Nazar
Nazar:监控并自适应移动设备上的 ML 模型
Wei Hao, Zixi Wang, Lauren Hong, Lingxiao Li, Nader Karayanni, AnMei Dasbach-Prisk, Chengzhi Mao, Junfeng Yang, Asaf Cidon
Columbia University, UC San Diego
ASPLOS 2025
Presenter: wzw
Date: 2026-03-27
TL;DR
- 问题: 移动端模型部署后几乎拿不到标签, 但精度会因
weather / location / device等 drift 悄悄下降。 - 方法: Nazar 用 轻量 MSP detector + 云端 root-cause mining + by-cause adaptation 做自动闭环。
- 结果: 在
Cityscapes上, 相比adapt-all平均精度最高多19.4%, drifted data 最高多49.5%。
为什么这题重要
- 越来越多 inference 跑在手机本地: latency 低, 可离线, 也更省云端成本。
- 但 deployment 后最难的是 visibility: 没有真实标签, ML ops 不知道模型什么时候坏了。
- 更糟的是 drift 往往 不是单一来源: 雨天、雪天、地点变化、设备摄像头差异会叠加。
- 如果直接对所有新数据做
adapt-all, 不同分布会相互污染, 适配反而可能变差。
旧方案卡在哪里
- 纯 detector: 只能告诉你“可能 drift 了”, 但不知道是哪类设备 / 环境导致。
- 纯 adaptation: 多数方法默认只有一个 drift source, 直接在全部输入上自适应。
- 真正缺的: 一个把
detect -> diagnose -> adapt -> redeploy串起来的系统闭环。 - 论文的核心判断很准: 精度下降通常有共享 root cause, 应该按根因而不是按全量数据适配。
关键观察
- 单条 inference 上的 drift signal 很 noisy, 但群体层面的 metadata pattern 往往稳定。
- 如果把
{location, weather, device id, time, model version}聚合成drift log, 就能在云端寻找高风险 attribute set。 - 所以设备端 detector 不必极强, 只要 足够轻且能持续产生日志 即可。
- 真正的智能在后端: 把 noisy per-sample signal 提升成 actionable root cause。
Nazar 总体结构
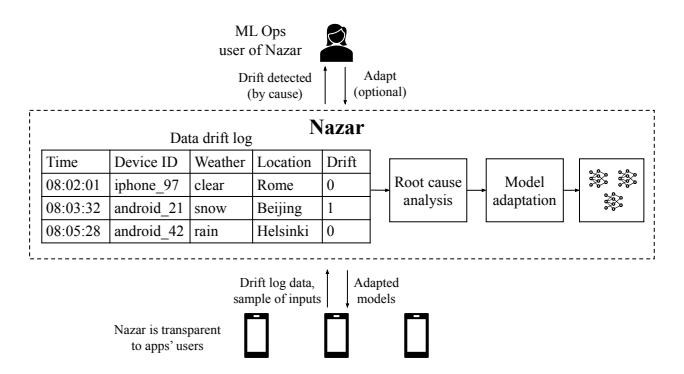
- 设备端: 推理后运行极轻量 drift detector, 并上报 metadata + 少量采样输入。
- 云端: 在 drift log 上做 root-cause analysis, 对每个 root cause 单独触发 adaptation。
- 回到设备: 下发多个小型 adapted 版本, 按 metadata 选择最匹配的模型推理。
机制1:设备端检测
