PCcheck
PCcheck:面向 ML 训练的持久化并发检查点
Foteini Strati, Michal Friedman, Ana Klimovic
ETH Zurich
ASPLOS 2025
Presenter: wzw
Date: 2026-03-27
TL;DR
- 瓶颈: 现有 DNN checkpointing 系统基本都只允许 一个 in-flight checkpoint,高频 checkpoint 时训练会被前一次持久化拖住。
- 方法: PCcheck 用 multiple concurrent checkpoints + GPU->DRAM->SSD/PMEM pipeline + multi-thread persistence,把 snapshot 与持久化解耦。
- 结果: 能把 checkpoint 频率推到 每
10iterations 仍仅约3%overhead,在 spot-VM preemption trace 下 goodput 最多高2.86x。
为什么这事重要
- 大模型训练动辄跑 数天到数周,硬件规模越大,failure / preemption 概率越高。
- 文中引用的生产统计很激进: 50% 的 ML jobs 在 16 分钟 内遇到 failure;另一个多租户 GPU 集群的 mean time between failures 约 45 分钟。
- spot VM 又把问题放大了: 成本虽可低
60%~90%,但云上会频繁 preempt;作者引用的 64-GPU cluster 在 24 小时内可遇到 127 次 preemption。 - 所以真正的问题不是“要不要 checkpoint”,而是 能否把 checkpoint 做到足够频繁且不明显拖慢训练。
旧方案卡在哪里
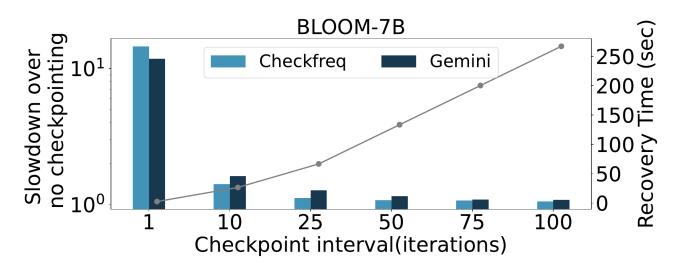
- Figure 1 的信号很直接: 对 BLOOM-7B,CheckFreq / Gemini 在
<=50iterations checkpoint 时仍有>10%overhead。 - 根因不是没有 overlap,而是它们都只有 single active checkpoint: 下一次 snapshot 必须等前一次 persist 结束。
- 这意味着 checkpoint 越频繁,GPU 越容易在“等前一个 checkpoint 落盘”上空转。
关键观察
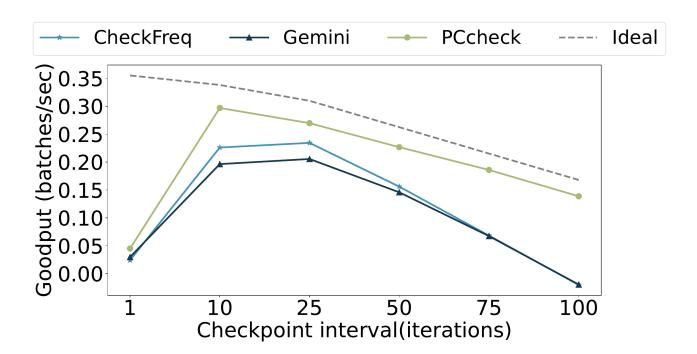
- 真正目标函数不是裸 throughput,而是 goodput = 有效训练进度 / 总时间。
- checkpoint 太稀会多做 rollback,checkpoint 太密又会把训练时间吃掉。
