iTP+xPTP
面向大代码服务器负载的指令感知 TLB/Cache 协同替换
Dimitrios Chasapis, Georgios Vavouliotis, Daniel A. Jiménez, Marc Casas
Barcelona Supercomputing Center, Texas A&M University, Universitat Politècnica de Catalunya
ASPLOS 2025
Presenter: wzw
Date: 2026-03-29
TL;DR
- 瓶颈: server workload 的 large instruction footprint 让 instruction STLB miss 变成前端关键路径上的 stall。
- 方法:
iTP在 shared STLB 中优先保留 instruction translation,xPTP在 L2C 中优先保留 data-PTE block 来补偿额外 page walk。 - 结果: 相比
LRU, 单线程+18.9%, SMT+11.4%; 代价仅是 STLB 每项 4 bit, L2C/L2C MSHR 每项 1 bit。
翻译路径背景
- 现代 x86 路径是:
ITLB/DTLB -> shared STLB -> page walk -> L2C/LLC/DRAM。 - 一次
STLB miss不只是多查一级表, 而是会把多个PTE访存压到 cache hierarchy 上。 - instruction miss 更贵: 它更容易直接卡住 fetch/front-end。
- data miss 较便宜: 在 OoO core 中, 一部分 latency 还能被 memory-level parallelism 隐藏。
Baseline 痛点
- 厂商常用的
STLBreplacement 仍接近LRU, 或像CHiRP一样不区分 instruction/data PTE。 - 这等于默认“所有 translation miss 代价相同”, 但对 big-code server app 这个前提不成立。
- 只在 STLB 中偏袒 instruction 也不够: 它会制造更多 data page walk, 进一步冲击
L2C/LLC。 - 所以问题不是单独优化
STLB或cache, 而是要做 cooperative replacement。
关键观察
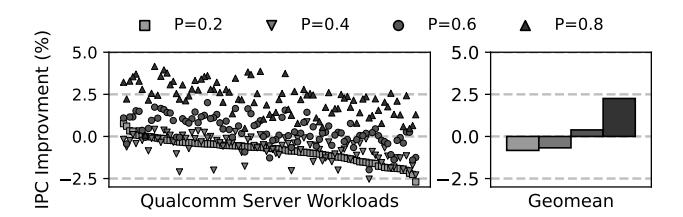
- 在 Qualcomm server workloads 上, 越偏向保留 instruction entry, IPC 越高。
- 反过来若优先保 data entry, 性能会下降;
SPEC基本不敏感, 因为其 code footprint 多数已装进ITLB。 - 这说明 shared STLB 中真正该保的不是“最近用过的页”, 而是 更贵的 instruction translation。
总体结构
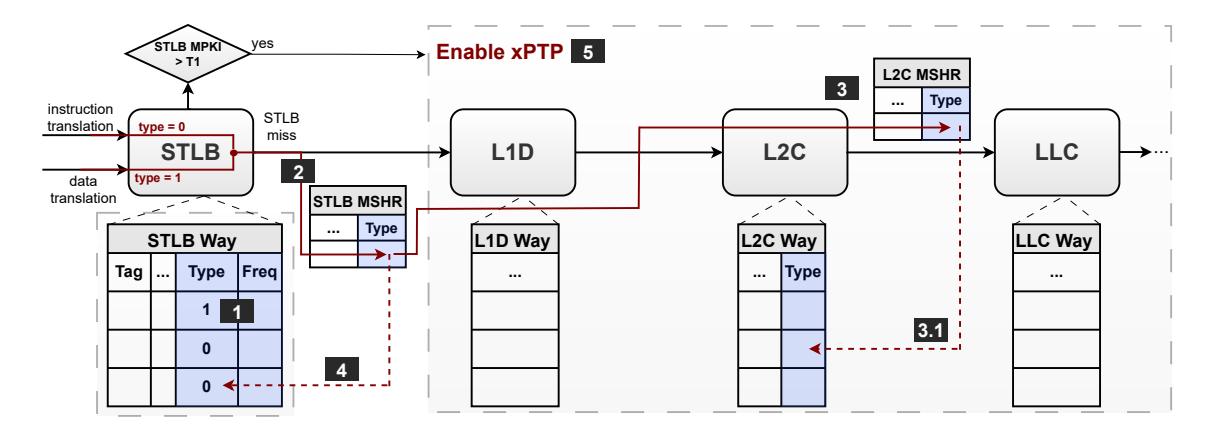
