MoE-Lightning
MoE-Lightning:显存受限 GPU 上的高吞吐 MoE 推理
Shiyi Cao, Shu Liu, Tyler Griggs, Peter Schafhalter, Xiaoxuan Liu, Ying Sheng, Joseph E. Gonzalez, Matei Zaharia, Ion Stoica
UC Berkeley, Stanford
ASPLOS 2025
Presenter: wzw
Date: 2026-03-27
TL;DR
- 瓶颈: MoE 的 active FLOPs 不高, 但 weights + KV cache 极大,
T4/L4这类 GPU 很容易被CPU-GPU I/O卡死。 - 方法: MoE-Lightning 用 CGOPipe 重叠
GPU compute + CPU attention + paged weight transfer, 再用 HRM 搜最优(N, \mu, A_g, F_g, r_w, r_c)。 - 结果:
Mixtral 8x7B @ 1xT4最多10.3x吞吐提升,1xL4上MTBench@64达到294.5 tok/s。
背景:为什么是 MoE
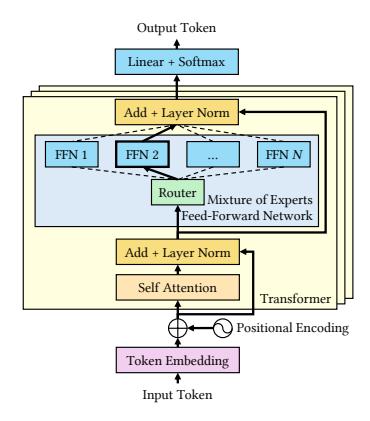
- MoE 每个 token 只激活少量 experts, 算力成本接近 dense, 但 参数总量大很多。
- 对 batch inference 来说, 最大问题不是 compute 不够, 而是 模型放不进 GPU memory。
- 论文关注的是 offline / throughput-oriented 场景, 不是在线 TTFT 优化。
旧方案为什么慢
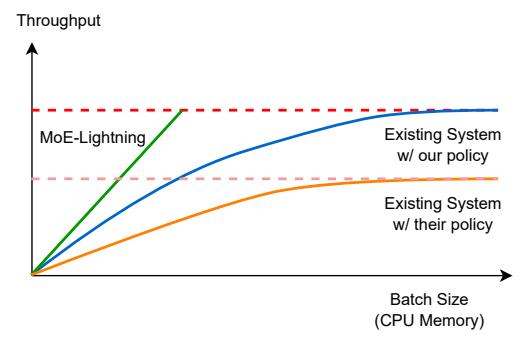
- 旧 offloading 系统主要做
layer-by-layer streaming, 但 没有把 compute 和 I/O 真正 overlap。 - 为了摊薄权重搬运成本, 它们往往需要更大的 batch, 结果 CPU memory 被 KV cache 吃爆。
- 论文的目标很明确: 用更少 CPU memory 达到同等或更高 throughput。
观察1:Attention 该在 CPU
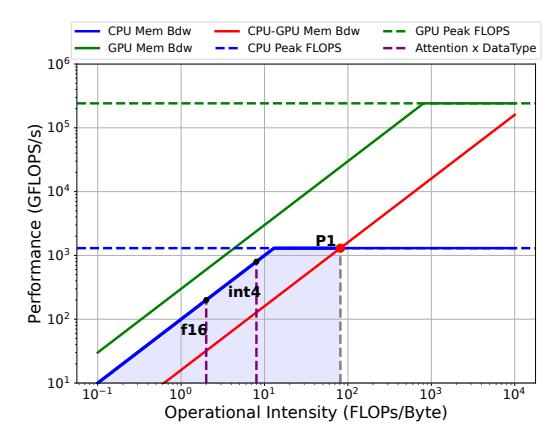
- 对 decode 阶段 attention, operational intensity 很低,
