FIGLUT
FIGLUT:面向 FP-INT GEMM 的高能效查表加速器
Gunho Park, Hyeokjun Kwon, Jiwoo Kim, Jeongin Bae, Baeseong Park, Dongsoo Lee, Youngjoo Lee
POSTECH, NAVER Cloud
HPCA 2025
Presenter: wzw
Date: 2026-03-24
三句话看懂
- 瓶颈:
weight-only quantization节省了权重存储,但执行端仍卡在FP activation × INT weight,GPU 往往退回dequantize + FP-FP compute。 - 方法: FIGLUT 把局部内积改写成
LUT read + RAC accumulation,再用FFLUT / hFFLUT从硬件结构上消掉 bank conflict。 - 结果: 同样
Q3权重下,较 SOTA 提升59% TOPS/W且 perplexity 降20%;同等 perplexity 下,Q2.4方案能效再高98%。
问题在哪
LLM inference已经明显 memory-bound,weight-only的目标本来是减少 DRAM footprint 和 bandwidth。- 但激活通常保留
FP16/BF16,所以真正执行的是FP-INT GEMM,这不是通用 GPU 最擅长的 datapath。 - 现有方案都不理想:
GPU仍依赖FP-FP;iFPU支持 mixed precision 但复杂度随位宽线性涨;FIGNA更高效,但基本锁在固定精度和 uniform quantization。
