Efficient FP Compression
面向 CPU/GPU 的科学浮点数据高效无损压缩
Paper: Efficient Lossless Compression of Scientific Floating-Point Data on CPUs and GPUs
Noushin Azami, Alex Fallin, Martin Burtscher
Texas State University
ASPLOS 2025
Presenter: wzw
Date: 2026-04-27
三句话看懂
- 瓶颈: scientific data compression 不是只拼
ratio或只拼throughput;真实系统要同时满足 高吞吐 + 高压缩率 + CPU/GPU bitstream 兼容。 - 方法: 作者把 IEEE 754 bit-pattern 当整数处理,围绕
DIFFMS / BIT / RZE / FCM / RAZE / RARE设计四条面向FP32/FP64、speed/ratio的并行变换链。 - 结果: 在
RTX 4090上,SPspeed达到518 GB/s几何平均压缩吞吐;DPratio在FP64上给出最强 GPU 侧压缩率,同时四个方案几乎都在 Pareto front 上。
背景:问题到底难在哪
- 科学模拟、光源、粒子实验的数据规模持续增大,瓶颈不再只是算力,而是 storage / transfer / I/O bandwidth。
- 这类场景很多时候必须 lossless;误差注入会直接影响物理结论、工程设计或后续分析可信度。
- 真正麻烦的是 heterogeneous workflow:数据可能在 GPU 上生成并压缩,却要在 CPU 上解压分析。
- 所以 paper 优化目标不是单指标冠军,而是 cross-device usable compression。
瓶颈:现有方案各强一边
- 高压缩率方案通常依赖更复杂的 predictor / entropy coding,ratio 高但速度慢。
- 高吞吐方案往往更像快速 reformatting,速度高但压缩率不够。
- 大多数实现还只支持单设备,导致“GPU 上压、CPU 上解”根本不可用。
- 论文的核心判断是:如果 compressor 本身成为新 bottleneck,它就没有系统价值。
关键观察
- Observation 1: scientific floating-point data 往往较平滑,相邻值 exponent 接近,做整数差分后容易得到 小幅度残差。
- Observation 2: 这些残差经格式变换后,会出现大量 leading zeros、重复高位模式、短距离重复值。
- Observation 3:
FP32与FP64的最佳 ratio 路线不同;FP64mantissa 更随机,不能简单把FP32方案放大。 - 核心洞察: 与其上来就做复杂 coder,不如先把冗余重排成 GPU-friendly primitives 能吃掉的形态。
总体方案
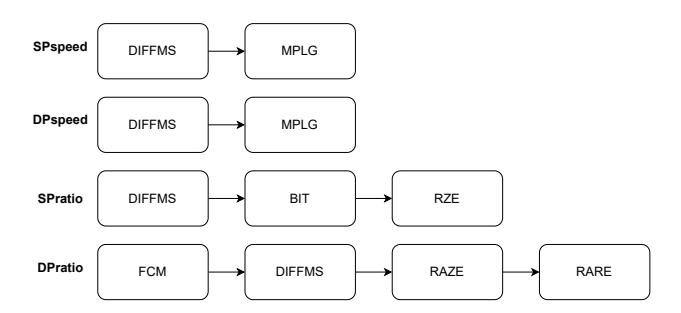
- 四条链分别服务
FP32/FP64与speed/ratio两种目标,而不是追求一个万能 pipeline。 - 除
FCM外,所有 stage 都按16 KB chunk独立处理,因此天然适合OpenMP与CUDA block并行。 - 这张图最重要的信息是:speed 模式只保留两级快变换,ratio 模式再逐层榨干冗余。
机制 1:DIFFMS + MPLG
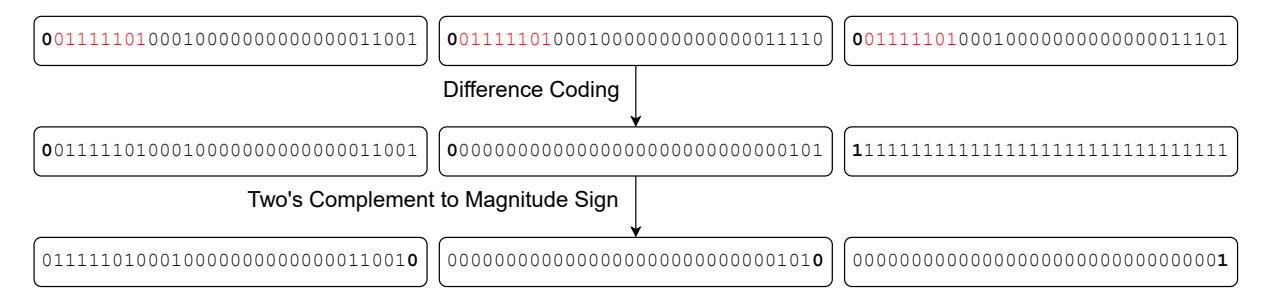