f16 / int4都落在P1左侧。 - 这意味着把 KV 从 CPU 再搬回 GPU 计算, 往往不如 直接在 CPU 上做 attention。
- 关键不是 CPU 更强, 而是 CPU-GPU bandwidth 太贵, attention 又太 memory-bound。
观察2:FFN 该在 GPU
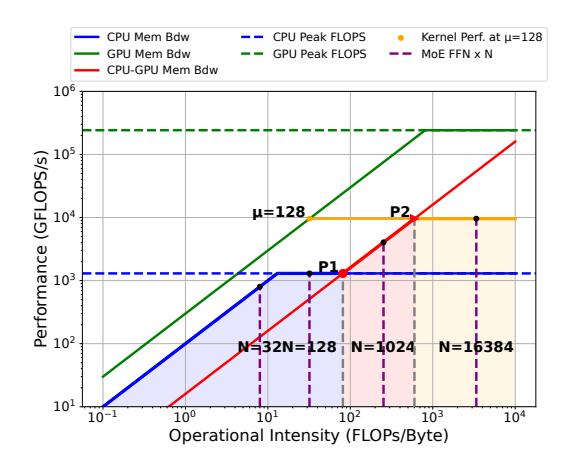
- MoE FFN 的 operational intensity 会随 batch size / micro-batch size 提升而增大。
- 当
N足够大时, FFN 能跨过P1甚至逼近P2, 这时更适合放在 GPU。 - 所以最优策略不是 “all CPU” 或 “all GPU”, 而是 CPU attention + GPU FFN。
系统总览:CGOPipe
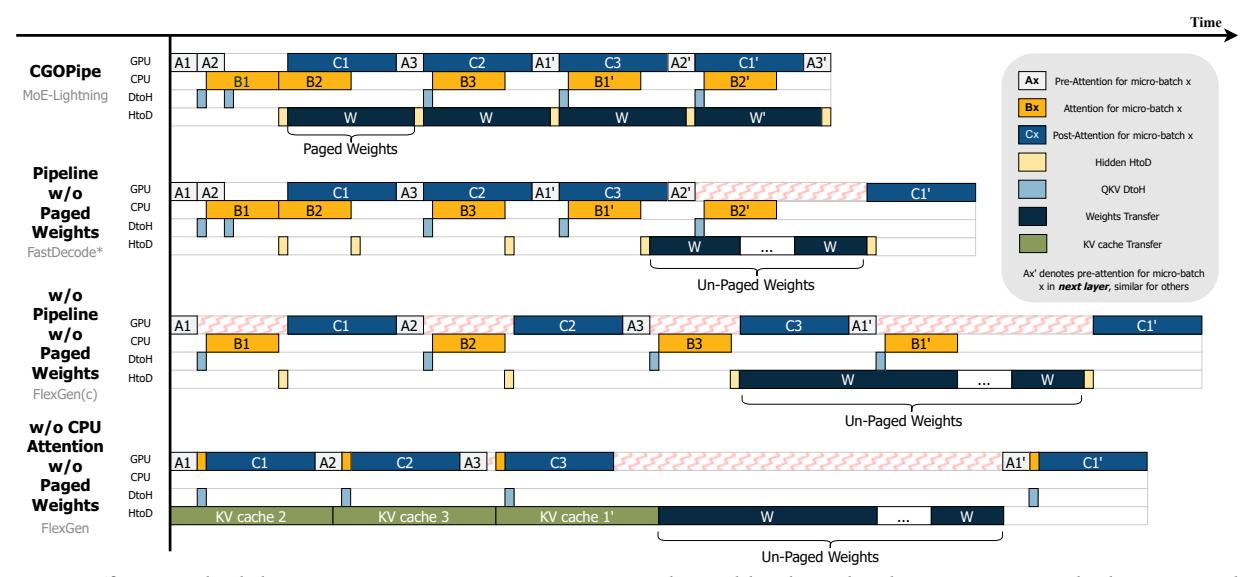
- GPU 负责
PreAttn + PostAttn + MoE FFN, CPU 负责Attention, I/O 负责QKV / hidden / weights三类传输。 CGOPipe的核心是 把下一层 weights 分页, 穿插到当前层 micro-batch 的执行间隙中。- 对比 FlexGen/FastDecode, 它显著减少 GPU idle bubbles。
机制1:Paged Weights
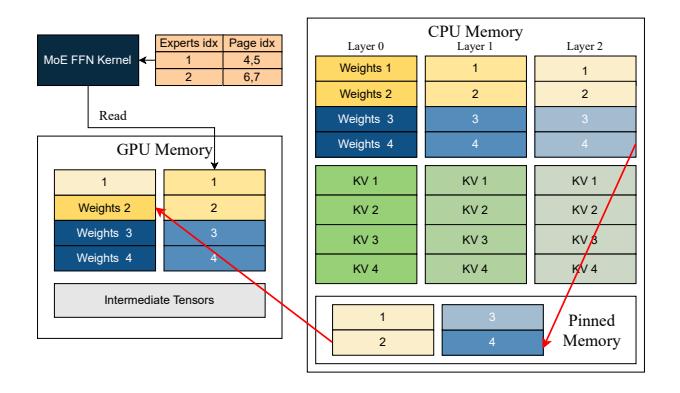
- GPU 上只保留当前需要的 weight pages, 其余权重常驻 CPU memory。
- 论文显式分配
2 x size(W_L)的 weight buffer, 让 当前层使用 与 下一层预取 并行。 - 路径是
CPU memory -> pinned memory -> GPU, 并用 page table 让 MoE FFN kernel 按页取数。
机制2:HRM
$$ P_x^i=\min(P_i^{\text{peak}},\ B_i^{\text{peak}} I_x^i,\ B_{j,i}^{\text{peak}} I_x^j) $$
- 三重上界: 算力 / 本地带宽 / CPU-GPU 带宽。
搜索什么策略
- 每层 latency 近似为:
T = max(comm_cpu->gpu, T_cpu, T_gpu) - policy 六元组:
(N, mu, A_g, F_g, r_w, r_c) A_g / F_g决定 attention 和 FFN 放在哪个设备执行。- 主要实验里最优解几乎总是:
A_g = 0, F_g = 1
一次 decode 怎么走
- GPU 对当前 micro-batch 做
PreAttn, 生成QKV。 QKV DtoH, CPU 直接执行 attention; 同时把上一批 hiddenHtoD回传 GPU。- GPU 执行
PostAttn + MoE FFN, 而下一层 weights 已经按 page 提前搬运。 - 只要让
comm,T_cpu,T_gpu三者接近, 就能把整层 latency 压到更高的 balance point。
资源账单
- 不是新硬件: 这是一个系统 / runtime 设计, 代价主要是 CPU memory、pinned memory、调度复杂度。
- 内存代价: 需要容纳整模型权重的 CPU DRAM, 论文主设定里是
192GB或416GB。 - 软件代价: 需要自定义 CPU GQA kernel、paged weight management、异步依赖编排。
- 优化器代价: policy 可离线用
MILP求解, Appendix 说< 1 min。 - 边界: 论文明确 不考虑 disk offloading, 所以前提是 “GPU 不够, 但 CPU 够”。
方法学
- 模型:
Mixtral 8x7B,Mixtral 8x22B,DBRX (132B, 16 experts)。 - 硬件:
1xT4(16GB),1xL4(24GB),2xT4,4xT4; CPU 为24/32-core Xeon。 - 负载:
MTBench,HELM Synthetic Reasoning,HELM Summarization。 - 基线:
FlexGen,FlexGen(c),DeepSpeed Zero-Inference。 - 指标: generation throughput =
generated tokens / (prefill + decode)。
主结果:吞吐大幅提升
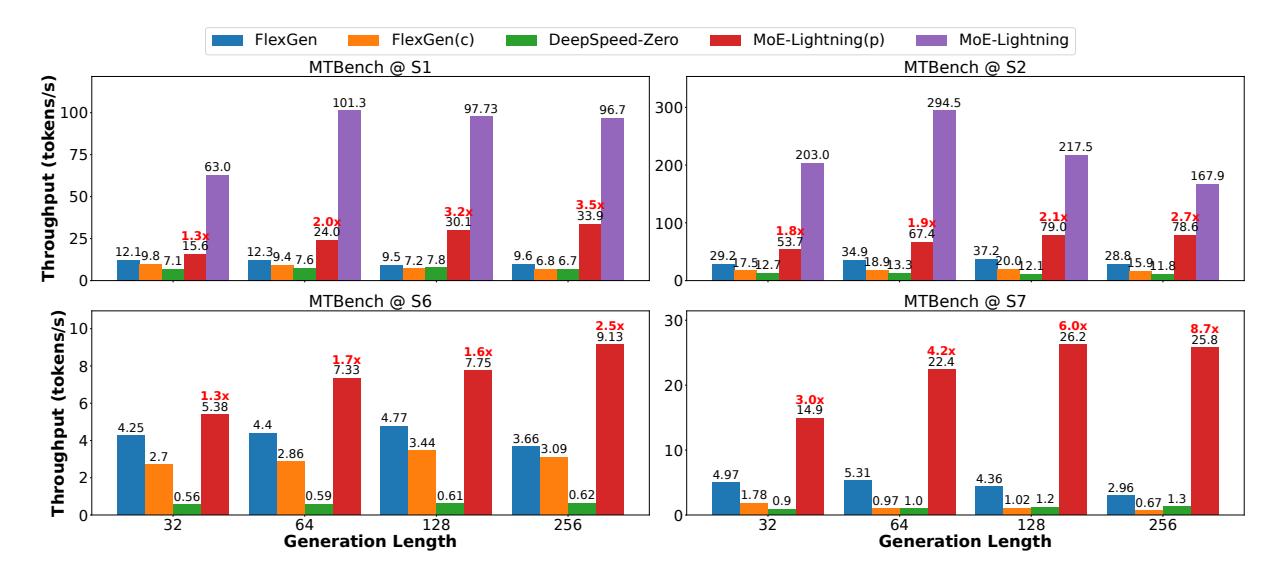
1xT4上MTBench@256,MoE-Lightning(p)达到33.9 tok/s, 相对 FlexGen3.5x。1xL4上MTBench@64,MoE-Lightning达到294.5 tok/s, 远高于 FlexGen34.9 tok/s。- 单卡 headline 是 最多
