buffering为 static。 - 核心结果: 27.8 token/s,对 TeLLMe 提升 1.11x -> 2.02x,
768-token TTFT从 11.10 s 降到 8.80 s。
背景
Prefill: 处理整段 prompt,attention 更像matrix-matrix,主要吃compute / LUT / URAM。Decode: 一次一个 token,attention 退化成vector-matrix,主要吃KV-cache DDR bandwidth。- Edge FPGA 上片上资源和 DDR 带宽都紧,这种不对称性会被进一步放大。
Static 设计的问题
- 逻辑重复: prefill/decode attention 都要常驻,buffer 和 control 被重复实例化。
- 资源挤占: attention 吃掉 LUT / URAM 后,
TLMM和 on-chip weights 更难做大。 - 长上下文退化: context 越长,decode 越快撞上 bandwidth wall。
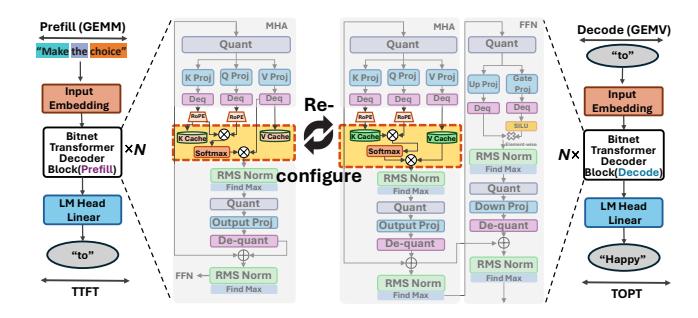
关键观察
Prefill attention的复杂度近似随序列长度 quadratic 增长。Decode attention的计算不大,但KV-cache流量随历史长度线性增长。- 真正需要 phase-specialization 的是 attention,不是共享的 linear / element-wise 逻辑。
高层架构
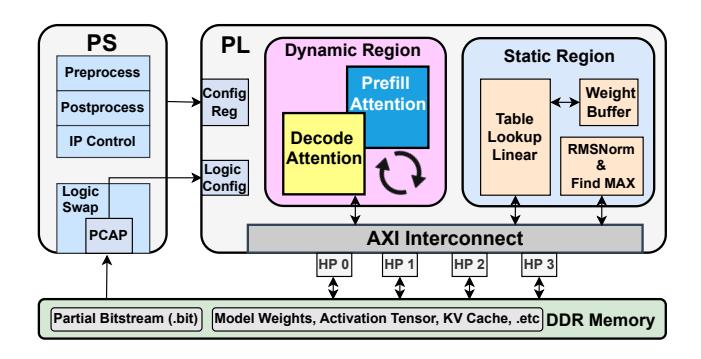
- Static region:
Table Lookup Linear,RMSNorm, 其他 element-wise operators。 - Dynamic region / RP: attention accelerator。
- 两个 RM:
Prefill RM偏 compute-heavy,Decode RM偏 KV-cache-centric。
机制 1: DPR 切换 Attention
- 设计时把 FPGA 划成
static region + reconfigurable partition (RP)。 - 运行时先加载
prefill attention RM,进入生成阶段后切到decode attention RM。 PS通过PCAP下发 partial bitstream,只重配置 dynamic region。- 收益: 同一块面积在不同时刻服务不同 bottleneck。
机制 2: 共享 TLMM
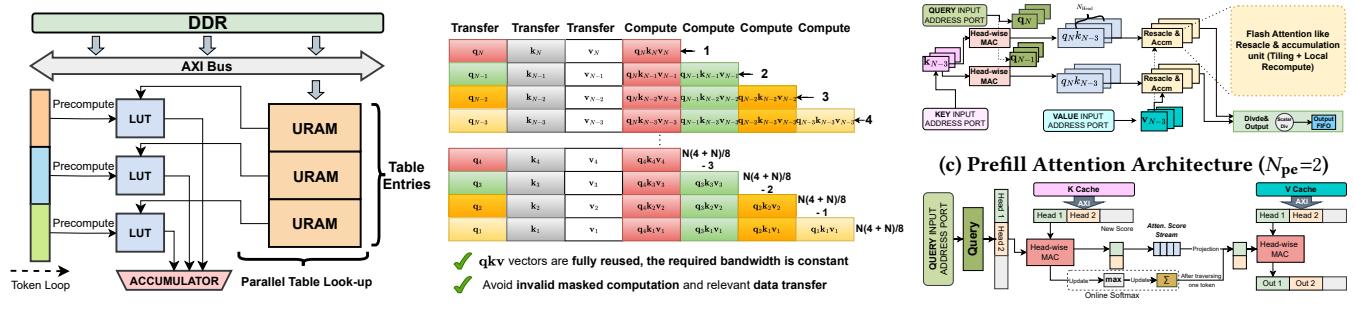
Linear projections在两个阶段都用TLMM,权重常驻片上。- 这样避免了反复 DDR weight fetch,也减少了为 dataflow 特化而重做 linear pipeline 的必要。
- 所以 swap 的边界被压缩到了 attention 子系统。
机制 3: Prefill / Decode 数据流分离
Prefill attention: 类FlashAttentionblock processing,重点是 Q reuse 和 token-level parallelism。Decode attention:L=1,没有 Q reuse,退化成面向K/V cache的 memory-bound 流程。- 论文的核心不是新 attention 算法,而是把两种数据流映射到不同硬件形态。
Request 生命周期