GPU LUT 为何失效
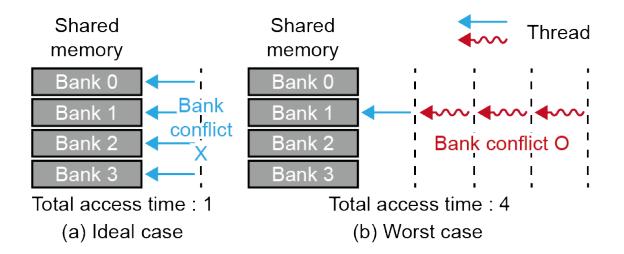
- LUT-GEMM 的直觉并不新,但在 GPU shared memory 上会遇到 bank conflict。
- LUT 构建阶段可顺序安排访问;真正读表时,weight pattern 是随机的,线程容易同时打到同一 bank。
- 所以论文的重点不是“想到查表”,而是 把查表做成 conflict-free hardware primitive。
核心观察
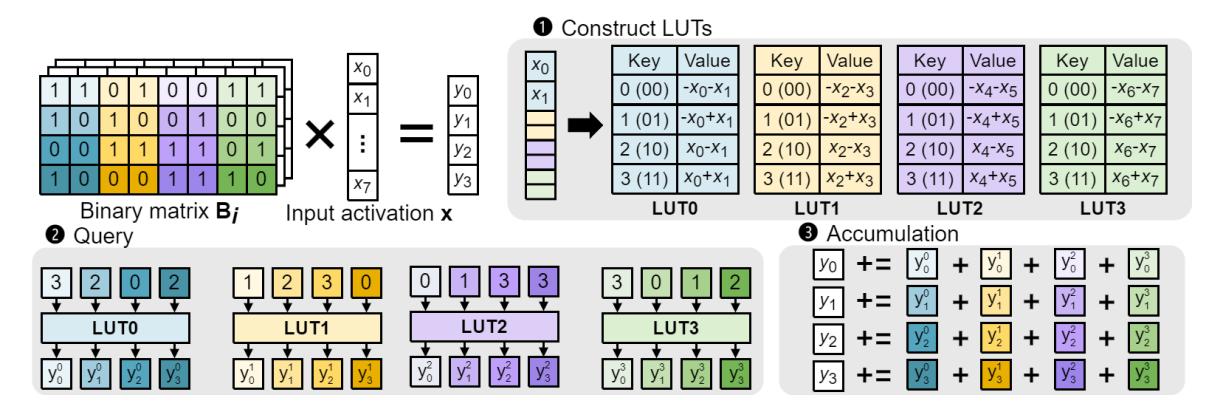
- 对
BCQ / binary-coded权重,局部内积本质上是若干输入激活的 正负组合。 - 若每次取
μ个 binary 权重作为 key,就可预存2^μ个结果;于是复杂度可从O(mnkq)摊到O(mnkq/μ)。
整体架构
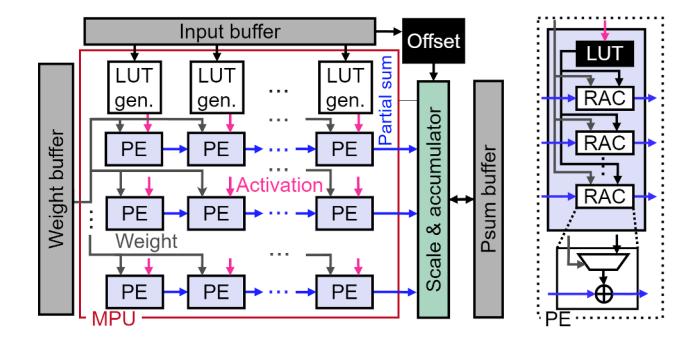
- 总体仍是 2D systolic array,但 PE 内部从
MAC改成了1 LUT + k RACs。 LUT generator在线接收μ个输入生成 partial sums;RAC只负责 按 weight pattern 查表并累加。
一次 GEMM 如何跑
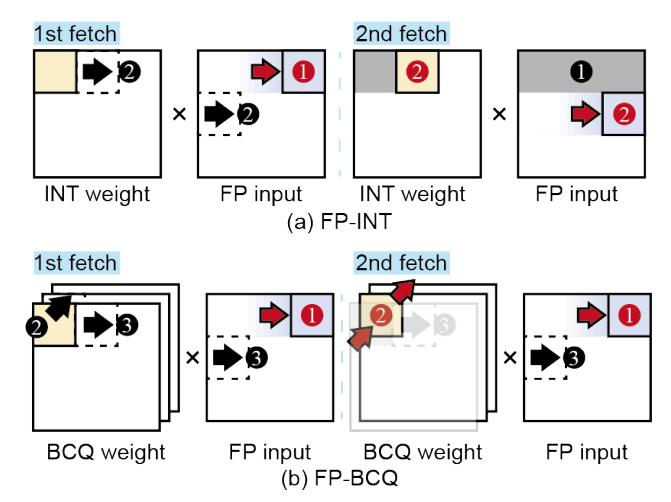
- 数据流仍是 weight-stationary,但与 FIGNA 不同,FIGLUT 处理的是
