Helix
Helix:用最大流在异构 GPU 与网络上服务 LLM
Yixuan Mei, Yonghao Zhuang, Xupeng Miao, Juncheng Yang, Zhihao Jia, Rashmi Vinayak
Carnegie Mellon University
ASPLOS 2025
Presenter: wzw
Date: 2026-03-30
TL;DR
- 瓶颈: 现有 LLM serving 默认
homogeneous GPU + fixed pipeline;到了异构 GPU、跨地域网络后,切层 和 路由 会互相卡死。 - 方法: Helix 把 serving 抽象成 max-flow,用 MILP 离线求
model placement,再用 per-request pipeline + IWRR 在线逼近最优流。 - 结果: 相比 baseline,吞吐最高
3.3x;在 geo-distributed 场景,prompt / decode latency最高下降66% / 24%。
为什么异构是刚需
- 大模型越来越大: 论文给的例子里,
LLaMA-3 405B若按传统同构 serving,需要68×L4 / 41×A100 / 21×H100。 - 现实云平台却越来越异构: GCE 各 region 的
H100 / A100 / L4 / T4可用性差异很大,很难在单个 region 拿到足够多同类 GPU。 - 这意味着真正的问题不再是“怎么把模型放到一类 GPU 上”,而是 如何把不同算力、不同显存、不同网络条件的机器联合起来。
天真切层为什么错

Figure 1展示了三种失败方式: 平均切层会拖慢强 GPU,只平衡 FLOPs 会把慢链路打爆。- 关键点是:
model partition、device placement、request scheduling是强耦合的,不是三个独立 heuristic。
核心抽象:最大流
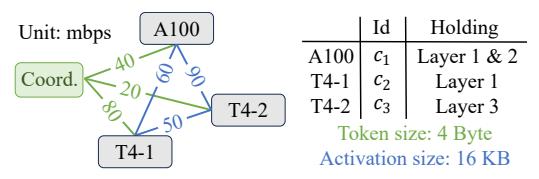
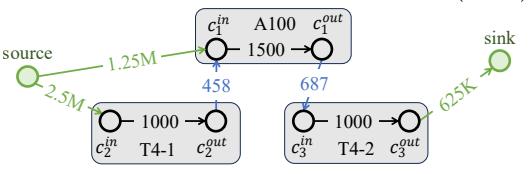
- 每个 compute node 被拆成
c_i^in -> c_i^out,边容量表示 token processing throughput。 - 节点间边容量由 network bandwidth / token or activation size 决定;于是 source 到 sink 的 max flow = cluster 的最大 serving throughput。
MILP 怎么落地
$$ \max \sum_i f_{\text{source}, i} $$
- 关键不在 “用了 Gurobi”,而在于把 连接合法性 线性化进 MILP,同时把规模压到接近
O(nodes + edges)。
Helix 运行时全景
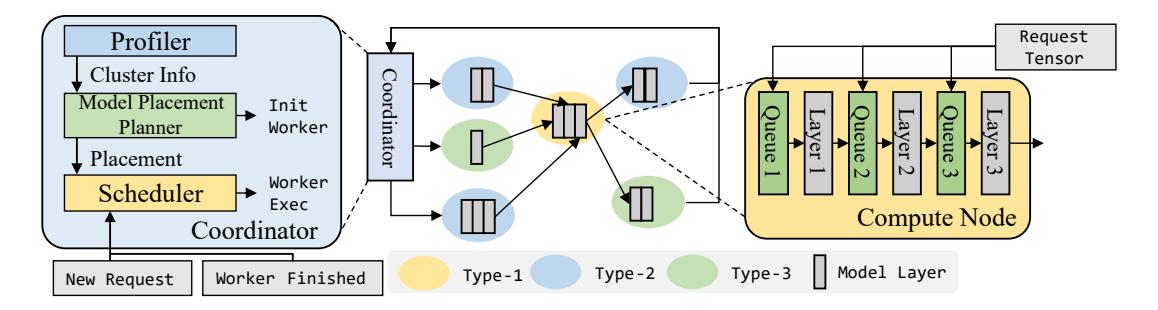
