LUT-DLA
LUT-DLA:查表式极低比特 DLA
Guoyu Li, Shengyu Ye, Chunyun Chen, Yang Wang, Fan Yang, Ting Cao, Cheng Liu, Mohamed M. Sabry Aly, Mao Yang
Microsoft Research, UCAS, NTU Singapore
HPCA 2025
Presenter: wzw
Date: 2026-03-24
TL;DR
- 瓶颈:
scalar quantization压到INT1后,ALU 的 area / power efficiency 基本收敛。 - 方法: 用
vector quantization + PSum LUT把 GEMM 改成matching + lookup + accumulation。 - 结果: same-area 下比传统 DLA 快
6.2x~12.0x,功耗/面积效率提升1.4x~7.0x与1.5x~146.1x。
INT1 已接近墙
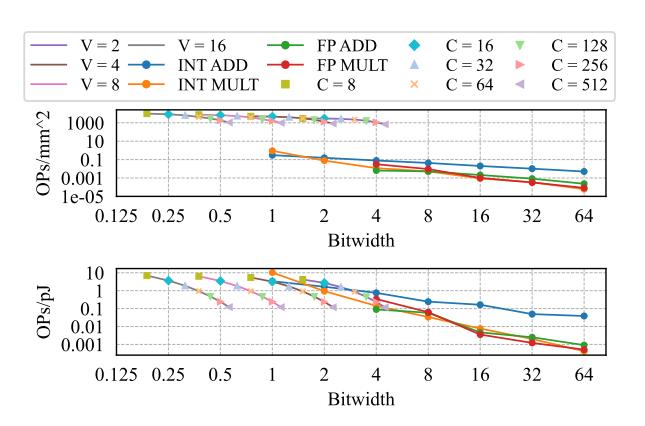
- Fig.1 的关键信号不是 “低 bit 更好”,而是 低到 1-bit 后收益开始收敛。
- 论文的切题点是: 继续抠 arithmetic bitwidth,不如直接换计算范式。
MAC 可以改写成查表
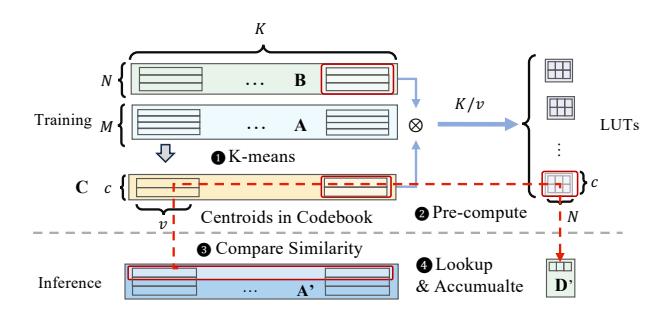
- 子向量先做
VQ,在线只保留 centroidindex。 - 权重固定后,
centroid × weight可离线预计算成PSum LUT。
论文要解决三件事
- Architecture: 现有 LUT work 多在 CPU/PIM 上“能跑”,缺面向
matching + lookup的专用 DLA。 - Training: 旧方法从头训或收敛差,很难扩到大模型。
- Co-design:
v / c / metric / n_CCU / n_IMM同时影响 accuracy 和 hardware cost。
框架是三段闭环
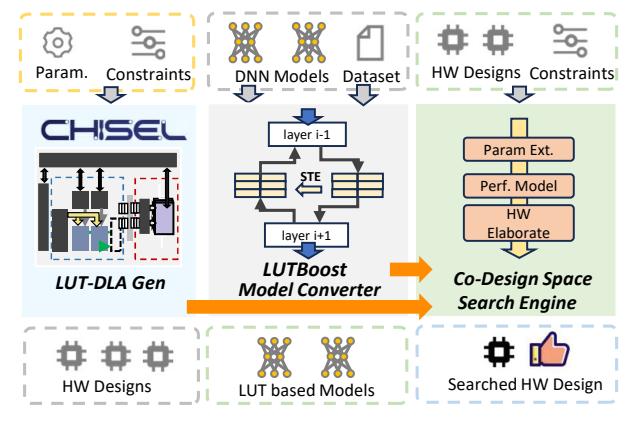
- Hardware Generator 负责
CCM + IMM + dataflow。 - LUTBoost 负责把普通 DNN 转成可用的 LUT model。
- DSE Engine 把 model knob 和 hardware knob 放在同一个搜索环里。
CCM 和 IMM 解耦
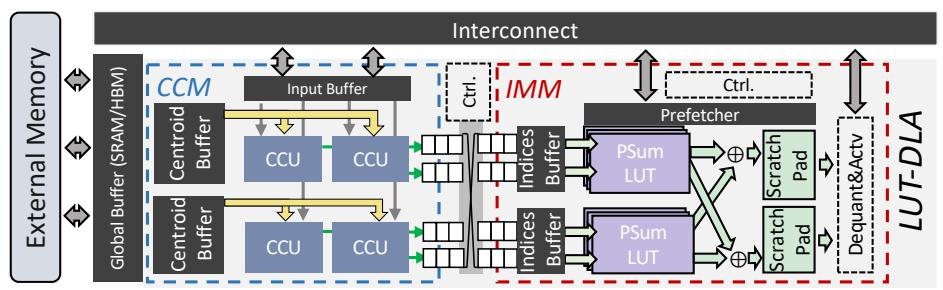
CCM做 similarity search,IMM做PSum LUT查询与累加。- 两者之间用
asynchronous FIFO解耦,可跑在不同 clock domain。 - 这让 compute-heavy 前端和 memory-heavy 后端可以独立扩展。
CCU 把匹配做成流水
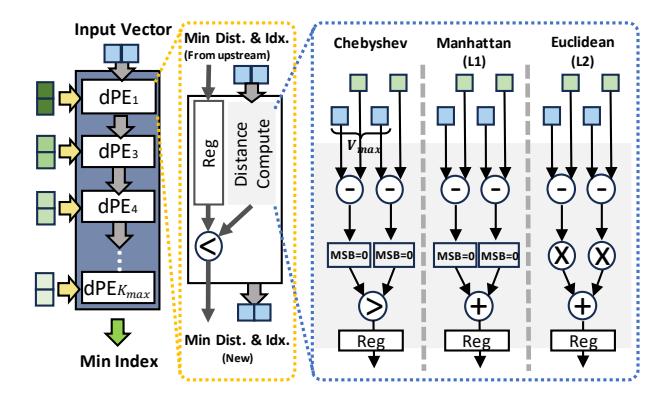
- 每个