q个 binary bit-plane。 - 生命周期很直接: 取当前 bit-plane 的 weight pattern 作为 key,
k个 RAC 并发查表并沿列累加,最后再乘对应 scale 并加 offset。
FFLUT 消除冲突
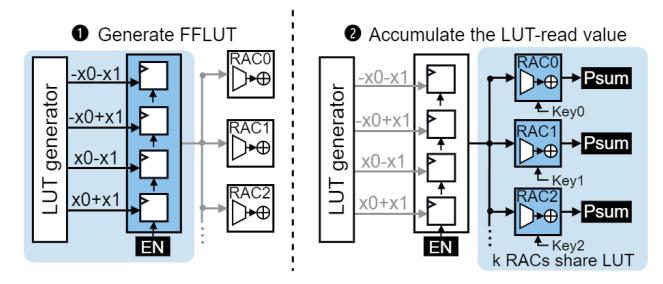
- 传统
Register File LUT受限于 read/write ports,不适合大量并发随机读。 - FIGLUT 用 FFLUT:
flip-flop bundle + dedicated multiplexers。 - 好处是一个共享 LUT 可被多个
RAC同时访问,不再受 bank / port contention 约束。
μ 怎么选
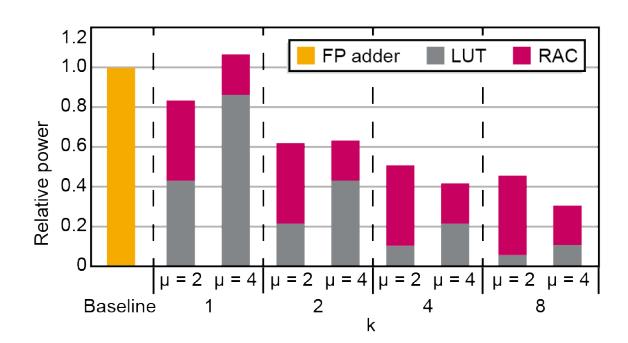
μ大,单次 read 替代的加法更多;但 LUT 容量按2^μ增长,μ=8已经过大。- 论文最终保留
μ=2与μ=4两档,原因是更大的 LUT 已经不值得。 - 最终选择是
μ=4,因为在共享足够多 RAC 时,较大的 LUT 成本能被摊销掉。
k 怎么选
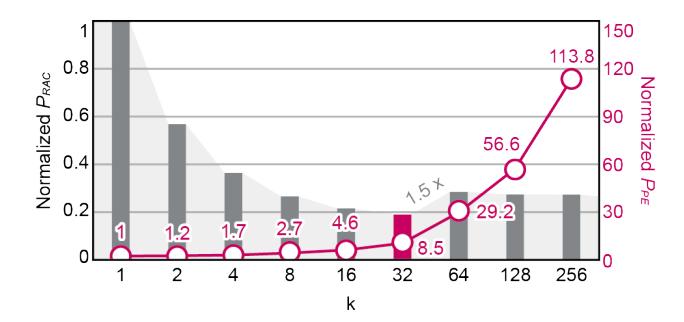
k大,更多 RAC 共享同一 LUT,LUT 数量会下降,摊销更好。- 但 fan-out 会抬高每个 RAC 的功耗,所以
P_RAC不是单调下降。 - 论文的最终配置是
k=32,这是共享收益与 wire/power 代价之间的折中点。
