Fast On-device LLM Inference with NPUs
llm.npu:用手机 NPU 加速端侧 LLM Prefill
Daliang Xu, Hao Zhang, Liming Yang, Ruiqi Liu, Gang Huang, Mengwei Xu, Xuanzhe Liu
Peking University, Beijing University of Posts and Telecommunications
ASPLOS 2025
Presenter: wzw
Date: 2026-04-06
TL;DR
- 瓶颈: 端侧真实 workload 往往不是
decode-bound,而是prefill-bound。 - 方法: llm.npu 用 chunk-sharing graph + shadow outlier execution + out-of-order subgraph scheduling,把
INT8 MatMul主路径推给手机 NPU。 - 结果: 平均
22.4xprefill speedup、30.7xenergy saving,1024-token 场景最高43.6x提速。
为什么先救 Prefill
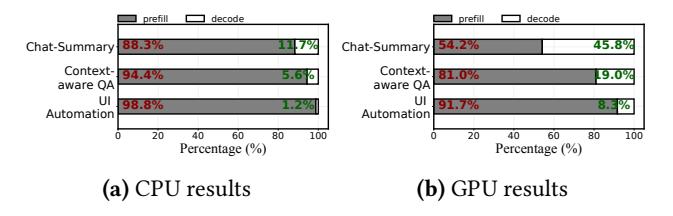
- Figure 1 的关键信号很直接: UI automation、邮件回复、chat summary 里,prefill 占总时延
88.3%–98.8%(CPU)。 - 就算换成 mobile GPU,prefill 仍占
54.2%–91.7%;随着 prompt 变长,占比还会继续上升。 - 论文的选题判断因此很准: 端侧长 prompt LLM,先救 prefill 比先救 decode 更值钱。
NPU 很强但不能直上
| 路径 | 数据类型 | 延迟 | 含义 |
|---|---|---|---|
| NPU | INT8 | 0.9 ms |
baseline |
| CPU | INT8 | 4.2 ms |
慢 4.6x |
| GPU | FP16 | 1.7 ms |
慢 1.9x |
| NPU | FP16 | 252 ms |
慢 193x |
- Mobile NPU 适合 INT8 SIMD MatMul,但对 FP16 极弱。
- LLM 直接上 NPU 会遇到三道鸿沟: dynamic prompt shape、outlier 破坏 per-tensor quantization、Attention/Norm 仍要 float。
- 对 Gemma-2B,单次 graph build 约
360 ms,graph optimization 约11.54 s;若每个 prompt length 都重编译,系统直接不可用。
llm.npu 总体结构
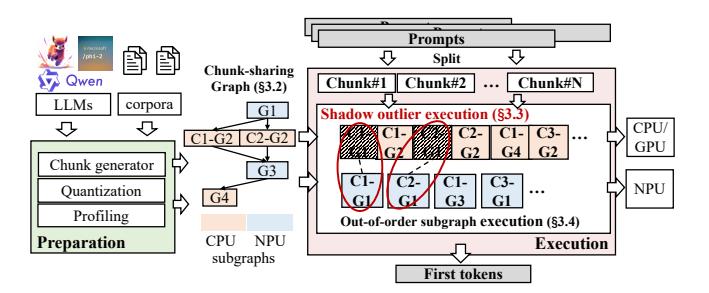
- Preparation:
W8A8量化,预构建 fixed-length chunk graphs,离线 profile outlier 与子图时延。 - Execution:
Linear/FFN走 NPU,Attention/LayerNorm/outlier compensation走 CPU/GPU,再用调度把 bubble 压缩掉。 - 核心目标不是 “all-on-NPU”,而是 最大化 NPU-friendly 工作占比,同时控制异构边界成本。
机制1:Chunk-sharing
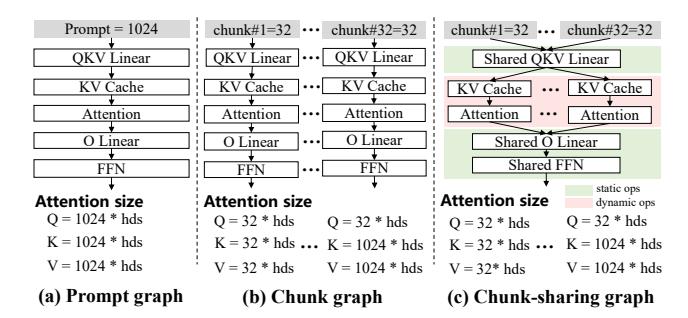
- 先把变长 prompt 切成固定长度 chunk,保留 decoder-only 的因果依赖。
- 再把子图拆成 static operators 与 dynamic operators: 前者跨 chunk 共享,后者按 chunk 单独保留。
- 这样解决的不是算子速度,而是 NPU graph 准备成本与常驻内存爆炸。
为什么它有效
- 在 Qwen1.5-1.8B 上,
144个子图里有120个可以共享。 - 当
prompt=1024、chunk=256时,chunk-sharing graph 最多可减少75%内存,即7.2 GB。 - 论文经验上把
chunk length选为256,平衡 NPU 利用率与 padding 浪费。 - 这一步让 “dynamic prompt 触发反复 graph rebuild” 变成 “固定 graph 复用 + 少量动态 attention path”。
机制2:Shadow outlier
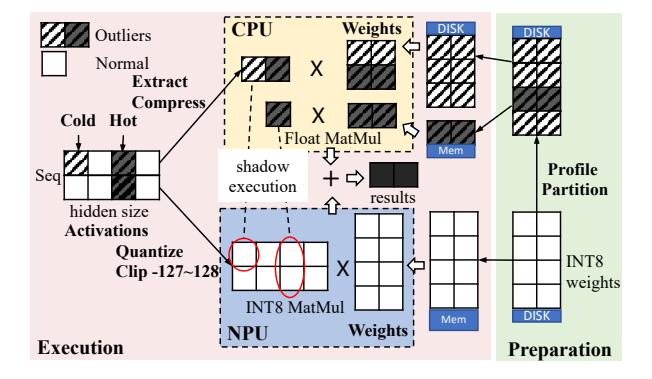
- 论文不做
per-group MatMul,而是把超出量化范围的极少数 activation outlier 抽出,交给 CPU/GPU 补算。 - 主路径仍保持 NPU 上的 per-tensor
W8A8MatMul,从而避免 group quantization 在手机 NPU 上的巨大低效。 - 直觉上它是在把一个“全张量精度问题”改写成“极少数通道的稀疏补偿问题”。
为什么 outlier 路线可行
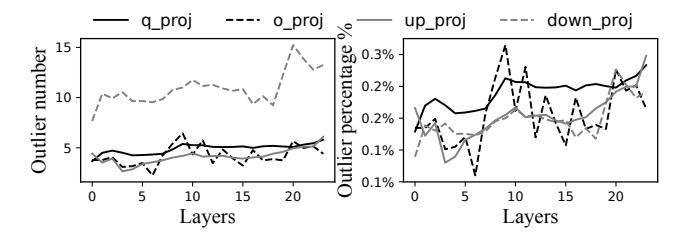
- Figure 10 显示单次推理通常只有
0.1%–0.3%channel 含 outlier,也就是约5–15个通道。 - 因此 CPU shadow execution 足够稀疏,理论上可以被 NPU 主路径隐藏。
- 为降低副作用,作者再加两步: hot-channel caching 与 top-85% unimportant layers pruning。
Shadow 的代价也不小
- 若简单实现,CPU 侧要再保留一份 MatMul 权重,内存几乎翻倍。
- CPU-NPU reduction synchronization 甚至可吃掉