- Step 1: prompt 进入,static
TLMM做 projection,dynamic region 里是prefill attention RM。 - Step 2: prefill attention 通过 block-wise softmax 和 reverse scheduling 提升
Q复用。 - Step 3: 进入生成阶段前,PS 触发
partial reconfiguration,换成decode attention RM。 - Step 4: 后续 token 走
KV-cache-centricdecode 数据流,重点拉高 DDR 有效带宽。
机制 4: Decode 侧 Port 优化
- KV260 有 4 个 HP DDR ports。
- baseline 在 prefill / decode 中都沿用统一映射,decode 阶段会出现严重失衡。
- PD-Swap 改成 2 ports 给 K,2 ports 给 V。
Q直接旁路进片上 buffer,输出先本地缓存再回写。- 结果是 decode 侧的有效 KV 带宽提升接近 2x。
机制 5: Roofline 判断方向
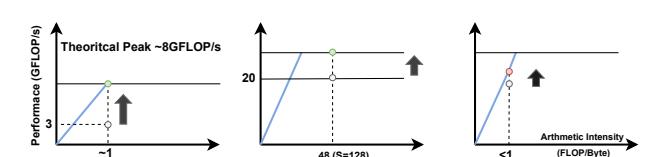
Prefill attention更像 compute-bound kernel。Decode attention更像 memory-bound kernel。- roofline 的作用是指导资源优先让给哪一侧,而不是事后解释结果。
机制 6: 自动化实现流
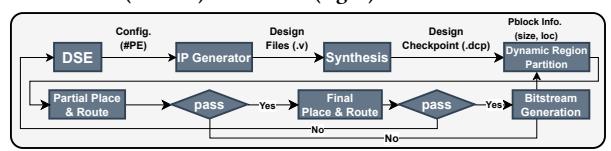
- DSE 先选
RP size / PE count / parallelism。 - 再生成参数化 HLS IP,做 module-level synthesis。
- 如果 full-system P&R 失败,就回退并降低 dynamic region 并行度。
- 重点: 性能搜索和可实现性被放进同一个闭环。
资源模型
$$r_{proj} + \max(r_{atten}^{pre}, r_{atten}^{dec}) \le R_{total}$$
- dynamic region 同一时刻只需要容纳一个 attention RM。
- 相比 static 同驻两套 attention,资源预算从“求和”变成“取最大值”。
- 这也是后面
Equivalent Total 106%成立的前提。
延迟模型
$$T_{pre} = \frac{P_{proj}L}{f_{pre}(r_{proj})} + \frac{P_{atten}L^2}{g_{pre}(r_{atten}^{pre})} + T_{weights}$$
$$T_{dec} = \frac{D_{proj}}{f_{dec}(r_{proj})} + \frac{D_{atten}L}{g_{dec}(r_{atten}^{dec})} + T_{weights}$$
prefill随L^2变坏,更该优化 compute。decode随L受带宽支配,更该优化 KV-cache access。
Runtime Overlap
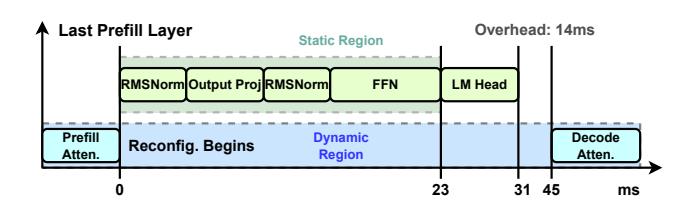
- 最后一层
prefill attention一结束,attention 模块已经可以被换出。 - 后面还有 projection + FFN 继续执行,所以 DPR 可以提前启动。
- 论文报告:
reconfiguration ≈ 45 ms, 剩余 projection + FFN≈ 31 ms @ 128 tokens, 有效重配置开销下降约 75%。