hFFLUT 再砍一半
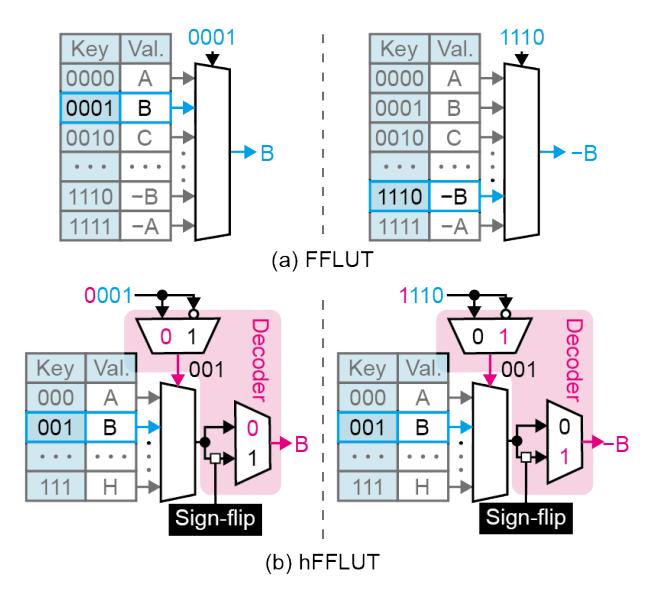
- LUT 值关于符号存在 vertical symmetry,所以无需把正负两半都存下来。
hFFLUT只保留一半表项,利用MSB选择 key 并决定是否 sign-flip。- 归一化功耗上,
FFLUT LUT = 1.000,hFFLUT LUT = 0.494,额外MUX+Decoder = 0.005。
生成器优化
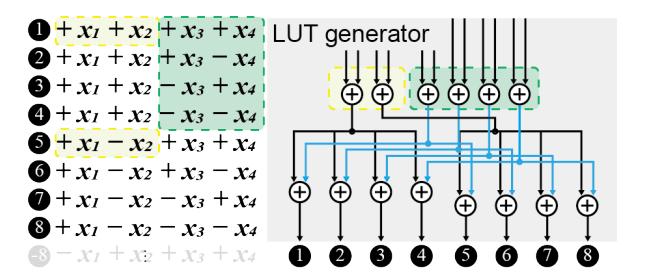
hFFLUT让生成器只需计算半张表,论文报告 additions 减少 42%。- 对
μ=4,作者报告完整生成 hFFLUT 需要 14 次加法,而不是对每个结果都暴力重算。
系统集成
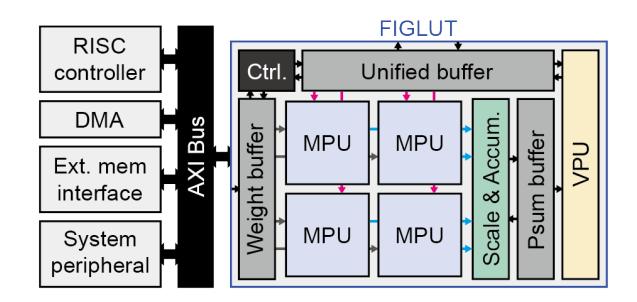
- 系统侧采用 shared memory + AXI + double buffering,重点不是系统创新,而是把 MPU 接进常规 SoC。
- 这也说明论文把主要工程预算押在 PE 内 datapath,而不是 host-runtime 协同。
实验方法
- Models:
OPT-350M ~ OPT-30B,重点展示OPT-6.7B。 - Accuracy setup:
WikiText-2,FP16 activation + Q4 weight,accumulation 用FP32。 - Hardware setup:
28nm CMOS @ 100MHz,Synopsys DC 综合;片外 DRAM 用CACTI建模。 - Baselines:
FPE,iFPU,FIGNA,FIGLUT-F,FIGLUT-I。 - 公平性: 对齐相同最大
TOPS,再比较TOPS/W、TOPS/mm^2和 perplexity。
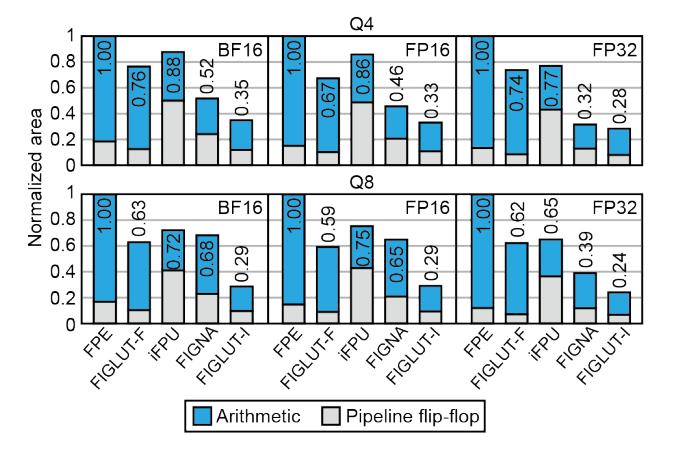
精度与面积
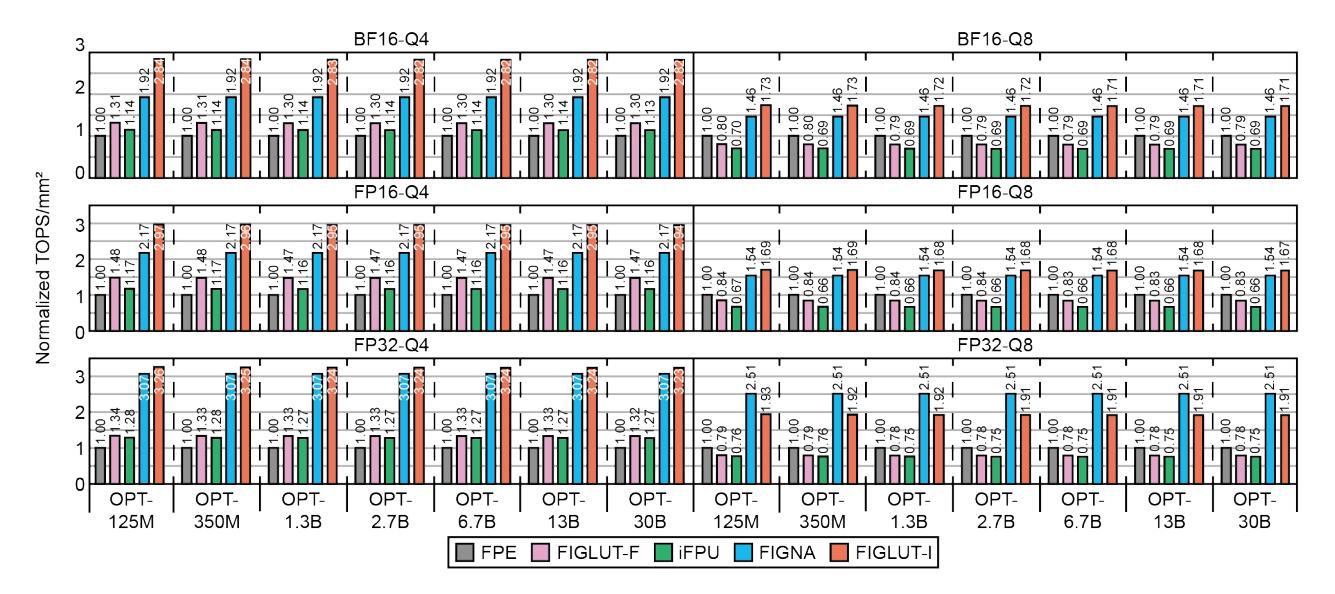
- 数值精度基本不掉: 在
OPT-6.7B上,GPU / FIGLUT-F / FIGLUT-I的 perplexity 都约为24.13。 - 面积方面,FIGLUT 用更小的
2 × 16 × 4MPU,论文报告 area efficiency 最高约1.5×。
能效结果
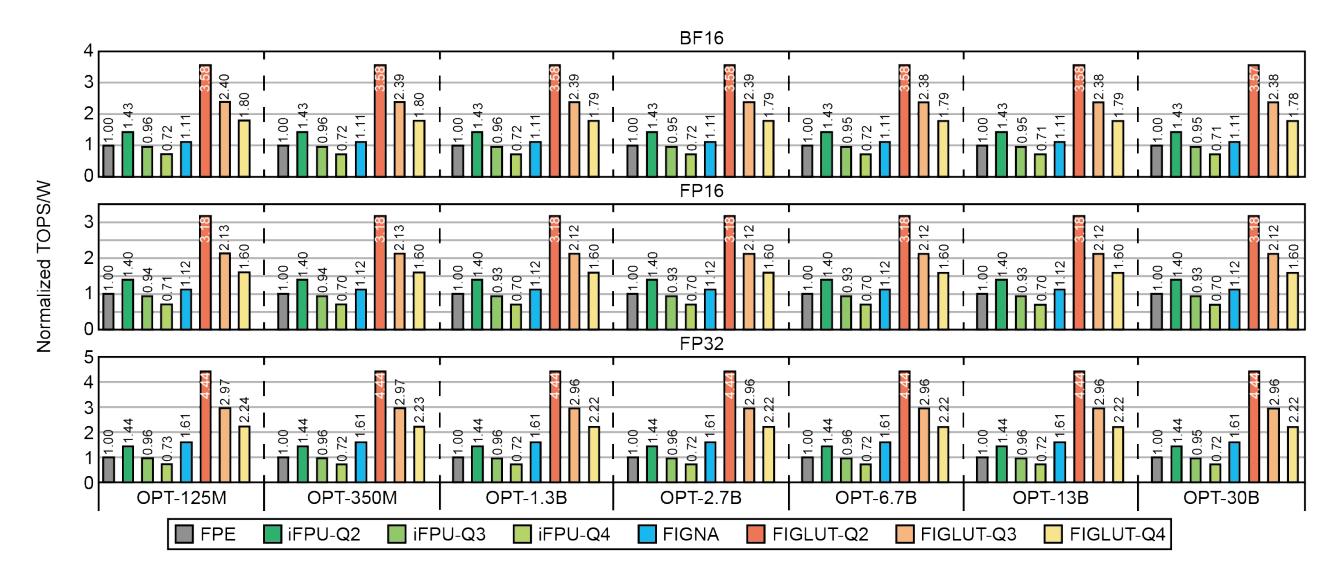
- 固定
FP16-Q4且对齐同样0.14 TOPS时,iFPU / FIGNA / FIGLUT分别是0.21 / 0.33 / 0.47 TOPS/W。 - 混合精度下优势继续放大:
Q4高1.2×,Q3高1.6×。 - 在相同 perplexity 目标下,
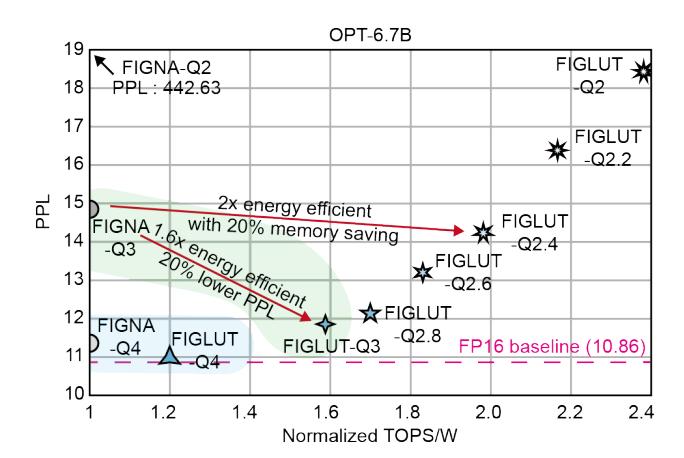
FIGLUT-Q2.4相对FIGNA-Q3还能做到1.98×能效,且模型大小再减20%。
为什么它会赢
- 算术换查表: 把 repeated add/sub 变成 single read,是最直接的 compute simplification。
