LUT-LLM
LUT-LLM:面向 FPGA 的存储型 LLM 推理
Zifan He, Shengyu Ye, Rui Ma, Yang Wang, Jason Cong
UCLA, Microsoft Research Asia
2025 preprint
Presenter: wzw
Date: 2026-03-24
TL;DR
- 核心瓶颈: 纯 arithmetic-based LLM inference 在 FPGA 上越来越打不过经过
FlashAttention/FlashDecoding + INT8优化的 GPU。 - 核心想法: 把 linear layers 从 MAC 改成
memory-based computation,并用activation-weight co-quantization + 2D LUT压低带宽和片上访存压力。 - 核心结果: 在
Qwen 3 1.7B + AMD V80上,端到端延迟比MI210低 1.66x,能效比A100高 1.72x,推到32B仍可达 2.16x A100 能效。
背景
- 单 batch / edge 场景下,LLM inference 很难像云端那样靠 batching 吃满 GPU。
- FPGA 的强项不是算力密度,而是 fine-grained dataflow 和更丰富的 distributed on-chip memory。
- 论文关心的不是 attention 全部改写,而是 先把最重的 linear projection 改成查表执行。
为什么要换范式
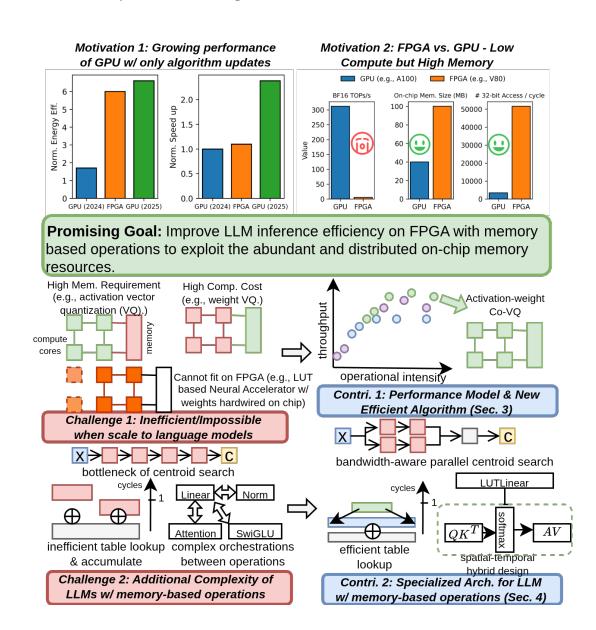
- 现状: GPU 近年在
INT8 + KV-cache optimized decoding上进步很快,SoTA FPGA 已经不再天然占优。 - 观察:
AMD V80的片上 memory units 数量约是A100的 14.9x,容量也更大。 - 结论: 如果还用 MAC 路线拼 compute,FPGA 吃亏; 必须改成 use memory as compute。
现有 LUT 路线为什么不够
- Weight VQ only: 减少权重流量,但 decode 仍受片上 memory ports 和 FP32 reconstruction 限制。
- Activation VQ only: 查表简单,但 LUT / codebook 体积太大,decode 和短 context prefill 会严重 memory-bound。
- LLM 额外复杂性:
centroid search难在 decode 中 pipeline, table lookups 吃 memory ports, linear layers 和 attention / KV-cache 之间的数据搬运也更棘手。
关键观察: 要做 Co-Quantization
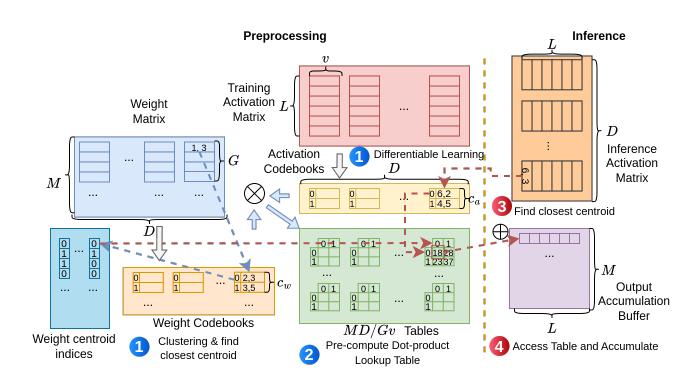
- 论文把三种方案都建了 performance model:
weight-only、activation-only、activation-weight co-quantization。 - 例子里同样配置下:
weight-only约 1090 cycles,activation-only约 8256 cycles,co-quantization约 569 cycles。 - 直觉: 两侧都量化后,2D LUT entry 数下降、memory port 压力变小、INT8 accumulation 更便宜。
Roofline 给出的设计方向
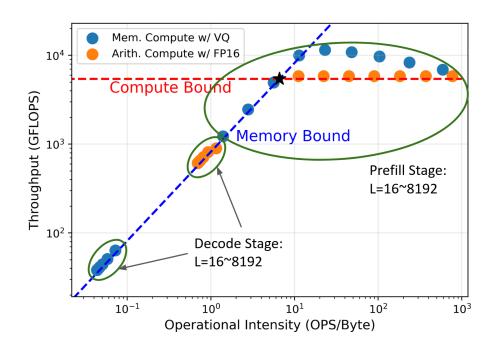
- naive
activation VQ的 memory-based compute 在长序列 prefill 上能比 FP16 arithmetic 更快。 - 但 decode / short-context prefill 会因为 LUT 和 codebook 太大而 operational intensity 很差。
- 这张图真正说明的是: memory-based 路线不是错,错的是只量化 activation,不压缩 weight side 的查表代价。
高层架构
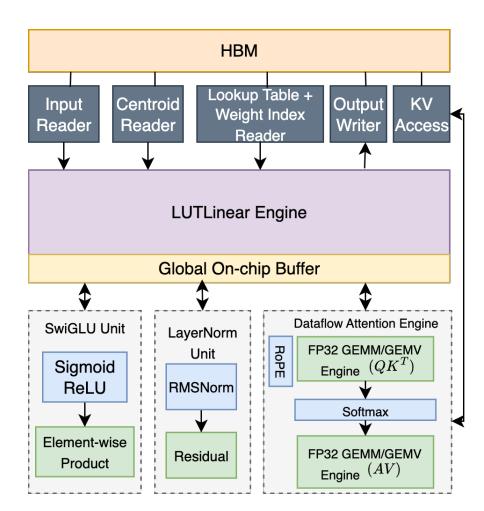
- LUTLinear engine: 负责全部 linear projections,是论文真正的主角。
- Dataflow attention engine: 用 FP32 GEMM/GEMV 支撑 prefill 和 decode 两阶段。
- SFUs: 处理
SwiGLU、LayerNorm等非线性。 - 统一设计同时服务 prefill / decode,不需要两套独立 accelerator。
机制 1: BPCSU
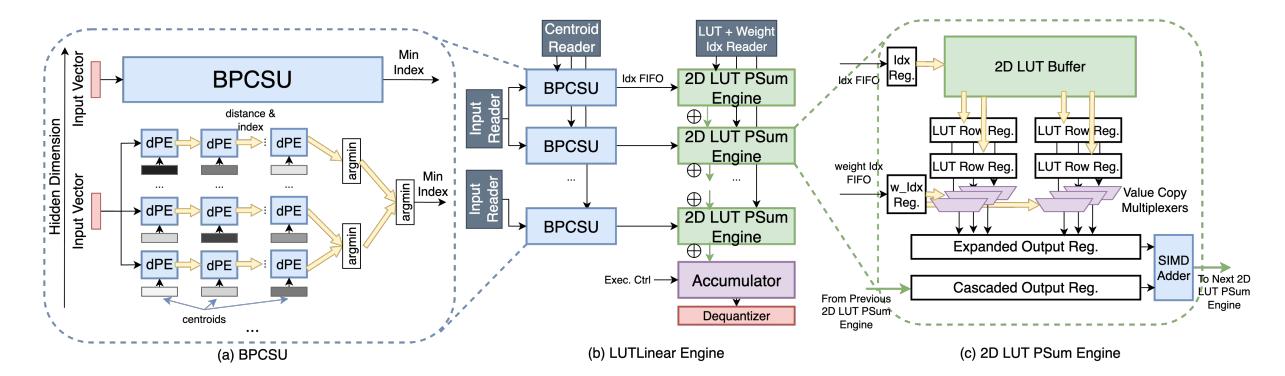
- 问题: decode 时输入序列短,传统单链
centroid searchsetup latency 太高。 - 方案:
Bandwidth-aware Parallel Centroid Search Unit把 dPE 排成 多条 pipeline chains + 小 reduction tree。 - 核心不是盲目全并行,而是让搜索延迟 刚好能被后续 LUT loading 覆盖。
- 文中示例配置下,
c_a=64, c_w=16时每个 BPCSU 选l=16。
机制 2: 2D LUT PSum
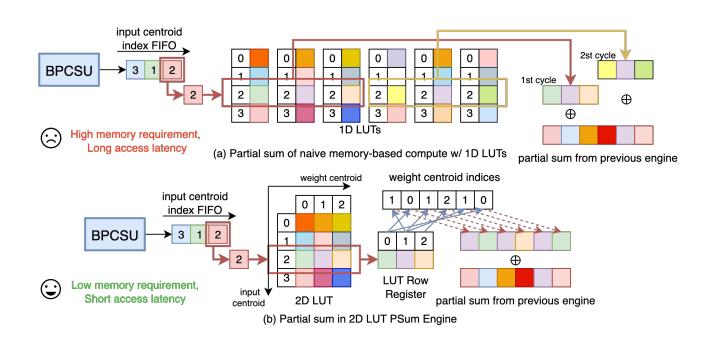
- 普通
1D LUT对每个 output element 单独查表,memory capacity 和 partial-sum latency 都偏高。 - LUT-LLM 先按 activation centroid 取出 一整行 LUT row register,再用 weight centroid indices 批量展开。
- 这样每轮只需要较少 memory ports 就能做并行 gather + SIMD accumulation。
- 实现上混用
BRAM + URAM + LUTRAM,并复制寄存器降低 fanout。
机制 3: Spatial-Temporal Hybrid
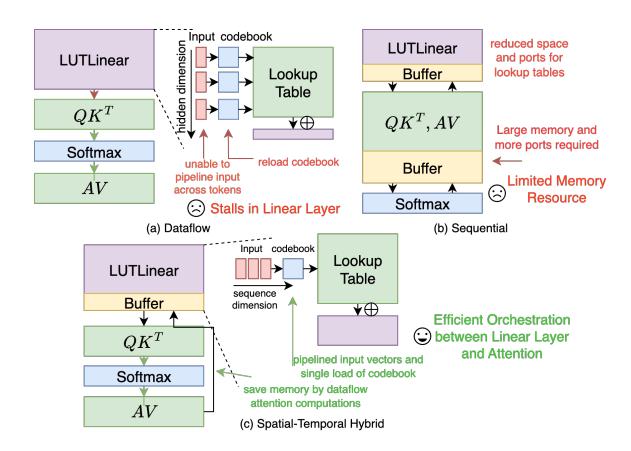
- 纯 dataflow 不适合 LUTLinear:
codebook 会重复加载,
