LUT Tensor Core
LUT Tensor Core:面向低比特 LLM 的查表张量核
Zhiwen Mo, Lei Wang, Jianyu Wei, Zhichen Zeng, Shijie Cao, Lingxiao Ma, Naifeng Jing, Ting Cao, Jilong Xue, Fan Yang, Mao Yang
Imperial College London, Microsoft Research, Peking University, USTC, University of Washington, SJTU
ISCA 2025
Presenter: wzw
Date: 2026-03-25
三句话看懂
- 瓶颈:
weight-only LLM的主算子已变成mpGEMM,但现有 GPU/TPU 不原生支持,只能走dequantize + GEMM。 - 方法: LUT Tensor Core 用
DFG transformation + operator fusion + weight reinterpretation + elongated tiling + LMMA,把 mpGEMM 变成可高复用的查表张量核。 - 结果: 相比现有 LUT 软件方案,最高
1.42× GEMV、72.2× GEMM;端到端在 low-bit LLM 上达2.06× ~ 5.51×推理加速。
背景:mpGEMM 成了主角
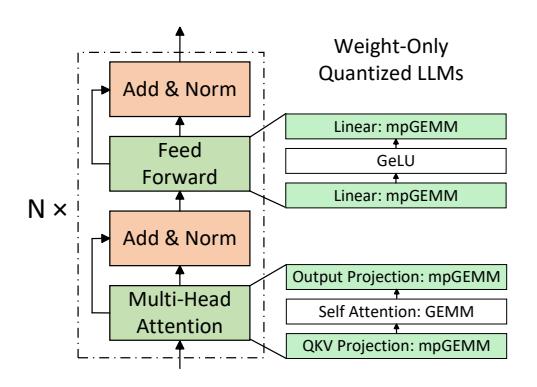
weight-only quantization下,QKV / Output projection / FFN linear都变成W_INTx × A_FP16/8的 mpGEMM。- 低比特的收益本应来自更小权重与更低访存,但现有硬件 datapath 仍围绕 同精度 GEMM 设计。
软件 LUT 在 GPU 上没赢
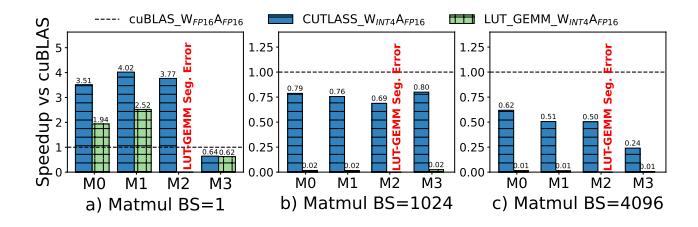
- 论文先证明了一件事: 纯软件 LUT kernel 并不自动更快。
