FRUGAL
FRUGAL:在消费级 GPU 上高效训练 Embedding 模型
Minhui Xie, Shaoxun Zeng, Hao Guo, Shiwei Gao, Youyou Lu
Tsinghua University, Renmin University of China
ASPLOS 2025
Presenter: wzw
Date: 2026-04-03
TL;DR
- 瓶颈: 现有 embedding training 系统默认 GPU 间可高效
P2P / all-to-all;到了RTX 3090/4090这类 commodity GPU,通信必须经 host memory 绕行,吞吐明显掉队。 - 方法: FRUGAL 不再被动 remote fetch,而是把“别的 GPU 未来会读到的参数”提前 flush 到 host memory,再让 miss 直接经
UVA从 host 读。 - 结果: 在
8×RTX 3090上,相比DGL-KE / HugeCTR,吞吐分别最高提升1.5x/8.7x;相对 datacenter GPU 方案的 cost-effectiveness 提升4.0-4.3x。
为什么要看这个问题
- Embedding models 是推荐系统与图学习的主力负载,特点不是算力不够,而是 大表 + 稀疏随机访问 + 多 GPU cache 一致性 很麻烦。
- Commodity GPU 的吸引力非常现实: 更便宜、更容易买到,FP32/FP16 算力也不差。
- 但 embedding training 的关键不在裸 TFLOPS,而在 cache miss 怎么跨 GPU 取、更新怎么同步。
- 所以问题不是“3090 能不能跑”,而是 现有 datacenter-oriented 系统在 3090 上为什么会崩。
旧系统为什么在 3090 上失效
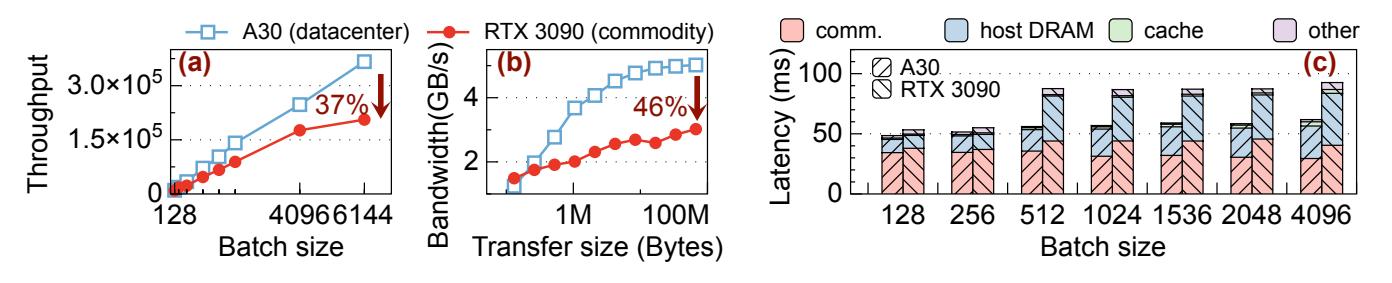
Figure 3给出的信号很直接: 把 HugeCTR 风格系统搬到RTX 3090,训练吞吐相对A30最多下降37%。- 根因有两个:
all-to-all带宽只有 datacenter GPU 的54%,而 cache miss 路径还引入 CPU 参与 + bounce buffer。 - 这说明 commodity GPU 的主矛盾不是算力,而是 GPU-GPU communication path 被 host memory 卡住。
关键观察:既然必须绕 host,就别临时绕