- iTP: 在
STLB中让 instruction translation 站在 recency stack 的高位。 - xPTP: 在
L2C中尽量别踢掉保存 data PTE 的 block。 - Adaptive gate: 当
STLB MPKI > T1才启用xPTP, 否则退回LRU。
机制1:iTP
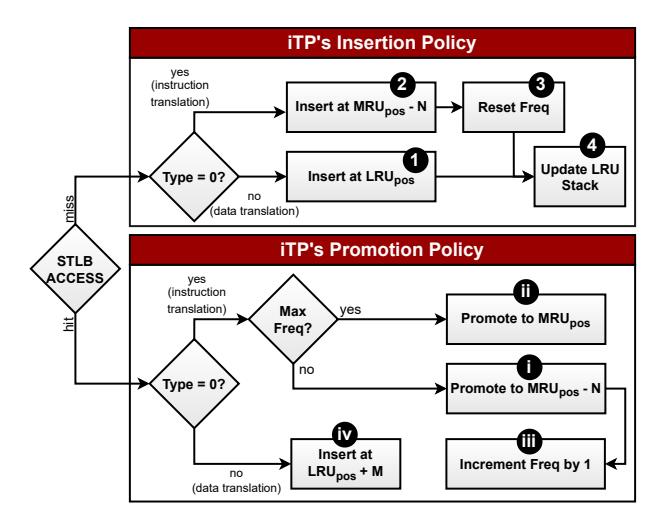
- 插入: data 放
LRUpos; instruction 放MRUpos - N。 - 提升: 高频 instruction hit 才升到
MRUpos; data hit 只到LRUpos + M。 - 目标: 用更便宜的 data miss, 换掉更贵的 instruction miss; 参数
N=4, M=8。
机制2:xPTP
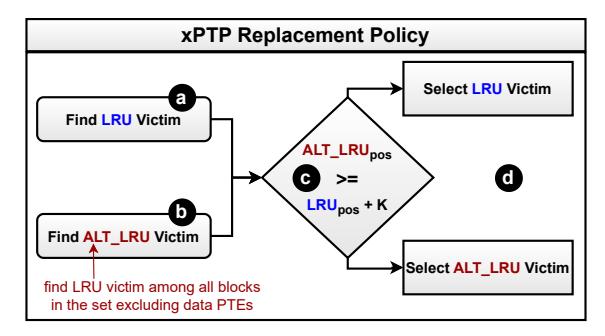
xPTP给L2C block和L2C MSHR加一个 Type bit, 标记该块是否存放data PTE。- miss 时同时找两个候选: 普通
LRU victim与“不含 data PTE 的备选 victim”。 - 规则很简单:
victim = LRUpos if ALT_VICTIMpos >= LRUpos + K else ALT_VICTIMpos, 其中K=8。
一次 miss 如何流动
- instruction/data 请求在
L1 TLBmiss 后访问 sharedSTLB。 - 若
STLB miss,STLB MSHR记录 Type, 然后启动 page walk。 - 若 page-walk reference 在
L2Cmiss,xPTP把 Type 传播到L2C MSHR与最终L2C block。 - page walk 完成后,
iTP按 Type/Freq 决定 translation 在STLB的插入位置。 - runtime 端每
1000条动态指令统计一次STLB MPKI; 高于阈值T1才开启xPTP。
硬件账单
| 结构 | 新增元数据 | 作用 |
|---|---|---|
STLB entry |
1b Type + 3b Freq |
驱动 iTP |
STLB MSHR |
1b Type |
记录 miss 来源 |
L2C block |
1b Type |
标记 data PTE |
L2C MSHR |
1b Type |
传播 Type |
- 对 1536-entry STLB, iTP 的额外存储仅
768B。 - 论文声称对 1536-entry 及以上 STLB 不增加访问延迟; 更小 STLB 可能需要把 metadata 做成旁路小结构。
- 这不是重型 predictor, 更像 低成本 metadata + policy retiming。
方法学
- Simulator:
ChampSim, 5-level radix-tree page table, splitPSC, x86 page walker。 - 关键配置:
64-entry ITLB,64-entry DTLB,1536-entry STLB,512KB L2C,2MB LLC/core。 - Workloads:
120个单线程 Qualcomm server traces,75个双硬件线程组合; 另用SPEC 2006/2017做 motivation。 - Baselines:
TDRRIP,PTP,CHiRP, 以及这些方案与 iTP 的组合; 还测了SHiP/Mockingjay和2MB page场景。
主结果:IPC
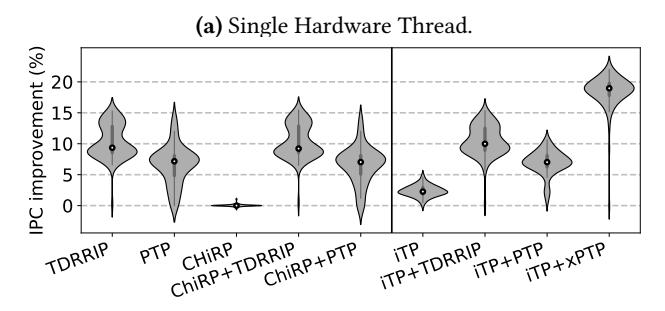
iTP单独只有+2.2%: 只偏袒 instruction translation 还不够。- 配上
xPTP后, 单线程 geomean 到+18.9%; 明显高于TDRRIP 9.3%,PTP 7.1%,CHiRP ≈ 0%。 - 双硬件线程下仍有
+11.4%, 说明收益不只来自“理想单核”。
为什么会赢
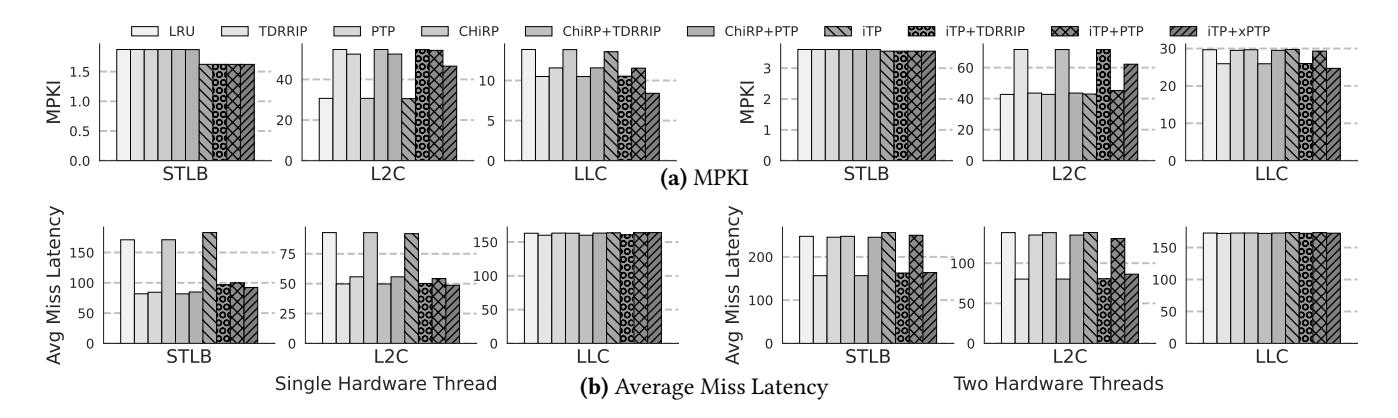
- 单线程下,
STLB MPKI: 1.8 -> 1.6,STLB miss latency: 170.9 -> 92.3。 L2C MPKI虽上升30.6 -> 46.5, 但LLC MPKI同时下降13.8 -> 8.4。- 本质是: 把更贵的 deep miss 换成更多但更浅的 miss, 并用
xPTP降低 data page walk 的 cache 代价。
敏感性:大页会削弱收益
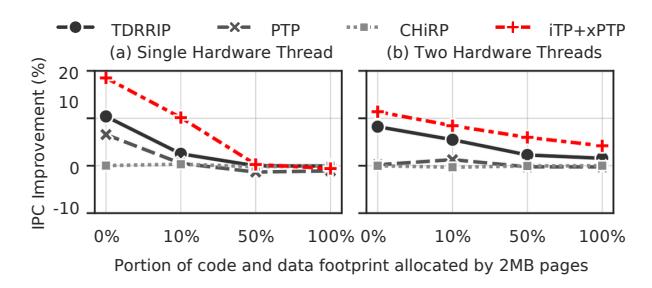
- 当更多 code/data 映射到
2MBpages,STLB压力下降, 所有方案的收益都变小。 - 但在 10% large-page 覆盖时,
iTP+xPTP仍有 单线程10.1%/ 双线程8.4%提升。 - 即使 100% 都用
2MBpage, 双线程下仍有4.2%; 说明设计不是只对 4KB-only 人造场景有效。
结论
- 这篇论文最重要的 insight 是: shared STLB 不该优化“平均 miss”, 而该优化“最贵的 miss”。
iTP+xPTP把 instruction-side 的翻译代价转移到 data-side, 再用 cache policy 把副作用收回来。- 它用很小的 metadata 开销, 换到了接近“加大 STLB 容量 / split STLB”才能达到的收益。
我的评价
- 优点: 问题定义很准, 协同设计完整, 而且不是靠超复杂 predictor 堆出来的结果。
- 脆弱假设: 论文几乎把收益建立在 Qualcomm 的 big-code server traces 上, workload 泛化性还不够强。
- 缺失实验: 没有真正给
RTL/timing/power级别的实现证据, 对产品化风险交代不足。 - 后续方向: 可把
Type扩展成更细的 translation criticality class, 或把xPTP与 code-awareL2policy 联合。