FSMoE
FSMoE:灵活且可扩展的稀疏 MoE 训练系统
Xinglin Pan, Wenxiang Lin, Lin Zhang, Shaohuai Shi, Zhenheng Tang, Rui Wang, Bo Li, Xiaowen Chu
HKUST(GZ), Harbin Institute of Technology Shenzhen, HKUST
ASPLOS 2025
Presenter: wzw
Date: 2026-04-03
TL;DR
- 瓶颈: 现有 MoE training system 往往只 overlap
AlltoAll + expert compute, 但在DP+MP+EP+ESP下, 真正的瓶颈是 inter-node / intra-node 通信与 backward gradient sync 的联合调度。 - 方法: FSMoE 用 六模块抽象 + 在线 profiling + case-based schedule optimizer,并加入 adaptive gradient partitioning,分别优化 forward/backward 的 pipeline degree。
- 结果: 在
1458个配置化 MoE layers 上相对 Tutel 达到1.18x-1.22x;在真实 GPT2/Mixtral 模型上相对 DS-MoE 达到1.28x-3.01x。
背景:MoE 层在做什么
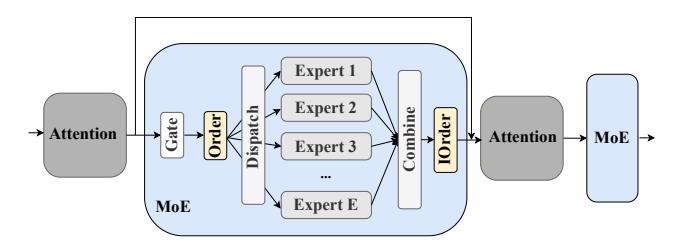
- 一个典型 sparse MoE layer 包含
Gate,Order/I-Order,Experts三部分。 - 每个 token 只激活
top-kexperts,所以 active FLOPs 不高,但 数据重排与跨设备通信很多。 - 真正难的不是单机算 experts,而是 把 token 精确送到正确 expert,再高效送回来。
旧系统为什么不够好
- 现有系统如
DeepSpeed-MoE,Tutel,PipeMoE大多针对特定 routing 或固定 schedule 做优化。 - 在大规模训练里,MoE layer 同时引入:
AlltoAll,AllGather,ReduceScatter,Gradient-AllReduce,expert compute。 - 论文给出的真实模型 breakdown 指出:
通信常占 MoE layer 时间的
30%-60%,不少场景总占比超过一半。 - 所以问题不是 “把一个 kernel 做快一点”,而是 整个训练路径的任务编排没有做对。
关键观察:还有两层 overlap 没吃到

- 在常见部署里,
MP与ESP往往对齐到单节点 GPU 数。 - 这意味着
ESP-AllGather / ESP-ReduceScatter通常是 intra-node,而AlltoAll / Gradient-AllReduce通常是 inter-node。 - 洞察: 旧方案主要 overlap
AlltoAll + expert,但没有系统性利用 节点内外通信的带宽分层。
第二个观察:forward 和 backward 不该共用一个 r
- 旧系统常把同一个 pipeline degree
r同时用于 forward 与 backward。 - 但 backward 多了
weight gradient计算与Gradient-AllReduce,代价结构已经变了。 - 论文在
1458个配置上发现: 有912个 case 的 forward / backward 最优r不同。 - 所以如果 schedule 只调一次, 实际上经常在一半 phase 上是次优的。
系统总览:FSMoE 把 MoE 拆成六模块
Gate: token routingOrder / I-Order:(B, L, M) <-> (E, T, M)数据布局变换Dispatch / Combine: token-to-expert 通信算法Expert: FFN 计算本体- 外加 hooks: 支持压缩、多模态输入重排、定制前后处理