29.7%end-to-end latency 和20.1%energy。 - 论文通过 “少量 hot channels 常驻 + 其余权重按需取回” 把 shadow memory overhead 再降
34.3%。 - 所以这个机制真正聪明之处不是公式,而是 把稀疏补偿工程化到可部署。
机制3:乱序调度
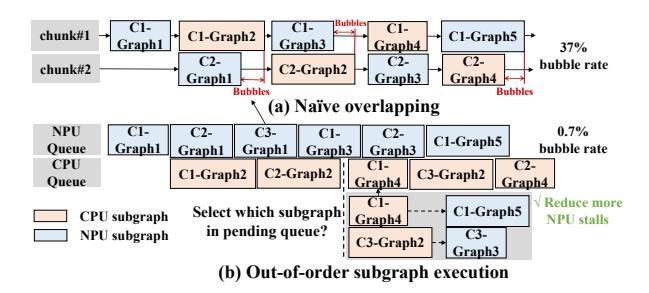
- 简单 overlap CPU/GPU 与 NPU 还不够,论文测得 critical-path bubble rate 高达
37%。 - 做法是把每个 chunk 再切成 subgraph;只要依赖满足,就允许后续 chunk 的 ready subgraph 提前执行。
- heuristic 很 systems: 优先减少 NPU stall,因为 prefill 阶段 NPU 才是主要关键路径。
一次 Prefill 如何流动
- 收到变长 prompt 后,runtime 先按固定
chunk=256切分请求。 - 每个 chunk 进入共享的 static subgraph;attention 等 dynamic path 选择对应维度子图。
Linear/FFN等 INT8-friendly 子图送入 NPU;Attention/Norm/outlier走 CPU/GPU。- 调度器不按 chunk 严格顺序,而是谁更能减少 NPU stall 就先跑谁。
- 最终把每个 chunk 的结果因果拼接,得到正确的 prefill 输出。
系统开销与代价
| 项目 | 结果 | 含义 |
|---|---|---|
| 代码实现 | 10K+ C/C++/asm |
强工程系统 |
| 总内存 | 最多 1.32x baseline |
不是轻量部署 |
| shadow 额外内存 | 0.6%–1% 总内存 |
算法本身开销小 |
| GPU-NPU 协同 | E2E 再降 80–90 ms |
但当前未完整实现 |
| 适配性 | 绑定 QNN + Hexagon |
跨平台迁移有成本 |
- 这篇论文付出的“硬件账单”不是 area,而是 memory、runtime complexity、backend 绑定与实现复杂度。
实验方法
- 设备: Redmi K70 Pro (
Snapdragon 8 Gen 3, 24GB) 与 Redmi K60 Pro (Snapdragon 8 Gen 2, 16GB)。 - 模型:
Qwen1.5-1.8B,Gemma-2B,Phi-2-2.7B,LLaMA-2-7B,Mistral-7B。 - Baseline:
llama.cpp,MNN,TFLite,MLC-LLM,PowerInfer-v2。 - 任务: LongBench、DroidTask、Persona-Chat;accuracy 用
LAMBADA/MMLU/WinoGrande/OpenBookQA/HellaSwag。 - 默认设置:
chunk=256,outlier pruning rate=85%,decode 仍走 MLLM CPU backend。
Prefill 性能很强
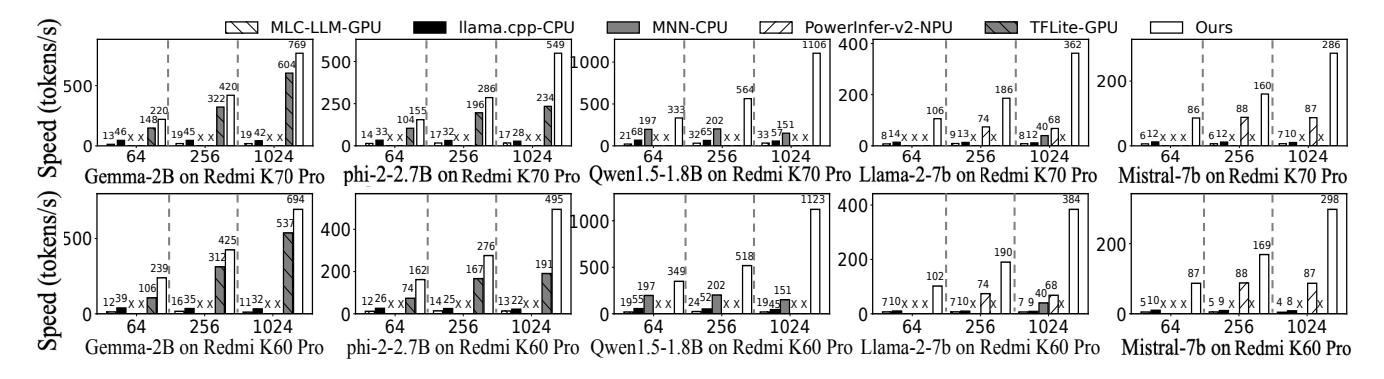
- 1024-token 场景下,llm.npu 相比
llama.cpp-CPU / MNN-CPU / MLC-GPU / TFLite-GPU可达7.3x–43.6xspeedup。 - 对同样用 NPU 的
PowerInfer-v2,仍有3.28x–5.6x优势,说明赢点不是 “用了 NPU” 本身,而是三层重构。 - prompt 越长收益越大,和论文对 prefill bottleneck 的分析完全一致。
节能也成立

- 在 Redmi K60 Pro 上,1024-token 场景对
llama.cpp-CPU / MLC-GPU / TFLite-GPU可节能1.85x–59.52x。 - 这说明论文不是靠“同时开更多硬件单元硬堆性能”,而是在利用 NPU 的整数能效优势。
- 对端侧系统来说,这个结果和 speedup 一样关键,因为电量与发热直接影响可部署性。
E2E 与精度怎么看
- LongBench / DroidTask: prompt 长、输出短,端到端收益明显,可到
1.4x–32.8x。 - Persona-Chat: 输出 token 多,decode 占比高,因此 llm.npu 对
PowerInfer-v2/TFLite只剩约1.1x优势。 - Accuracy: 相对 FP16,llm.npu 在五个 benchmark 上平均退化约
-1.2% / -0.0% / -0.1% / -0.5% / +0.2%。 - 相比之下,
SmoothQuant平均可掉-5.1%到-14.9%,K-Quant最差平均可到-31.3%。
消融说明真因
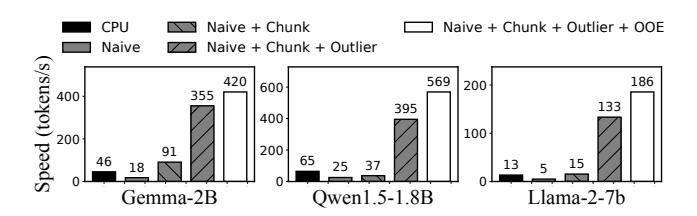
- naive NPU offload 反而会 慢
2.55x–2.68x,说明这不是“把算子搬去 NPU”就自然成立的系统。 chunk-sharing graph贡献1.46x–5.09x,shadow outlier再给3.91x–8.68x。out-of-order execution继续把 prefill latency 降18%–44%,负责榨干异构协同效率。
我的评价
- 优点: 问题画像很准,三层机制正好对应 dynamic shape、outlier quantization、异构调度三道鸿沟。
- 边界: 它更像 “Fast On-device LLM Prefill with NPUs”,并没有真正解决 decode。
- 代价: 强绑定
Qualcomm Hexagon + QNN,整体内存最高仍有1.32x。 - 后续: 做完整 GPU-NPU 协同,再叠加
prefix cache / KV cache / speculative decoding。