dPE比较一部分 centroid,并传递min distance + index + vector。 - 结果是 fully pipelined nearest-centroid search,持续向 IMM 供给 index。
LS dataflow 才让架构落地
| Dataflow | Total Size | 含义 |
|---|---|---|
MNK |
2064.1KB |
LUT 几乎常驻片上 |
KMN |
408.0KB |
scratchpad 过大 |
KNM |
385.3KB |
仍然偏重存储 |
LUT-Stationary |
17.3KB |
LUT 与 scratchpad 最平衡 |
- 在
M=512,K=N=768,v=4,c=32下,LS 把片上总存储压到17.3KB。 - 关键不是减少总传输量,而是用
ping-pong buffer把装载延迟藏到计算后面。
一次 operator 如何执行
CCM按子空间对输入向量做 centroid matching,产出 index。IMM按k/ntile 装载PSum LUT,再用 index 查表并写回 scratchpad。LS dataflow优先复用同一 LUT / codebook;瓶颈若偏 lookup,就扩IMM而不是盲目扩CCU。
LUTBoost 先训 centroid
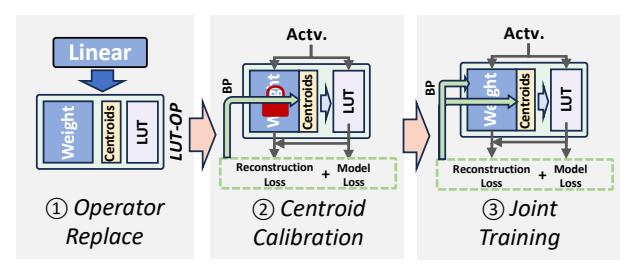
- 三阶段:
replace linear ops -> train centroids -> joint train centroids + weights。 - 直觉是先把 feature prototype 训稳,再让 weights 去适配,避免一开始 overfit 随机 centroid。
Multi-stage 直接改善收敛
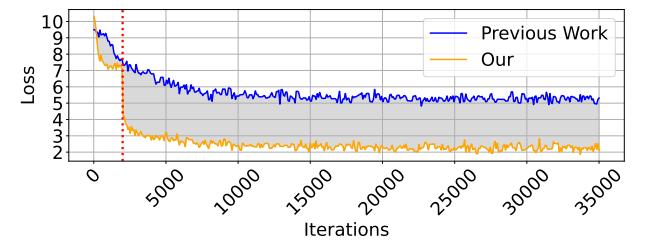
- BERT 例子里,先训 centroid 可在前
2000iterations 明显压低 loss。 CIFAR100上,multi-stage 比 single-stage 提升3.27~5.84pt (L2),5.57~7.20pt (L1)。
metric 也是硬件旋钮
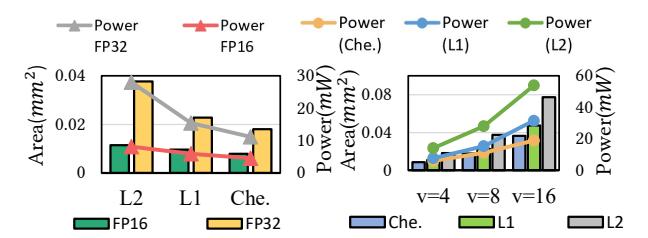
L1去掉乘法器,Chebyshev进一步简化比较逻辑。- 代价是精度只比
L2略差,但 hardware area / energy 明显更低。
DSE 在平衡三个阶段
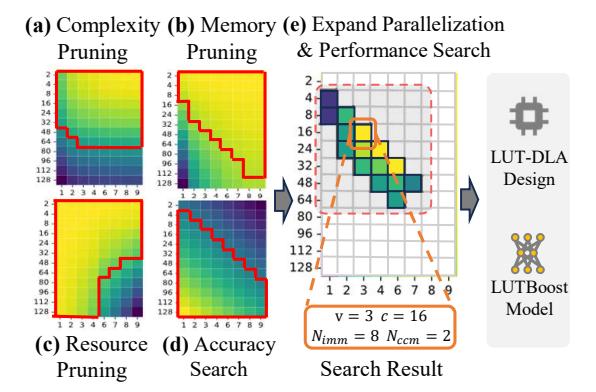
- 目标是最小化
max(load, sim, lut),不是只盯单一 roofline。 - 搜索流程: 先用 computation / memory / PPA 模型裁剪,再用 LUTBoost 早期精度做粗筛。
实验方法够完整
- Models:
ResNet20/32/56,ResNet18,VGG11,LeNet,BERT,DistillBERT,OPT-125M。 - Training: CNN 先训 centroid