LUT-GEMM在A100上受限于prmt指令宽度、register duplication 与 shared-memory bank conflict,大 batch 时甚至显著落后于CUTLASS。- 所以问题不是“能不能查表”,而是 现有 GPU 对 LUT 的执行路径不友好。
朴素 LUT 硬件也不够好
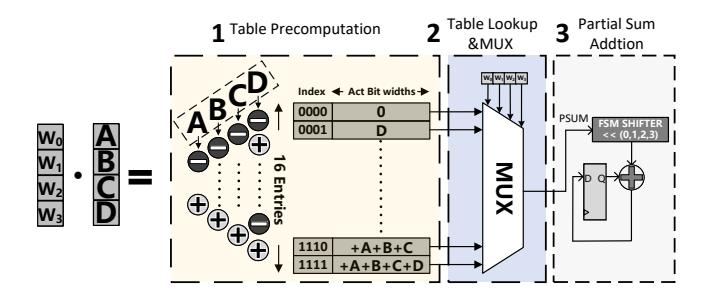
- 传统 LUT accelerator 的三步是: table precompute → table lookup → partial-sum addition。
- 真正拖垮效率的是 precompute redundancy、table storage、broadcast、MUX cost,而不是 LUT 单元本身。
- 这篇论文的切题点很准: 不先减轻建表与存表成本,LUT 硬件不会比 MAC 更划算。
总体方案:软硬协同重写数据流
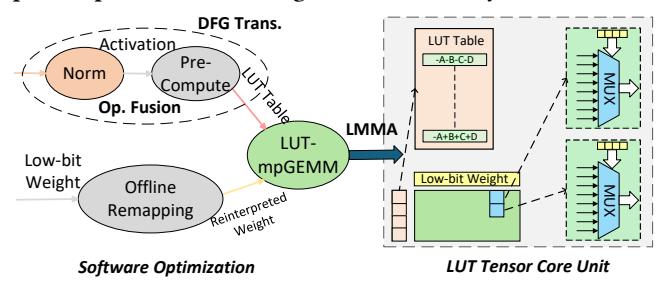
- 软件侧:
DFG transformation把 precompute 剥离成独立算子;operator fusion吃掉额外访存;offline remapping做权重重解释。 - 硬件侧: LUT unit 改成支持
bit-serial、半尺寸 table 和高复用 tiling 的 Tensor Core。 - 接口侧: 用
LMMA指令把 LUT-mpGEMM 纳入现有 tile-based compiler。
机制 1:把建表挪出 Tensor Core
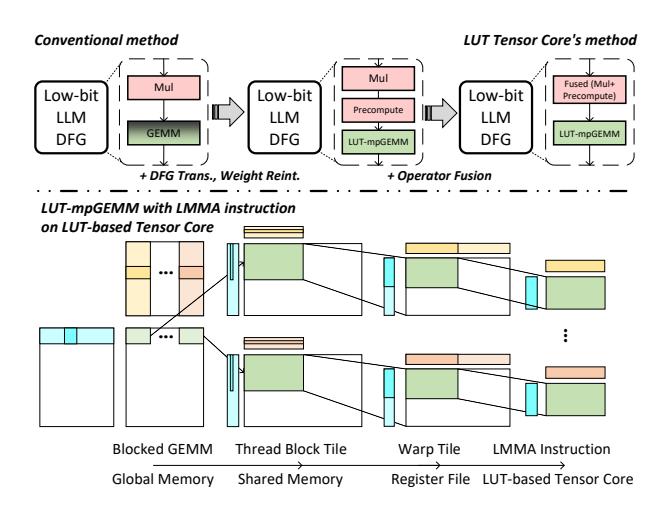
- 传统设计里,每个 LUT unit 都本地重复 precompute;
OPT-175B的例子中,同一张表会被重复算3072次。 - 论文做
DFG transformation + fusion,让 LUT table 变成 一次建表、多处广播。 - 核心价值是把“重复建表”从硬件热点改成编译器可调度的数据流问题。
机制 2:权重重解释让表减半
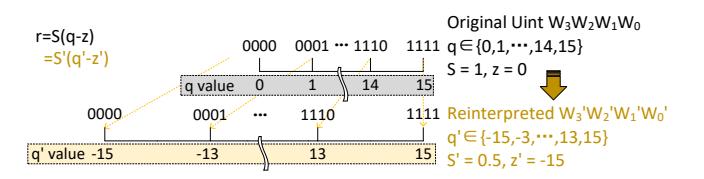
- 作者把
uint q_w重映射到关于 0 对称的q'_w;于是LUT[idx] = -LUT[~idx],表长从2^K降到2^{K-1}。 - 结果不只是表减半,也同步减轻 broadcast、MUX 与后端电路负担。