- 离线: coordinator 根据 cluster profile 求一次最优 placement。
- 在线: 新请求到达后,不走固定 pipeline,而是按当前 topology graph 生成自己的 pipeline。
- 这让 Helix 真正把“离线最优流”变成了“在线调度策略”,而不是纸面优化。
每请求一条 pipeline
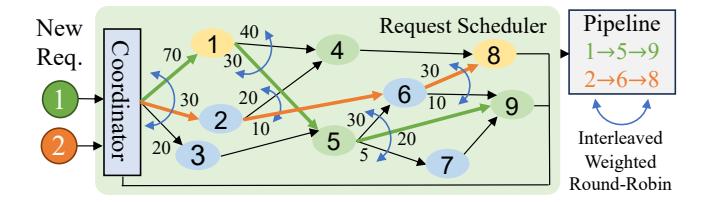
- 运行时每个 vertex 都挂一个
IWRRscheduler,候选后继节点的权重正比于 max-flow 解中的边流量。 - 这样请求会按
P(u \rightarrow v) \propto f_{u,v}的频率分流,避免 fixed pipeline 的空转与局部拥塞。 - Helix 的一个亮点是: pipeline 可以交叠,不要求每条 pipeline 拿一组互斥机器。
别把 KV-cache 撑爆
- 只按流量路由还不够,因为 LLM serving 还有一个动态约束: 每张卡的 KV-cache 容量。
- Helix 维护各节点的 KV-cache usage estimation,用平均 output length 估计未来占用;超过 high-water mark 的节点会被临时 mask 掉。
- 所以它不是盲目追求 max-flow,而是在运行时加了一个 memory safety guard,避免 offload 到 host memory 把吞吐拖垮。
实验怎么做
- 模型:
LLaMA-1 30B与LLaMA-2 70B,FP16。 - 真实单集群:
4×A100 + 8×L4 + 12×T4,同 region,10 Gb/s网络。 - Geo-distributed 仿真: 3 个 cluster,跨 region 链路平均
100 Mb/s、50 ms。 - 高异构仿真:
42个节点、7种节点类型。 - Trace: Azure Conversation dataset,裁剪后
16,657个请求,平均 input763、output232。
单集群结果
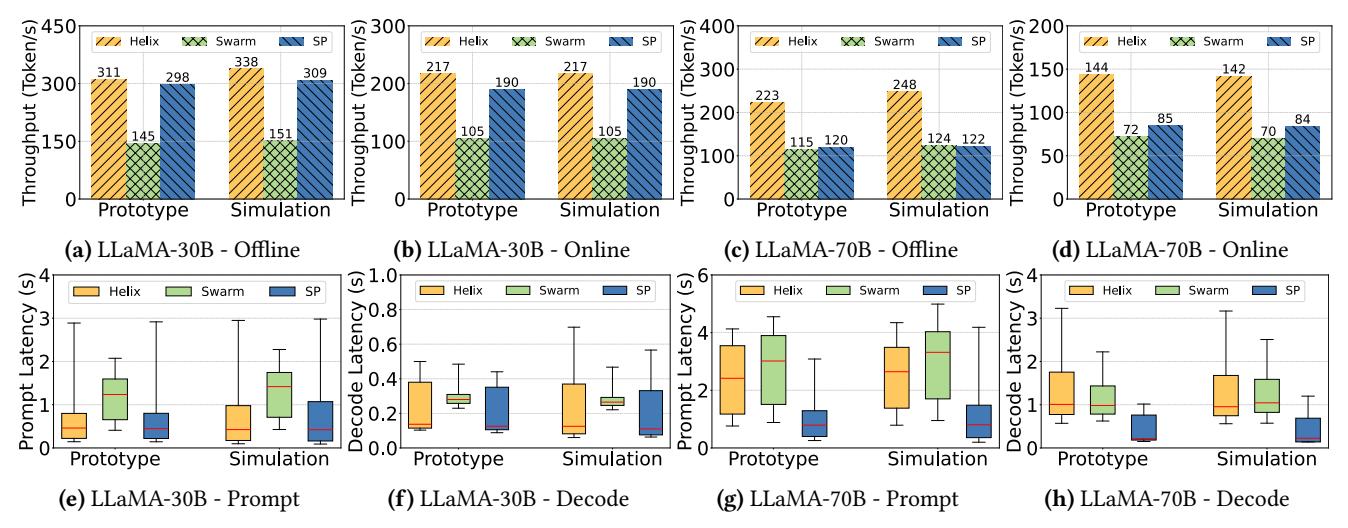
LLaMA 30B: 与SP接近,但相对Swarm的 decode throughput 仍高2.14x / 2.07x。LLaMA 70B: 相对SP达1.86x / 1.69x,相对Swarm达1.94x / 2.00x。模型越大,异构混用越必要。
跨地域结果

- 慢链路出现后,baseline 很容易把 activation 送上拥塞边,因此 placement + scheduling 必须联合优化。
LLaMA 30B: 相对Swarm吞吐2.41x,在线prompt / decode latency降66% / 24%;LLaMA 70B的 pipeline 深度也比Swarm少28%。
高异构结果