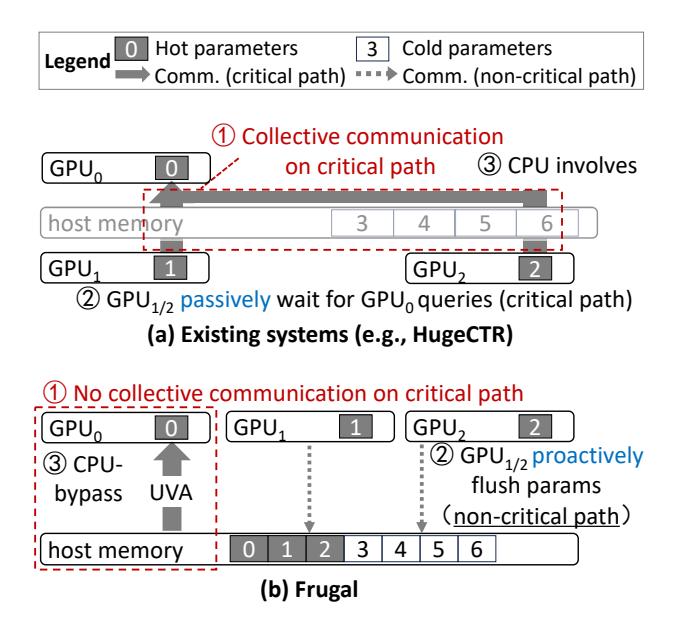
- Baseline 在查询时才走
GPU_i -> CPU/Host -> GPU_j,所以完整通信都暴露在 critical path。 - FRUGAL 把前半段
GPU -> host memory提前异步做掉。 - 于是 miss 时只剩
host -> GPU前台读取,代价更像读 host cacheline。
FRUGAL 全景图
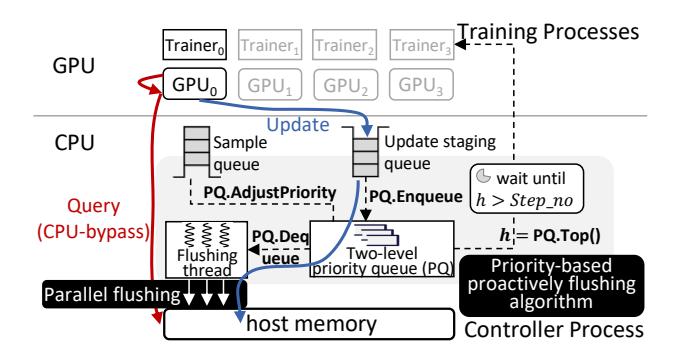
- Training processes 维护各自 GPU 的 private embedding cache。
- Controller process 维护 host memory 全量参数,并负责
sample queue、update staging queue、priority queue和后台 flushing threads。 - 前向 miss 直接经
UVA读 host;反向 update 先写本地 cache,再异步刷回 host。
机制 1:优先级主动刷回
- 问题: 若所有 update 都
write-through到 host,foreground training 会被 flush stall 拖住。 - 每个参数维护一个
g-entry,记录未来读集合R set与待提交写集合W set。 - 核心直觉: 快要被读到的脏参数先 flush,远期参数延后 flush。
P2F 的规则
- 规则可压缩成一句话: 若
W set非空,则priority = min(R set);否则priority = ∞。 - 训练线程只有在
front(PQ) > s时才允许进入 steps。 - 因此 correctness 被压缩成一个很便宜的数值条件,而不是 per-key 全局同步。
一次训练步如何流动
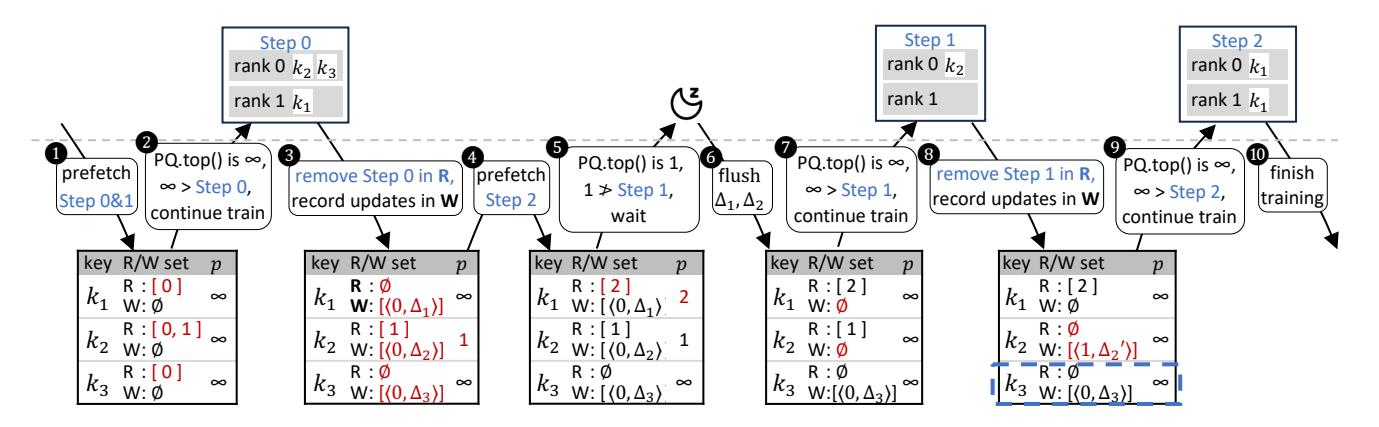
- 训练前,controller 先 lookahead 未来
L步,把将访问的 key 填进各 g-entry 的R set。 - 只有当
front(PQ) > s时,训练线程才允许进入 steps,从而避免读到 stale host parameter。 - Step 完成后,gradient 进入
W set;而 远期才会再访问的 key 可以延后 flush,所以前台 stall 大幅下降。
机制 2:Two-level PQ
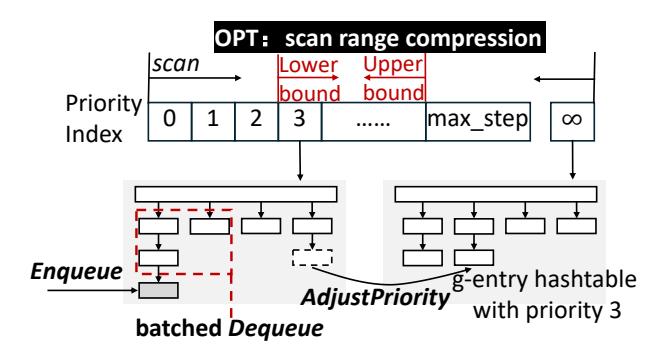