- Figure 2 说明 sweet spot 恰恰落在
10~25iterations,所以系统必须支持 fine-grained checkpointing。
PCcheck 全景图
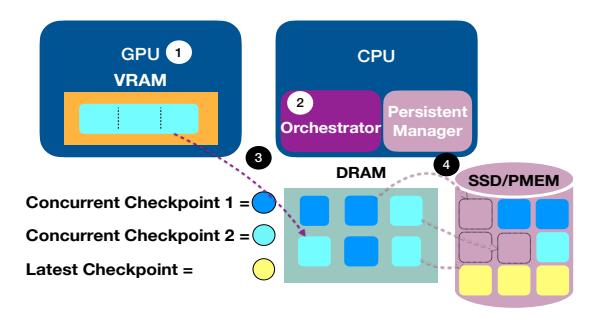
- Orchestrator: 决定何时发起 checkpoint,分配 DRAM buffer,并触发 GPU copy engines。
- Persistent Manager: 管理 mmaped checkpoint 空间,用多个 writer threads 把 DRAM 数据写到 SSD / PMEM。
- 核心变化: 不再把“下一次 checkpoint 开始”绑定到“上一次 checkpoint 完全持久化结束”。
一次 checkpoint 如何流动
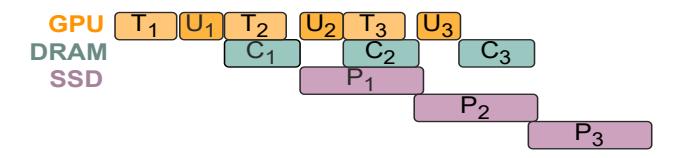
U1后,GPU 立即把 state 拷到 DRAM 形成C1,训练 meanwhile 继续跑T2。- 当第二次 checkpoint 到来时,即使
P1还没完成,PCcheck 也允许C2继续开始。 - 核心变化就是: checkpoint 之间并发,而不是串行排队;但作者也承认 update 阶段仍可能留下小 stall。
机制1:再加 pipeline
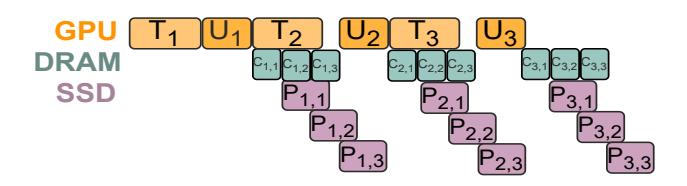
- PCcheck 不只是允许多个 checkpoint 并发,还把每个 checkpoint 切成 chunks。
- 于是可以在
chunk i已经开始持久化时,继续从 GPU 拷chunk i+1。 - chunk 已经落盘后,其 DRAM buffer 还能被后续 checkpoint 复用,因此 host memory 不必线性膨胀。
如何选频率
- tuning rule:
$f \ge \frac{T_w}{N \cdot q \cdot t}$ T_w: 最坏写入时间;N: 并发度;q: slowdown 预算;t: iteration time。
资源账单怎么付
| 方案 | GPU Mem | DRAM | Storage |
|---|---|---|---|
| CheckFreq | m |
m |
2m |
| GPM | m |
0 |
2m |
| Gemini | m+buffer |
m |
0 |
| PCcheck | m |
m~2m |
(N+1)m |
- PCcheck 的本质 tradeoff 很坦白: 用更多 DRAM / persistent space,换更少训练 stall。
- 数据路径上作者做了很务实的优化:
GPU copy engine + pinned memory + DDIO,PMEM 侧用non-temporal store + sfence。 - 元数据侧则用
CHECK_ADDR + counter + CAS保证: 任何时刻至少有一个合法 checkpoint。 - 这也解释了为什么它不是“纯软件调度小技巧”,而是 host memory / I/O path aware 的系统设计。
方法学
- SSD 平台: Google Cloud
a2-highgpu-1g,A100-40GB + PCIe3x16 + 85GB DRAM + 1TB SSD。 - PMEM 平台:
Titan RTX-24GB + Intel Optane PMEM,两机型分别评估 SSD / PMEM 场景。 - 模型:
VGG16, TransformerXL, BERT, OPT-1.3B, OPT-2.7B, BLOOM-7B,checkpoint 大小从1.1GB到108GB。 - Baselines:
CheckFreq,GPM,Gemini,其中 Gemini 由作者按论文描述自行实现。 - 评价指标: throughput、recovery time、goodput、microbenchmark、sensitivity study。
主结果:单 GPU
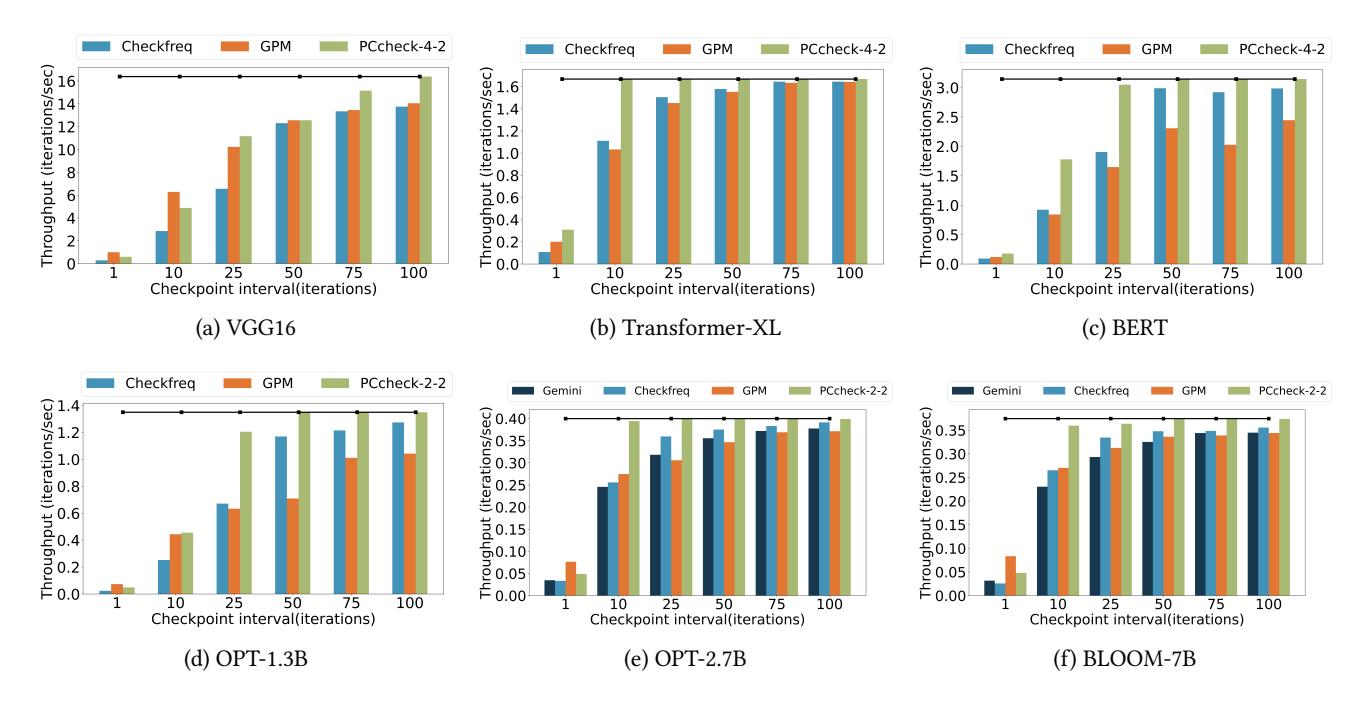
- 单 GPU 下,CheckFreq 在 VGG16 上 checkpoint every iteration 时最坏可到
57xslowdown。 - 对
OPT-1.3B,every50iterations 时,PCcheck 为1.02x,而 GPM / CheckFreq 约1.9x / 1.17x。
主结果:分布式
- 多 GPU 下,Gemini 的思路是把 state 发到远端机器内存,但它同样只有 single active checkpoint。
- 作者在
a2-highgpu-1g上测得 inter-machine bandwidth 约15 Gbps,不足以把网络 copy 完全藏进训练过程。 - 对
OPT-2.7B/BLOOM-7B,Gemini slowdown 为1.62x~1.06x/1.65x~1.08x,而 PCcheck 压到<1.05x/<1.02x。
真正该看:recovery 与 goodput
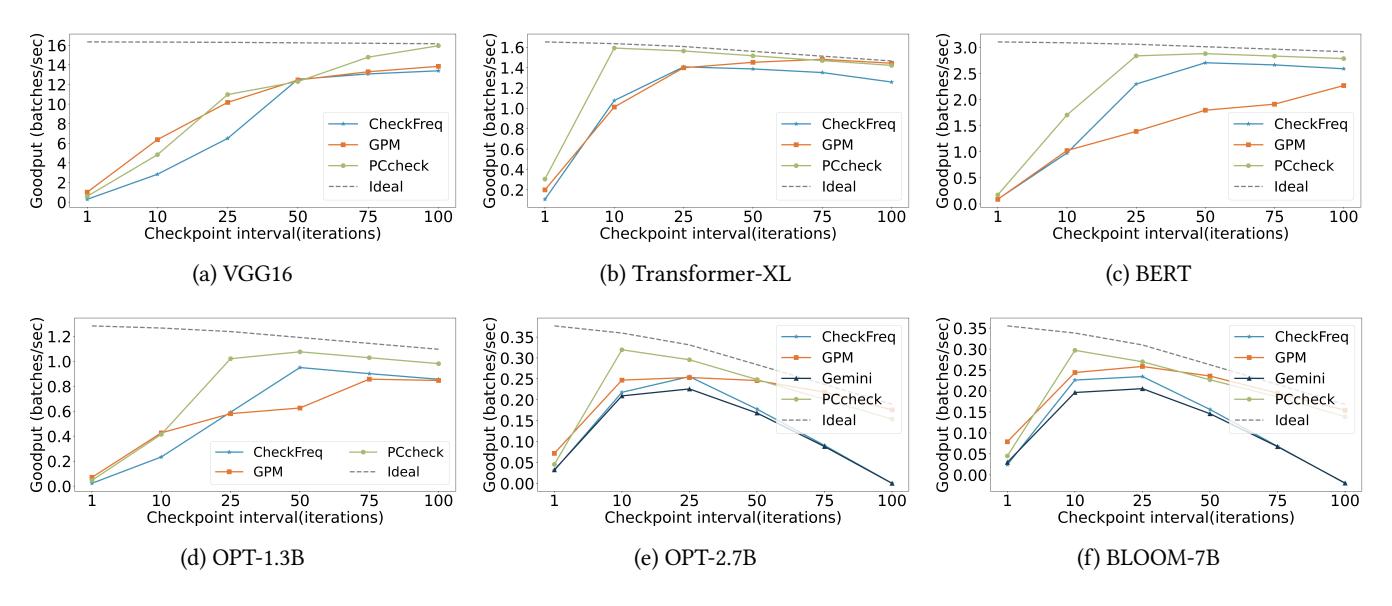
- Spot trace 下,最佳 checkpoint interval 落在
10~25iterations,这正是 prior systems 最难承受的频段。 OPT-1.3B的例子里,every10iterations 时 PCcheck 的 goodput 比 CheckFreq 高1.77x。- 看所有频点,PCcheck 对