机制 3:LUT 单元按位串行化
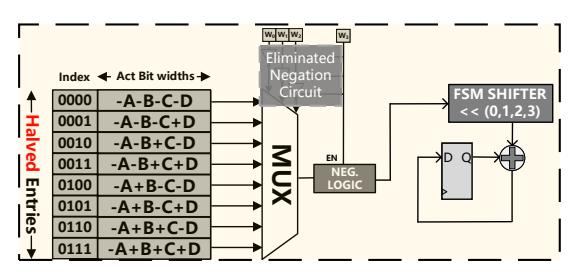
- 软件优化后,硬件里不再需要完整 negation 电路与全尺寸 table,LUT unit 只保留 半尺寸表 + MUX + bit-serial shifter。
W_BIT被映射成 cycle 数,因此同一物理结构可支持INT1/2/4 × FP16/8/INT8等不同精度组合。- 这比为每种 mpGEMM 单独做 MAC datapath 更灵活,也更符合 low-bit LLM 变化快的现实。
机制 4:tile 形状必须拉长
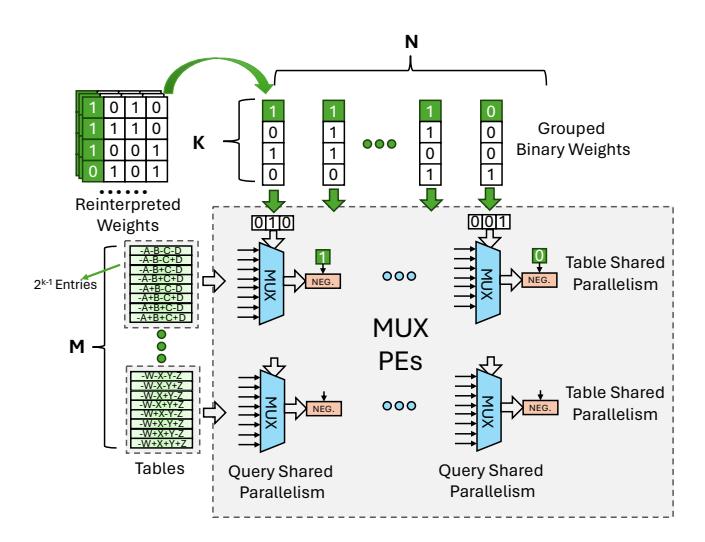
- 传统 Tensor Core 喜欢接近方形的 tile;LUT Tensor Core 则必须 小
M、大N、适中K。 - 原因是 LUT 成本按
2^K增长,而收益主要靠同一张 table 在更多 weight columns 上复用,所以N必须大。 - 最优设计点是
M2N64K4,这就是论文反复强调的 elongated tiling。
LMMA 让它可被编程
- 作者定义
lmma.{M}{N}{K}.{A_dtype}{W_dtype}{Accum_dtype}{O_dtype},保持与MMA接近的编程模型。 - 这样
TVM / Roller / Welder只需注册新的 intrinsic 和 tiling 规则,就能把 low-bit LLM 的mpGEMM映射到 LUT Tensor Core。 - 这一步很重要,因为它说明论文不只是一个 LUT PE,而是试图接入现有 GPU 软件栈。
硬件账单:K=4 是甜蜜点
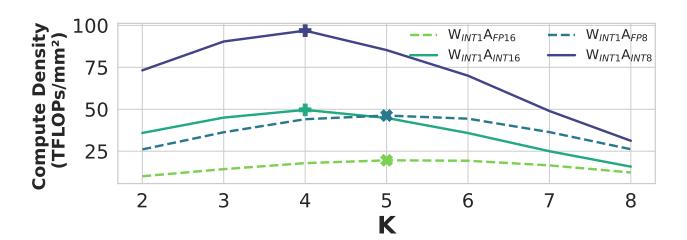
K太小会留下太多加法;K太大又让 LUT 指数膨胀,因此K=4是甜蜜点。- 对
W_INT1A_FP16,LUT DP4 的 compute density 达61.55 TFLOPs/mm²,而传统W_FP16A_FP16MAC DP4 只有3.39 TFLOPs/mm²。 - 论文报告相对传统 Tensor Core 有