- 问题是:
P^2F要高频做enqueue / dequeue / adjustPriority,传统 concurrent heap 有O(log N)复杂度和 near-root contention。 - FRUGAL 利用 priority 就是 step number、且单调不减,把 PQ 做成 priority index + lock-free hash table。
- 结果是 PQ 相关操作近似
O(1),并且更适合多 flushing threads 并发访问。
系统代价与适用边界
- 不是额外搬运: 论文强调,对 commodity GPU 而言,跨 GPU 数据本来就要 bounce 到 host;FRUGAL主要是重排时间,不是增加层级。
- 需要强 host side: 实验机是
1.5TB DRAM,controller 还要跑 prefetch thread 与8-12个 flushing threads。 - 收益边界很清楚: 最适合
同步训练 + 稀疏 embedding access + 单机 PCIe commodity GPU。 - 不解决的问题: 作者明确不考虑 cross-server distributed training;对 dense model 或高端互联 GPU,这套设计价值会下降。
方法学
- 平台:
2× Intel Gold 6130 + 1.5TB DRAM + 8× RTX 3090,每卡PCIe 4.0×16。 - KG 工作负载:
FB15k / Freebase / WikiKG + TransE,embedding dim400。 - REC 工作负载:
Avazu / Criteo / CriteoTB + DLRM,embedding dim32。 - Baselines:
DGL-KE / DGL-KE-cached / PyTorch / HugeCTR / Frugal-Sync。 - 默认配置: cache ratio
5%,默认全卡,通常使用8个 flushing threads。
主结果:KG 模型
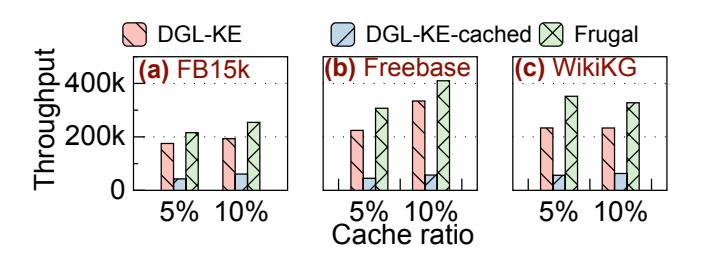
- 相比
DGL-KE,FRUGAL 吞吐提升1.2-1.5x;相比DGL-KE-cached,提升4.1-7.1x。 - 反常但很重要的一点是:
DGL-KE-cached在 commodity GPU 上常常比 vanilla DGL-KE 还慢。 - 这正说明 baseline 的 multi-GPU cache 本身没错,错的是它依赖的 cross-GPU communication model 不适合 3090。