- Nazar 最终选择 MSP threshold 而不是 KS-test / Odin / Mahalanobis / 辅助模型。
- 这个选择的关键是 足够轻: 不需要 secondary dataset / model, 也不需要 backprop。
- 它还能按 单条 inference 判定 drift, 不强依赖 batch。
- 默认阈值取
0.9, 因为在 Animals 数据上其F1在该区域最稳, 峰值约0.73。
机制2:根因分析

- 先在 drift log 上做 Frequent Itemset Mining (FIM), 找与 drift 高频共现的 attribute sets。
- 再做 Set Reduction: 去掉被更高 rank 超集覆盖的子集根因。
- 再做 Counterfactual Analysis: 扣掉高 rank 根因已解释的样本, 看低 rank 候选是否仍显著。
根因分析为什么关键
- 纯 FIM 会给出很多重叠候选, 例如
{snow},{snow, New York},{New York}。 - 如果逐个适配, 会带来模型版本爆炸、样本被重复解释、设备端路由更混乱。
- Nazar 的目标不是“列出所有可能原因”, 而是 压缩成少量、可自动适配的 coarse-grained causes。
机制3:按根因适配
- adaptation 默认用 TENT:
L(\theta; x) = -\sum_c p_{\theta}(\hat{y}_c|x)\log p_{\theta}(\hat{y}_c|x)。 - 真正关键不是公式, 而是 只在同一 root cause 的数据子集上适配。
为什么只改 BN
- Nazar 不更新整模型, 而是只更新 BN layers。
- 对
ResNet50,BN = 0.4MB, full model= 92MB, 小约217x。 - 这样多 root-cause 版本才有机会在设备端共存, 不会把存储直接打爆。
一次请求如何流动
- 设备端用当前模型推理, 读取
MSP判断本条输入是否疑似 drift。 - 设备上报
drift bit + metadata, 并抽样上传少量原始输入到云端。 - 云端周期性运行
FIM -> set reduction -> counterfactual, 找出显著 root causes。 - 对每个根因单独做 adaptation, 生成多个小型 BN 版本后重新下发。
- 设备端推理时选择 属性匹配数最多 的模型版本; 若无匹配则回退到 clean model。
部署开销怎么付
| 开销项 | Nazar 的做法 | 代价 |
|---|---|---|
| 设备端计算 | MSP threshold | 很轻 |
| 上传流量 | metadata + sampled inputs | 有隐私 / 带宽成本 |
| 模型存储 | 多个 BN versions | 远小于全模型多版本 |
| 云端分析 | Aurora + Lambda | 分析快 |
| 适配时延 | GPU instance 跑 adaptation | 总体偏慢 |
- 论文报告: root-cause analysis 仅
46s, 但完整 adaptation 闭环平均50 min。 - 所以 Nazar 的真正瓶颈不是分析逻辑, 而是 模型更新速度。
方法学
- 数据集:
Cityscapes自驾车场景,Animals物种识别场景。 - 模型:
ResNet18 / 34 / 50。 - drift: 共
16种 corruption; 端到端主要用rain / snow / fog; 还评估了 class skew。 - Baselines:
adapt-all和no-adapt。
检测与根因定位
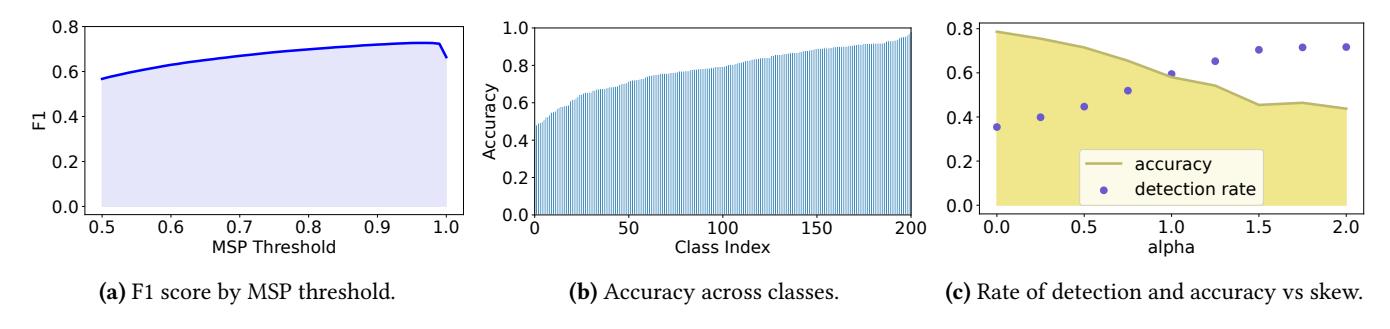
MSPdetector 在 Animals 上峰值F1 = 0.73, 在阈值0.9左右较稳定。- 真实雨天数据上峰值
F1 = 0.67,precision = 0.55,recall = 0.88。 - Snow 场景中,
FIM的FMS = 0.773, 加Set Reduction + CF后提升到0.874。
按根因适配真的更强
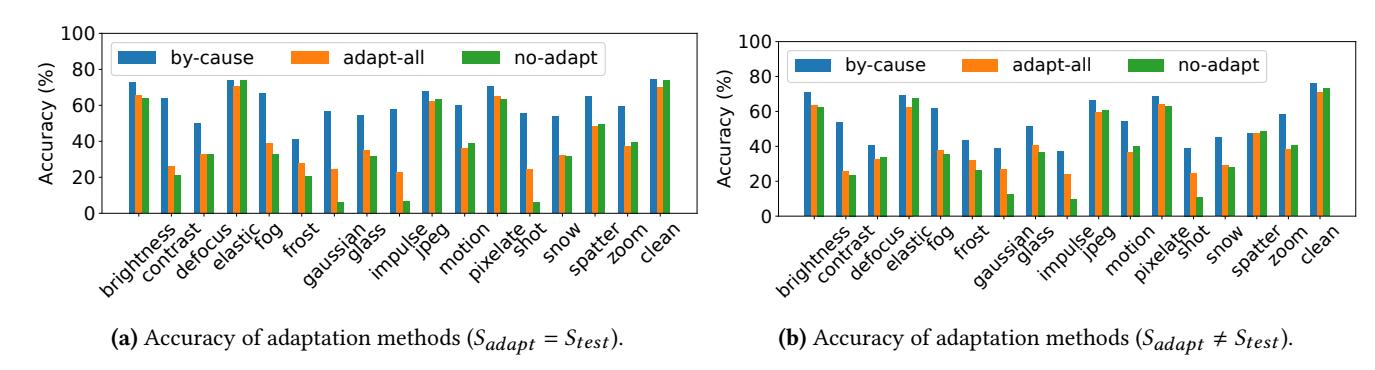
- 相同 severity 下,
By-cause (TENT)=61.5%, 显著高于Adapt-all的42.4%和No-adapt的38.7%。 - severity mismatch 时,
By-cause仍有54.3%, 仍显著强于42.0%。 - 结论很清楚: 适配边界必须和分布边界对齐。
端到端效果

- 在
Cityscapes上, Nazar 对 全部数据 的平均精度相对adapt-all提升10.1%~19.4%。 - 只看 drifted data, 提升更大:
ResNet18上最高49.5%,ResNet34上37.6%。 - 如果只用 FIM 不做去冗余, 平均精度会下降
1.3%~9.7%, 且设备端模型版本数更高。
次级结果与弱点

- drift 越重, Nazar 相比
adapt-all的优势越大, 最多3.8%~10.4%。 - 适配后 detector 会“再校准”, 不会持续把同一类已修复 drift 重复报出来。
- 但
class skew严重时 Nazar 可能不如adapt-all: 它擅长 metadata-visible drift, 不擅长所有 latent drift。
结论
- Nazar 的核心贡献不是更强的 detector, 而是 把 noisy detection 转成可执行 root causes。
- 论文最重要的系统 insight 是: 移动端 drift 往往有共享根因, 应该按根因而不是按全量输入适配。
- 在可见 metadata 驱动的 drift 上, 这套闭环相比
adapt-all确实更稳、更准、也更省模型版本。
我的评价
- 优点: 问题定义很准,
detect -> diagnose -> adapt的系统闭环完整, 结果也确实支持 by-cause 设计。 - 主要假设: drift log 必须覆盖真正 root cause; 若真实原因是未记录的 latent factor, 系统只能学到 proxy。
- 最大的工程问题: 设备抽样上传原始输入的隐私 / 带宽成本没有被认真量化,
50 minadaptation latency 也偏长。 - 后续方向: 可做
cost-aware triggering, 或把 hard routing 扩展成 mixture-of-adapters / soft selection。