- FFLUT/hFFLUT: 解决的不是“容量”一个问题,而是 concurrency + power 两个问题。
- bit-serial 甜蜜点明确: 位宽越低,FIGLUT 的周期和能耗优势越明显,所以特别契合当前
sub-4-bit LLM inference。 - 它的边界也很清楚: 一旦往
Q8甚至更高精度走,μ需要继续增大,LUT 与 generator 开销会快速变差。
结论
- FIGLUT 的真实贡献是把
LUT-based FP-INT GEMM从 kernel idea 推进成 可布局布线的 accelerator datapath。 - 关键结构就是三件事:
RAC取代MAC,FFLUT消除冲突,hFFLUT把 LUT 主体再砍半。 - 如果只记一句话,就是: 在 sub-4-bit LLM 推理里,FIGLUT 用 structure-aware lookup 打破了 bit-serial 的一部分效率瓶颈。
我的评价
- 最强点: 不是 headline 数字,而是论文真的分析了
μ / k / fan-out / P&R power,工程说服力比很多 accelerator paper 强。 - 主要局限: Fig.17 里 FIGLUT 和 FIGNA 使用的量化方法不同,mixed-precision 优势里掺杂了算法收益。
- 缺的实验 / 后续:
batch=1decode 下LUT generation占比还没拆清;若走向更高精度,需要hierarchical LUT或 layer-wise 自适应μ。