4× ~ 6×PPA 改善,但证据仍是综合与仿真,不是 silicon。
方法学
- PPA: Verilog +
Synopsys DC+TSMC 28nm,统一目标1GHz。 - Kernel-level: 改造
Accel-Sim,模拟原始 A100 与搭载 LUT Tensor Core 的 A100。 - E2E: 自建 tile-based simulator,单层对
A100 / RTX3090的平均误差约5.21%。 - Models / Baselines:
LLAMA-2,OPT,BLOOM,BitNet;对比MAC-based TC、ADD-based TC、LUT-GEMM、UNPU等。
PPA:LUT 版更省面积和功耗
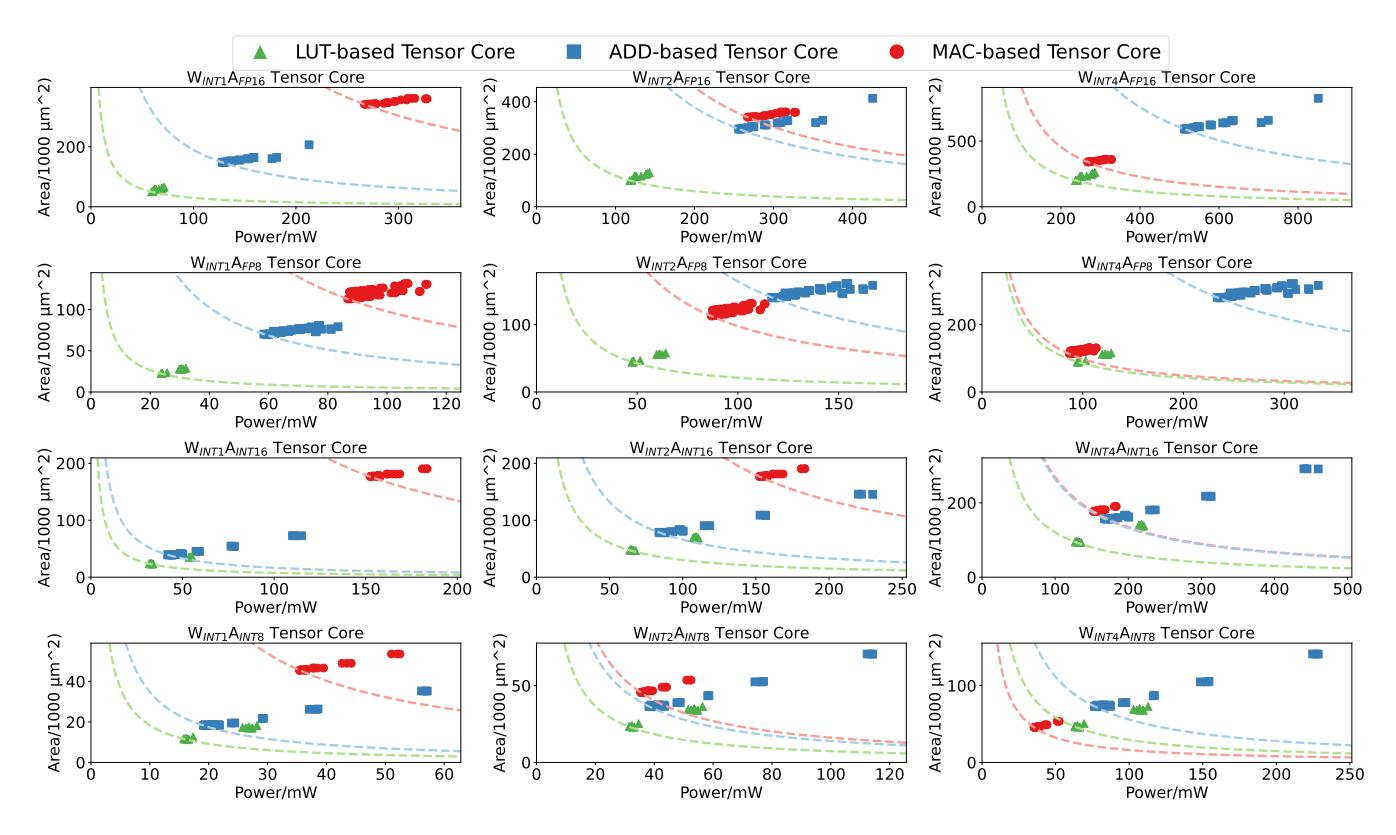
- 图 14 的结论很直接: 多数
W_INT1/2/4 × A_FP16/8/INT8/INT16组合下,绿色 LUT 点都更靠近 area-power 边界。 - 论文最终称 LUT Tensor Core 只占传统 Tensor Core
16%面积,却能提供更高的 mpGEMM 性能。 - 但也要注意,
W_INT8A_INT4一类更高位宽组合下,LUT 优势已经不再绝对。
Kernel:mpGEMM 跑得起来
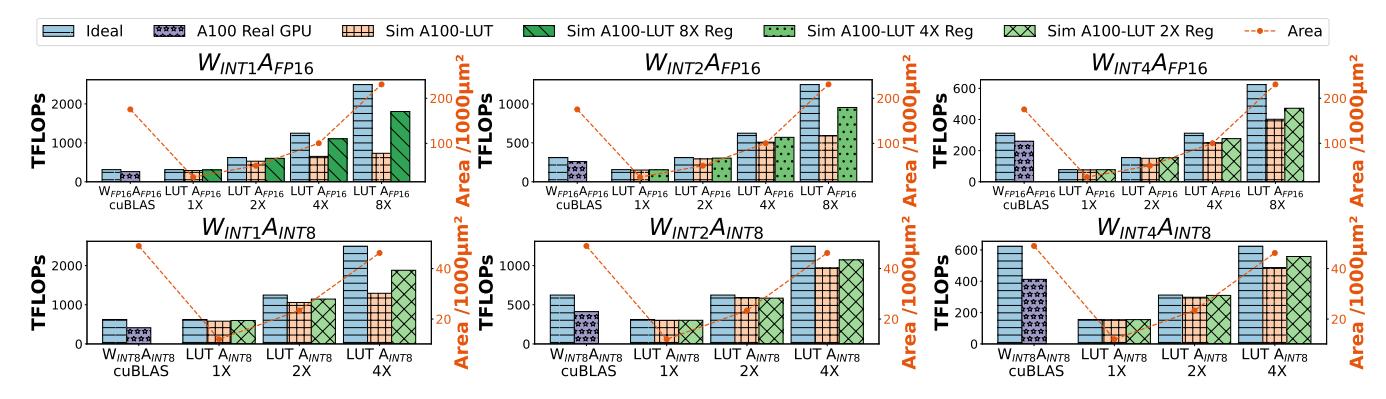
- 论文在
LLAMA2-13B提取的 mpGEMM shape 上,用Accel-Sim评估 LUT Tensor Core。 - 以
W_INT1A_FP16为例,LUT 版只用传统 Tensor Core14.3%area,却能达到略高 throughput。 - 增大 register 后收益更明显,说明瓶颈仍受寄存器和 memory hierarchy 影响。
端到端:对 low-bit LLM 有实益
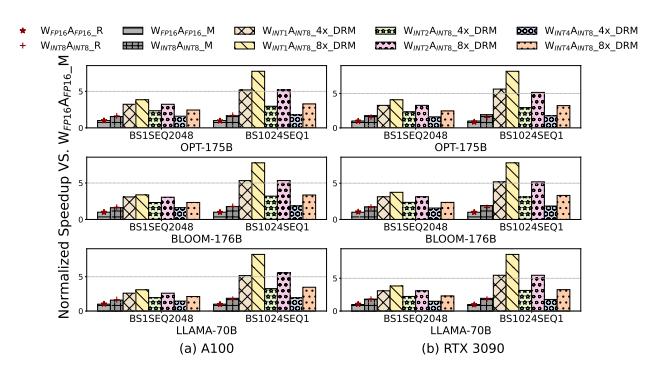
- 在
OPT-175B / BLOOM-176B / LLAMA-70B上,端到端收益随 batch 与模型变化,但趋势稳定优于基线。 - 论文 headline 是 最高