nearest-neighbor search难连续 pipeline。 - 纯 sequential 也不好: attention 需要更大的 buffer / partition,反过来挤占 LUT lookup 资源。
- 最终方案:
LUTLinear按 operation sequential, 输出再以 dataflow 形式送到 attention / SFU。 - 收益: 相比纯 sequential,给 LUT lookup 省出 14% 片上资源。
一次 Token 的执行路径
- Step 1: 输入 token 进入
LUTLinear,先做 activation centroid search。 - Step 2: 2D LUT 根据
activation index + weight index拉出 dot-product entries,并做 SIMD accumulation。 - Step 3:
dequantizer把输出恢复到FP32,送往 attention /SwiGLU/LayerNorm。 - Step 4: prefill 时
K/V流式写入 HBM; decode 时在第一层 linear projection 期间预取历史KV-cache。 - Step 5: attention engine 同时支持
GEMM和GEMV,因此同一设计能覆盖 prefill 与 decode。
实验设置
- Model: customized
Qwen 3 1.7B - Quantization:
G=512, v=2, c_w=16, c_a=64, INT8 LUT,等价于 W2A3 - FPGA flow:
Vitis HLS 2024.2 + TAPA + RapidStream + Vivado 2024.2 - Target:
AMD Alveo V80,227 MHz - GPU baselines:
AMD MI210,NVIDIA A100, 后端为vLLM + FlashAttention + FlashDecoding + GPTQ INT8
模型精度代价
- LUT-LLM 的目标不是“零损失”,而是在 更激进的 W2A3 等价量化 下把质量损失压住。
GLUE + SQuAD v2上,全部技术打开后相对FP16仅 2.7% geomean 下降。- 相比
RTN INT8,INT8 LUT方案 geomean 反而高 5.5%。 - 相比
SmoothQuant W8A8,LUT-LLM 只低约 1.2% geomean;MMLU-Pro也只低 0.9 分。
GPU 对比: 延迟
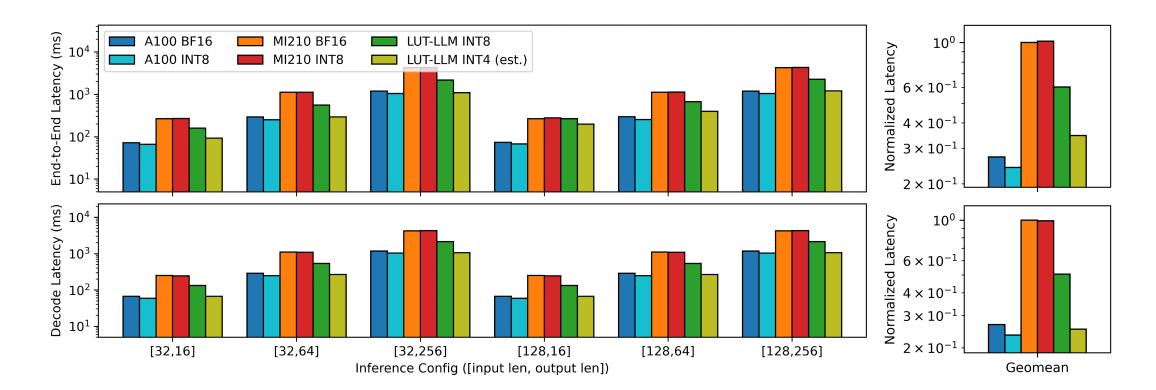
- 对
MI210,LUT-LLM 端到端 geomean latency 低 1.66x,而且只用了约 1/7 的带宽。 - 对
A100,延迟仍然落后,因为FlashAttention/FlashDecoding + GPTQ Marlin非常强。 - 但文中指出 LUT-LLM decode 已吃到 92% available bandwidth,说明瓶颈基本压到了硬件上限。
- 若换成
INT4 lookup tables,输出更长时 latency 可逼近 A100 的BF16/INT8。