实验设置
- Device: AMD Kria
KV260 - Model:
BitNet 0.73B - Toolchain:
Vitis HLS 2024.1+Vivado 2024.1 - Baseline:
TeLLMe - 指标:
decode throughput、TTFT / prefill time、resource breakdown
核心性能
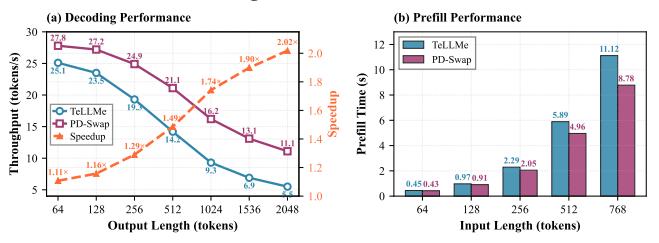
- Decode throughput: 相对 TeLLMe 的提升从 1.11x @ 64 tokens 增长到 2.02x @ 2048 tokens。
- TTFT / Prefill:
768 tokens从 11.10 s 降到 8.80 s,大约 20%-25% 改善。 2048-token时 PD-Swap 还能保持 >10 token/s,TeLLMe 约 5 token/s。
为什么长上下文收益更大
- 短上下文时,DPR 和 decode bandwidth 优势还没完全放大。
- 长上下文时,static baseline 被 KV-cache traffic 拖垮,PD-Swap 的 decode RM 更占优。
- 所以这篇工作的价值主要在 long-context decode,不是所有长度都同幅收益。
资源开销
- PD-Swap 实际资源:
102K LUT,176K FF,124.5 BRAM,62 URAM,750 DSP - 功耗: 4.9 W
- Equivalent Total: 106% LUT
- 这说明如果让两套 attention 同时常驻,设计事实上会塞不下。
能效与对比
- Decode throughput: 27.8 token/s
- Decode energy efficiency: 5.67 token/J
- 与 TeLLMe 对比:
25 -> 27.8 token/s5.2 -> 5.67 token/J - “without extra area cost” 更准确的理解是: 避免双 attention 同驻的面积爆炸,而不是完全零代价。
论文总结
- PD-Swap 把
prefill/decode asymmetry从调度问题提升成了运行时硬件形态切换问题。 - 真正被 swap 的只有 attention,shared
TLMM和线性层保持 static。 - 最终在 KV260 上做到了 27.8 token/s,且收益随 context length 增长而增大。
我的评价: 亮点
- Insight 很干净: prefill 和 decode 的 roofline 完全不同。
- 架构切分合理: shared
TLMM / projection留在 static,attention 放到 RP。 - 工程味很强: 不只讲 DPR,还补了
HP-port remapping、DSE、overlapped reconfiguration。 - 对比可信: 主 baseline 是同模型、同 FPGA 的 TeLLMe。
我的评价: 局限
- 模型规模有限: 只验证了
BitNet 0.73B。 - DPR 开销仍然存在: 短 prompt / 高频小请求场景下仍可能敏感。
- 面积表述偏乐观: 实现资源并不低于 TeLLMe。
Future Work
- 多级
context-aware reconfiguration - 更细粒度的
KV-cache hierarchy - 在更大模型和更多 FPGA 平台上验证