8.2×normalized speedup;更保守看表 1,实际 low-bit inference speedup 为2.06× ~ 5.51×。 - 换句话说,LUT Tensor Core 的收益不是只停留在 kernel microbenchmark,而是能传到 LLM inference latency。
哪些优化最值钱
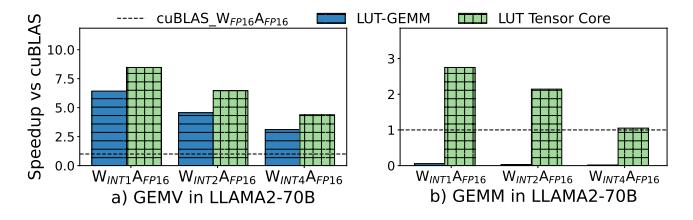
- 对软件 baseline: 相对
LUT-GEMM,LUT Tensor Core 达到1.42×GEMV 和72.2×GEMM。 - 对旧 LUT hardware: 相对
UNPU,加上 reinterpretation、negation elimination 和 fusion 后,compute intensity / power efficiency 都到1.44×。 - 对精度:
INT8 table quantization几乎无损,LLAMA2-7B W_INT2上PPL 7.68 → 7.69。
结论
- 这篇论文最重要的贡献,不是“想到用 LUT”,而是证明 LUT 只有在软硬件一起重构时才可能赢过 dequantization-based mpGEMM。
- 四个关键点是:
precompute fusion、weight reinterpretation、elongated tiling、LMMA + compiler stack。 - 如果记一句话,就是: LUT Tensor Core 把 low-bit LLM 的主算子从乘加问题改写成了高复用的查表问题。
我的评价
- 优点: 问题定义很准,工程链条完整,从 DFG 到 ISA 再到 PPA 与 end-to-end 都讲清楚了。
- 局限: headline 数字高度依赖
Accel-Sim、自建 simulator 和 28nm 归一化,并非 silicon 结果。 - 脆弱假设: precompute 融合默认前驱算子可融合且访存可隐藏;如果图结构不配合,收益会下降。
- 后续方向: 和原生
FP4/FP8Tensor Core、长上下文 attention、KV-cache quantization 做更直接的 full-system 对比。