GPU 对比: 能效
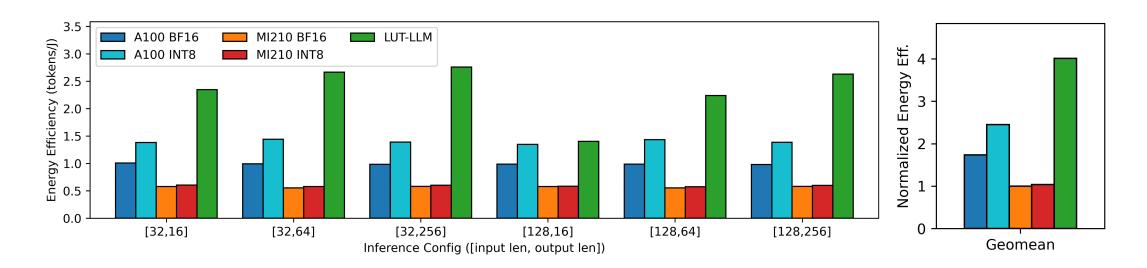
- 相比
MI210,LUT-LLM geomean energy efficiency 高 4.1x。 - 相比
A100,即使对方有GPTQ Marlin,LUT-LLM 仍高 1.72x。 - 输出长度越长,LUT-LLM 和 GPU 的能效差距越大。
- 这很符合论文主张: decode 本质 memory-bound,FPGA 的 memory-based compute 更容易把每 Joule 价值做高。
FPGA 对比与实现开销
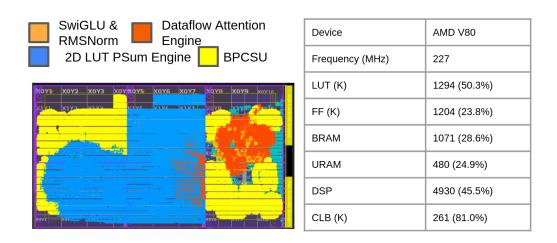
- 对
Allo / InTAR / FlightLLM,LUT-LLM 端到端分别快 5.6x / 1.9x / roughly similar,decode 比FlightLLM快 1.1x。 - 能效上,LUT-LLM 达 2.29 tokens/J,比
FlightLLM / InTAR / Allo高 1.49x / 1.37x / 3.32x。 - 设计频率 227 MHz,CLB utilization 达 81%,说明 routing 压力并不轻。
- HBM 侧用了
32个通道拉 LUT/indices,外加4+4通道做输入与输出/KV-cache,有效 LUT 带宽约 227 GB/s。
这篇论文真正成立的前提
linear layers必须是主瓶颈,否则 memory-based LUTLinear 不会主导整体收益。attention和非线性仍保留高精度执行,所以这不是“整个 LLM 全部查表化”。- 训练侧代价不低: 8-GPU 集群上先 pretrain 再 finetune,作者写明约 2 weeks。
- 现阶段 context window 只做到 512 tokens,更长上下文还受训练算法和系统限制。
论文总结
- 贡献 1: 建立了 memory-based LLM inference 的 performance model,说明 co-quantization 才是正确落点。
- 贡献 2: 用
BPCSU + 2D LUT PSum + hybrid execution把查表型 linear 层真正落到 FPGA。 - 贡献 3: 在
Qwen 3 1.7B / AMD V80上做出对MI210的 1.66x latency 优势,以及对A100的 1.72x energy-efficiency 优势。
我的评价
- 亮点: 不是只讲“FPGA memory 多”,而是把这一点推到完整的
quantization + architecture + roofline闭环。 - 最强 insight: activation-only LUT 路线并不够,必须连 weight side 一起 co-quantize 才能让 decode 成立。
- 局限: 训练代价高,context 只到
512,而且对 SoTA FPGA baseline 的比较有一部分依赖 simulator。 - 开放问题: 如果 attention 也继续低比特化,或者下一代 FPGA/HBM 带宽继续提升,这条路线会不会真正追平甚至超过 A100 latency。