10.3x提升, 说明它真正打中了 memory-constrained regime。
多卡为何超线性
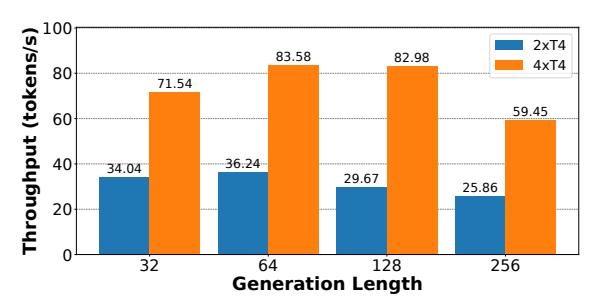
- MoE-Lightning 选 tensor parallelism, 不是 FlexGen 的 pipeline parallelism。
- 对这类 workload, 上界经常由 total GPU memory capacity 决定, 多卡直接抬高可行 batch。
DBRX上从2xT4 -> 4xT4, throughput 提升达到2.1x ~ 2.8x, 呈现近似超线性扩展。
消融:CPU Attention 值不值
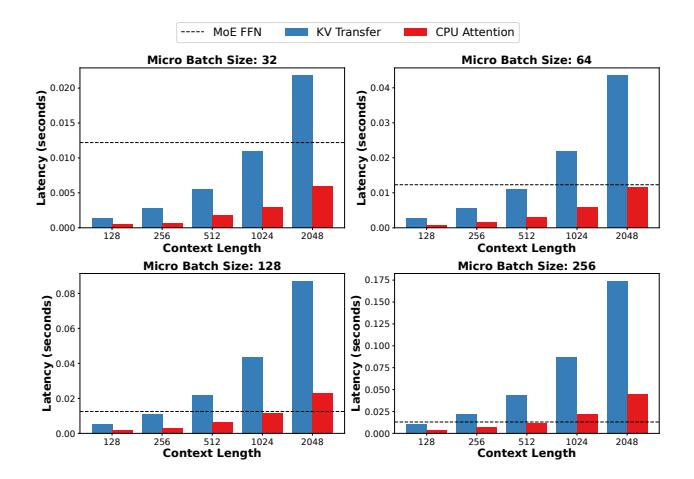
- 蓝柱是
KV transfer, 红柱是CPU attention, 虚线是MoE FFN。 - 在大部分
context length / micro-batch组合下, CPU attention 明显快于 KV 搬回 GPU。 - 但当
\mu和 context 持续增大时,CPU attention也会变成新瓶颈, 所以这不是永远成立的结论。
结论
- 贡献1: 用 HRM 解释并搜索异构
CPU-GPUMoE 推理的最优执行区间。 - 贡献2: 用 CGOPipe + paged weights 把 compute 与 I/O overlap 做满, 显著减少 GPU bubble。
- 贡献3: 在
T4/L4级别低成本硬件上, 把Mixtral / DBRX的 batch inference 吞吐大幅拉高。
我的评价
- 优点: 问题定义非常准,
model too big for GPU but fits in CPU这个场景被吃得很透。 - 最强 insight: 真正该优化的是
max(comm, T_cpu, T_gpu), 不是某个单独 kernel 的 micro-opt。 - 脆弱假设: 结论高度依赖 offline batch inference, 且默认 CPU memory 足够、磁盘不参与。
- 缺失实验: 没有真正覆盖更近的 MoE serving baselines, 对在线 serving 的 tail latency 也几乎没回答。
- 后续方向: 把
HRM扩展到GPU-GPU / multi-node通信, 或纳入KV sparsity / speculative decoding。