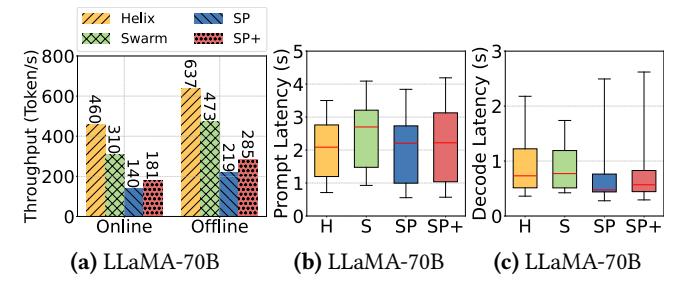
- 在
42-node / 7-type集群里,V100、T4、2×T4这类机器根本很难靠自己形成好 pipeline。 - 相比
Swarm / SP / SP+,Helix offline throughput 分别是1.37x / 2.91x / 2.24x,online throughput 分别是1.48x / 3.29x / 2.54x。 - 这说明 Helix 的价值不是“把最快的 GPU 用得更满”,而是 把原本会被闲置的慢 GPU 也编进全局最优里。
Placement 真因

- 这页最有说服力: Helix 不是只报 “higher bars”,而是展示了 为什么 placement 不同会决定 GPU 是否满载。
- 在单集群
LLaMA 70B上,Helix 相比Petals / Swarm的 offline throughput 分别高1.23x / 2.10x。 - 根因是 Helix 避开了末端
T4 bottleneck,让几乎所有节点都接近 fully-utilized。
Scheduling 真因
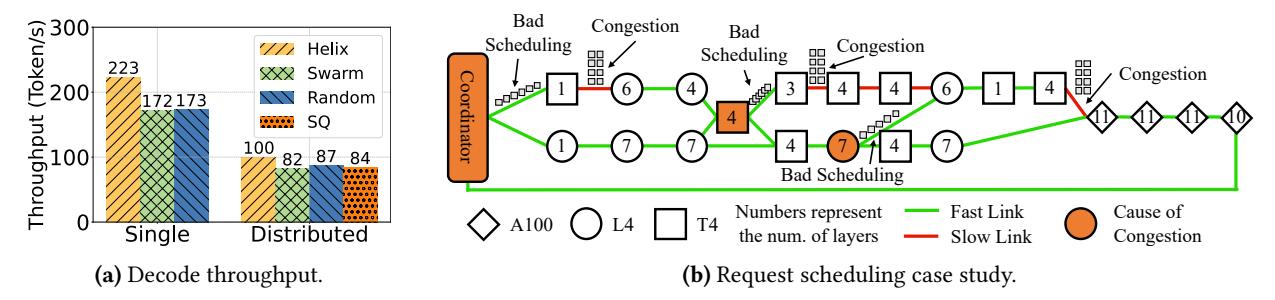
- 即使固定同一个 placement,不同 scheduling 仍会把慢链路打爆。
- 在
LLaMA 70B上,Helix 相比Swarm / random / shortest-queue,吞吐高30% / 29% / 19%。 - 论文甚至观察到: 某个拥塞点可能由 3 hops 之外 的错误调度引起,这说明异构网络下必须要有全局视角。
代价与可部署性
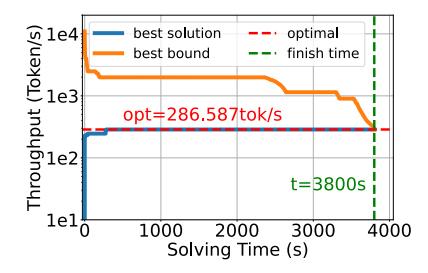
- 工程量不小:
1.5k LoC Python + 1.7k LoC C++,另有14k LoCsimulator。 - 规划成本偏高: 最大搜索预算
4h;小例子<5 min找到最优,但证明最优可能要1h+。 - 降成本主要靠
cluster pruning与 heuristic warm-start,问题规模可降36% / 46%。
我的结论
- 最强点: 这篇论文抓到的不是某个局部 trick,而是 异构 GPU serving 的本质耦合项: placement 与 scheduling 必须一起优化。
- 最值得记住的设计:
max-flow abstraction + per-request pipeline,它把离线最优和在线执行真正接上了。 - 主要保留意见: 很多 hardest case 依赖 simulator;优化目标也更偏 throughput-optimal,而不是
P99 TTFT或多租户公平性。 - 后续方向: 把 Helix 和
prefill/decode disaggregation、speculative decoding、甚至cost / carbon-aware objective结合,会更接近生产系统。