主结果:REC 模型
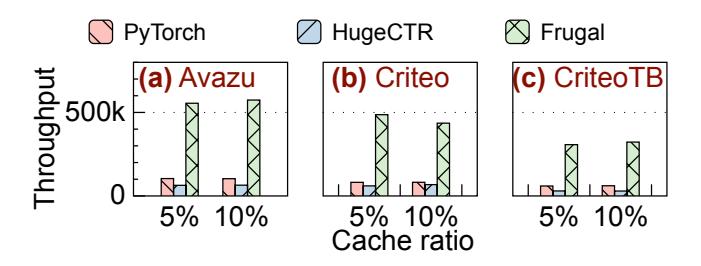
- 对
Avazu / Criteo / CriteoTB,FRUGAL 相比PyTorch达4.9-7.4x,相比HugeCTR达6.1-8.7x。 - 提升比 KG 更大,因为 REC 更 memory-intensive,remote cache query 更频繁。
- 这页是论文最强结果: 不是略优,而是把 commodity GPU 从“不太适合缓存式训练”拉回“非常有性价比”。
为什么它真的更快
| 机制 | 指标 | 收益 |
|---|---|---|
P^2F vs SyncFlushing |
training stall time | 34-101x 更低 |
P^2F vs SyncFlushing |
end-to-end throughput | 3.5-5.3x |
UVA host access |
host access latency | 3.1-3.4x 更低 |
| Two-level PQ vs TreeHeap | FRUGAL throughput | 2.1-3.3x |
- 所以 FRUGAL 的收益不是一个单一 trick,而是三段叠加: 主动刷回、CPU-bypass 读取、可扩展 PQ。
- 论文最可信的地方也在这里: 它把最终吞吐拆成可解释的局部因果链,而不是只给几根高柱子。
性价比与规模趋势
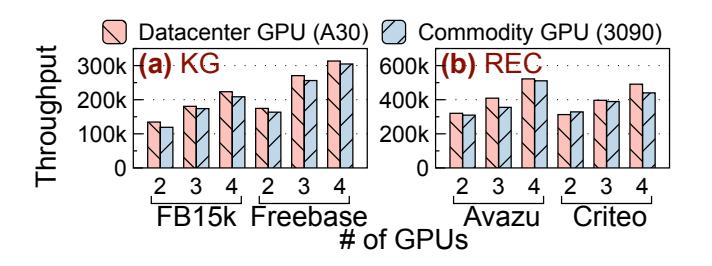
- FRUGAL 在
RTX 3090上做到约89%-97%的A30吞吐,但卡价仅约$1310 vs $5885,因此性价比提升4.0-4.3x。 - 论文同时报告其扩展性优于 baseline,但受限于 commodity GPU 通信硬件,仍非线性 scaling。
我的结论
- 最强点: 它抓到的根因很准, cache coherence path 必须围绕 host memory 重写。
- 最值得记住:
proactively flushing + UVA host read + two-level PQ三件事必须一起看。 - 主要保留意见: 缺少最终 accuracy 曲线,且强依赖 lookahead、host DRAM 和单机场景。
- 一句话: 这是一个非常对症、非常务实的 commodity-GPU embedding training redesign。