20 epochs再 joint300 epochs;BERT 类先训2000iterations。 - Hardware:
Chisel RTL + Cadence Genus + 28nm FD-SOI @ 300MHz。 - Baselines:
NVDLA,Gemmini,PQA, 以及PECAN/POA的准确率对比。
精度损失是可控的
- CNN 的 accuracy drop 为
0.1%~3.1% (L2)、0.1%~3.4% (L1)、0.1%~3.8% (Chebyshev)。 - Transformer 的 accuracy drop 为
1.4%~3.0%。 OPT-125M在 GLUE 上平均分仍有84.9 / 85.4,说明 LUTBoost 已能扩到更大模型。
相比旧 LUT 训练更强
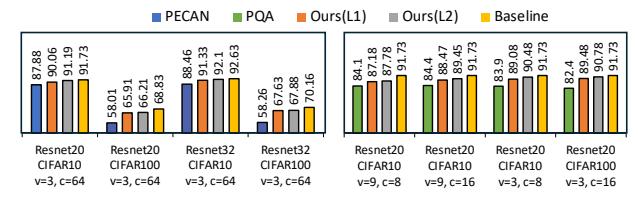
- 对
PECAN/PQA,LUTBoost 在CIFAR10平均高2.5%,在CIFAR100平均高8.2%。 - 这说明论文不只是做了 accelerator,也补齐了 LUT model 的训练可用性。
PPA 很有说服力
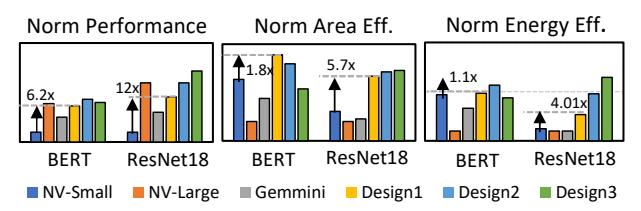
Design1面积接近NVDLA-Small,但在BERT / ResNet18上快6.2x / 12.0x。Design2吞吐接近NVDLA-Large,面积只有其1/7。Design3达到759.5 GOPS/mm^2与5.6 GOPS/mW。
端到端收益也成立
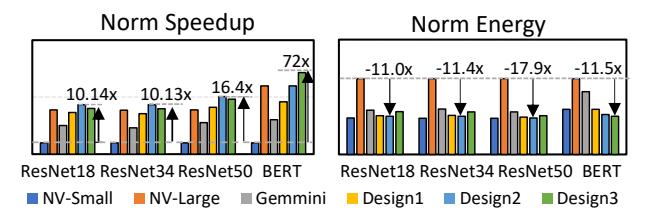
Design2在 CNN 上超过NVDLA-Large,同时节能约11x。Design3在 BERT 上最高达72xthroughput,energy 降低11.5x。- 对比
PQA,同参数 GEMM 下 LUT-DLA 片上内存从6912KB降到10.5KB,cycles 再快1.6x。
结论
- 这篇论文真正绕开了 1-bit scalar arithmetic wall,把核心路径改成 memory-centric lookup。
CCM/IMM + LS dataflow + LUTBoost + DSE形成了一个完整且自洽的系统闭环。- 如果记一个点,就是: LUT accelerator 能不能落地,关键不在查表本身,而在 data reuse 与 training 可用性。
我的评价
- 最强点:
LS dataflow和CCM/IMM decoupling,因为它们解决了 LUT 路线最致命的 storage / bandwidth 问题。 - 局限: end-to-end 依赖 cycle-accurate simulator;Transformer 只统计
QKV + FFN,未覆盖softmax/layernorm全栈成本。 - 开放问题: 若继续把 memory system 与 attention 更多环节 LUT 化,这条路线才有机会成为大模型主流 accelerator。