GPM / CheckFreq / Gemini的 goodput 最多分别高1.75x / 2.86x / 2.75x,说明 rollback 增量仍小于吞吐收益。
次级结果:PMEM 也成立
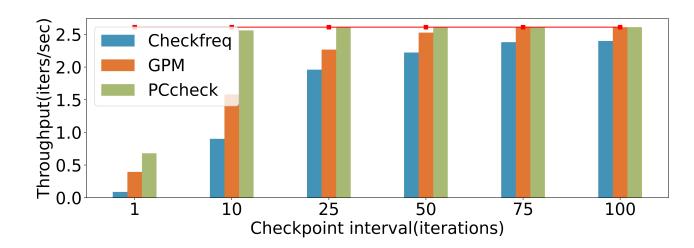
- PMEM 带宽更高,因此所有方案都比 SSD 轻松,但 PCcheck 仍始终最好。
- 对 BERT,在相同 overhead 下,PCcheck 可把 interval 从
100压到10iterations,recovery time 相应降10x。 - microbenchmark 里,PCcheck 的 per-checkpoint time 相对 CheckFreq / GPM 最多快
1.9x。
敏感性:并发度不用很大
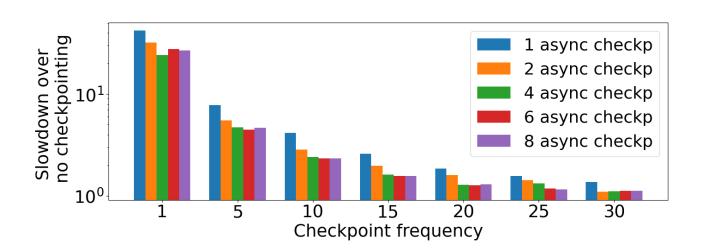
- Figure 12 表明对 VGG16,多个 concurrent checkpoints 明显优于单 checkpoint。
- 但作者也发现
2~4个通常就够了,再多会开始撞上 SSD bandwidth saturation。 - 这很关键: PCcheck 的收益不是靠“无限堆并发”,而是靠 适度并发 + 正确的数据路径设计。
结论
- PCcheck 抓住的根因很准: 高 checkpoint overhead 的本质是 single in-flight checkpoint 导致的串行阻塞。
- 它的核心贡献是把 checkpoint 变成 可并发、可 pipeline、可 tuning 的系统路径,而不是一个简单 async save API。
- 在 failure-heavy 的现实环境里,paper 真正改善的是 goodput 与 recovery behavior,而不只是实验室里的裸 throughput。
我的评价
- 最强点: 论文没有只讲“更快写盘”,而是把 吞吐、恢复时间、goodput、配置规则、系统实现 连成闭环。
- 主要局限: 分布式一致性机制仍比较轻量,作者自己也承认还在继续增强其 robustness;Gemini baseline 也是作者自行复现,公平性有一点风险。
- 工程边界: PCcheck 用空间换时间,
(N+1)m的 storage footprint 对108GBcheckpoint 级别的模型并不便宜。 - 后续方向: 一个自然延伸是把 profiling-based tuning 做成 online controller,再和 preemption prediction / cluster scheduler 联动。