FSMoE 的核心不是重新写一个固定 MoE kernel,而是让 前端 API 与后端 scheduler 解耦:
开发者替换 gate/order/dispatch/expert 实现后,调度器仍可基于 profiling 自动找 schedule。
机制1:统一抽象解决 flexibility
- 论文预置了
4类 routing:GShard,Sigmoid,X-MoE,SoftMoE。 - 预置了
2类 ordering:GShard ordering与Tutel ordering。 - 预置了多种 AlltoAll:
NCCL-A2A,1DH-A2A,2DH-A2A。 - 重点不是“支持得多”,而是 支持新模块时不用重写 scheduler。
- 这点很关键,因为 MoE routing 机制在 2024-2025 迭代非常快。
机制2:把节点内外通信一起编排

- FSMoE 把输入切成多个 chunks,按 pipeline 依次流过
AlltoAll,AG/RS,expert,Gradient-AllReduce。 - 关键变化不是多做 overlap,而是 把 inter-node 与 intra-node 两类通信解耦后同时隐藏。
- 对 backward 来说,最后一个 chunk 之后紧接
Gradient-AllReduce,尽量吃掉原本裸露的同步时间。
机制3:性能模型
- 核心模型:
$t_{*,r} = \alpha_* + \frac{n_*}{r}\beta_*$ AlltoAll,AG,RS,expert都按这类模型估时。- 最优
r就是在 overlap 收益 与 startup cost 之间折中。
四种 case 决定用哪个 r
- 作者把主要瓶颈归类成
4种 case: inter-node 主导、expert 主导、AlltoAll 主导、intra-node 主导。 - 每个 case 写出对应的
t^{moe}(r),再用SLSQP求局部最优。 - 最后取
4个候选中最小时延对应的r。 - 这不是严格全局最优证明,但它把复杂依赖压成了 可执行的系统优化器。
机制4:切梯度
$n_{first}^{i} = g_{grad}^{inv}(\min(t_{grad}(n_{grad}^{i-1}), t_{olp}^{i}))$- 先估每层可隐藏窗口,再跨层分配剩余梯度。
- 关键价值: 梯度块大小跟 layer overlap 窗口一起自适应。
一次训练迭代怎么走
- 输入进入
Gate + Order,被映射到(E, T, M)布局。 Dispatch把 token 沿EP送往对应 experts;若 expert 被 shard,再做ESP-AllGather。Expert计算完成后,做ESP-ReduceScatter + Combine返回原布局。- backward 阶段同时插入切分后的
Gradient-AllReduce,并按 phase-specificr运行。 - 调度器实际优化的是: 不要让 inter-node、intra-node、compute 中任意一个长时间裸奔。
系统代价与前提
- 不是新硬件: 这是 runtime / system design,主要代价是实现复杂度而非 area。
- 需要 profiling: 在新集群上要先测
GEMM + NCCL collectives,再拟合\alpha/\beta。 - 需要手工 backward: 论文明确为支持 phase-specific schedule 而手写 backward path。
- 拓扑前提较强: 最佳收益依赖
N_MP = N_ESP = GPUs per node这类部署。 - 结论: 这是一个很实用的系统优化,但不是“任何拓扑都稳赚”的通用银弹。
方法学
- 平台:
Testbed-A = 48 GPU,Testbed-B = 32 GPU - 软件栈:
Ubuntu 20.04,CUDA 11.3,PyTorch 1.12,NCCL 2.12 - 配置化实验:
共
1458个 attention/MoE layer 组合 - 真实模型:
GPT2-XL-based MoE,Mixtral-7B,Mixtral-22B - 基线:
DeepSpeed-MoE,Tutel/PipeMoE,PipeMoE+Lina
配置化层实验:增益很稳定
| Schedule | Testbed-A | Testbed-B |
|---|---|---|
| Tutel | 1.00x | 1.00x |
| Tutel-Improved | 1.09x | 1.08x |
| FSMoE-No-IIO | 1.12x | 1.16x |
| FSMoE | 1.18x | 1.22x |
Tutel -> Tutel-Improved只多出约8%-9%,说明只 overlap non-MoE 部分不够。FSMoE-No-IIO -> FSMoE还能再涨,说明 inter/intra-node overlap 是真实贡献。- 这一页最重要的信息是: adaptive gradient partitioning + communication co-scheduling 都是有效增量。
端到端模型:对 DS-MoE 提升更明显
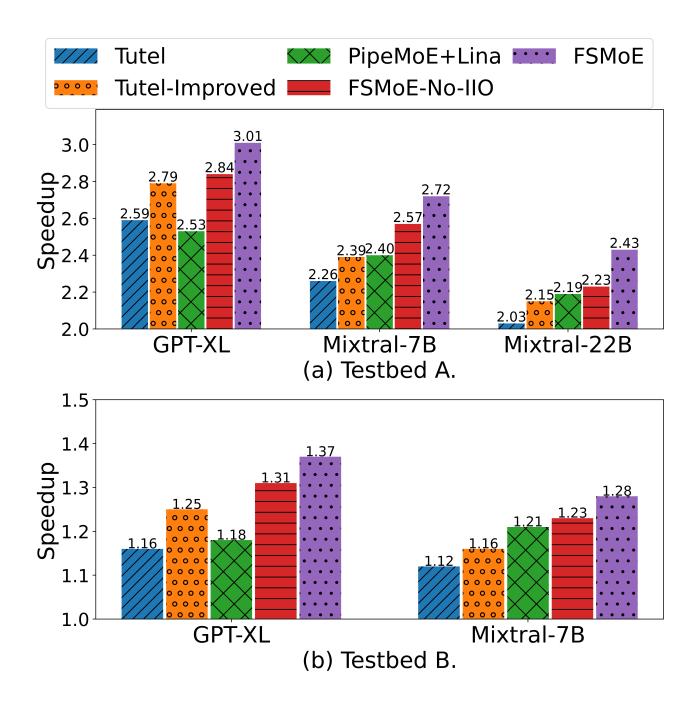
- 在真实 GPT2/Mixtral 模型上,FSMoE 相对
DS-MoE达到1.28x-3.01x。 - 相对
Tutel平均还能有1.19x,优于Tutel-Improved与PipeMoE+Lina。 - 主要原因: baseline 偏保守, 且 FSMoE 更好地隐藏
Gradient-AllReduce与多层通信。
鲁棒性:PP 与多种 gating 也成立
- 开启
PP (N_PP = 2)后,FSMoE 相对DS-MoE仍有2.46x平均提速。 - 在
Testbed-A上随L和P扩展,FSMoE 相对 Tutel 大致维持1.16x-1.20x。 - 对不同 gating function 的 GPT2-XL:
GShard 1.37x,X-MoE 1.42x,Sigmoid 1.37x,EC 1.33x。 - 所以这篇论文不是“只在一种 gate 或一种模型上有效”。
性能模型本身是可信的
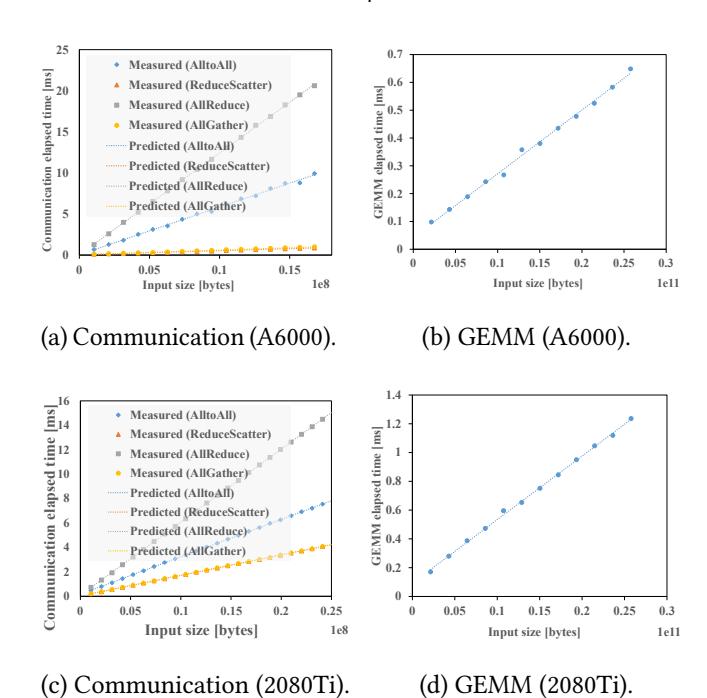
GEMM与四类 collective 都能被线性模型高精度拟合。- 文中
r^2很高:GEMM 0.9987,AllReduce 0.9999896,AlltoAll 0.9999。 - 这让“先 profiling 再求 schedule”成立,但 不代表跨平台永远稳定。
结论
- 贡献1: 用六模块抽象把 MoE implementation 与 scheduler 解耦,提升 framework flexibility。
- 贡献2: 联合调度
AlltoAll,AG/RS,expert compute,Gradient-AllReduce,把多层通信 overlap 做得更彻底。 - 贡献3: 用 phase-specific
r与 adaptive gradient partitioning,在真实 MoE 训练中拿到 稳定的系统级提速。
我的评价
- 最强点: 问题抓得准。它没有把瓶颈简化为“优化 AlltoAll”,而是看到 多并行范式下的联合调度问题。
- 最优雅的地方:
forward/backward分开找r,再把Gradient-AllReduce纳入同一优化框架。 - 脆弱假设: 高收益依赖
MP/ESP与节点拓扑对齐,以及线性性能模型足够稳定。 - 缺失实验: 没有在更现代的 H100 级多节点生产栈上证明收益,也缺少更工业化 baseline。
- 后续方向: 做 online model update,把 schedule 从 “训练前求一次” 扩展到 trace-driven 自适应调度。