DIFFMS先做整数差分,再把 two's-complement 变成 magnitude-sign,把正负残差都尽量拉成 leading-zero-rich 表示。- 公式很简单但很关键:
(data << 1) xor (data >> (w-1)),完全由整数操作构成,易于 CPU/GPU 高吞吐实现。 MPLG再按 chunk / subchunk 消掉公共 leading zeros,所以SPspeed/DPspeed的思路本质上是 极简但极快。
机制 2:BIT + RZE

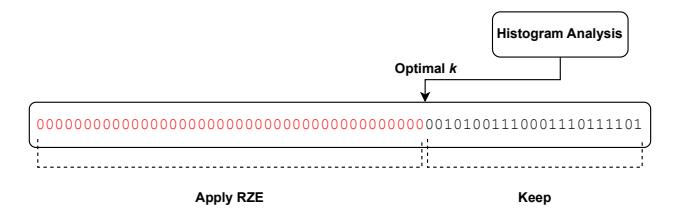
BIT把每个值的同一 bit 位收拢到一起,使高位零在输出前段形成长零串。RZE再按 字节 建 bitmap,删除零字节,只输出非零字节与压缩后的 bitmap。- 真正巧妙的是 bitmap 会被继续递归压缩,从
16384 -> 2048 -> 256 -> 32 bits,因此SPratio的 ratio 明显高于 speed 路线。
机制 3:FCM + RAZE/RARE
DPratio不能直接照搬SPratio,因为FP64的低位随机性更强,bit shuffle 的收益被噪声吃掉。- 作者用
FCM先把“重复值定位”改写成hash + index排序问题,避免传统FPC的 per-thread hash table 无法上 GPU。 RAZE/RARE则自适应选择 top-kbits,只压高位、保留低位原样,承认低位随机性而不是硬压。
一个 chunk 怎么走
- Step 1: 输入按 bit-pattern 读成
32/64-bit整数;除FCM外,后续都在16 KB chunk内独立运行。 - Step 2:
speed路线走DIFFMS -> MPLG,目标是最短数据路径和最高并行吞吐。 - Step 3:
ratio路线继续追加BIT/RZE或FCM/RAZE/RARE,用更多中间处理换更高压缩率。 - Step 4: 反向解压按相反顺序执行;同一 bitstream 可在 CPU 与 GPU 双端兼容解码。
工程账单
- 无专用硬件账单: 这是纯软件 compressor,但成本转成了
sort / prefix sum / shared memory / output packing。 DPratio最贵:FCM会生成两个中间数组,使临时数据约为2x input,而且编码路径被排序主导。- 兼容性有代价: 作者坚持输出 contiguous block,所以吞吐数字比只吐分散 chunks 的
nvCOMP更保守。 - 实现风险: 若想吃满性能,chunk 调度、warp shuffle 和 shared-memory 布局都不能粗糙。
方法学
- 对比对象: 共
19个 compressor,覆盖11 GPU+9 CPU实现;其中Ndzip是少数也支持 CPU/GPU 兼容的直接对手。 - 数据集:
90个FP32文件 +20个FP64文件,来自SDRBench和额外 scientific inputs。 - 平台:
Ryzen Threadripper 2950X、dual Xeon Gold 6226R、RTX 4090、A100。 - 指标: 压缩率、压缩吞吐、解压吞吐;结果主要用 Pareto front 表达,而不是只报一个平均值。
FP32 结果:GPU 上平衡最好
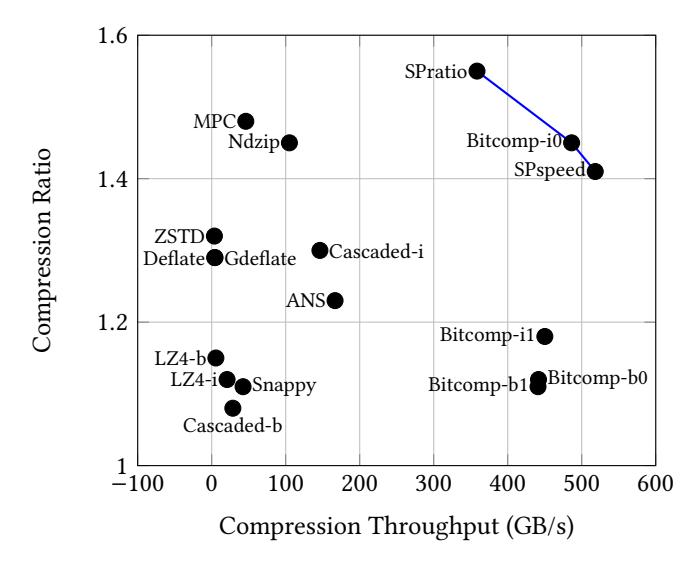
- 横轴是 throughput,纵轴是 ratio;越右上越好,图中还标了 Pareto front。
- 在
RTX 4090上,SPspeed的几何平均达到518 GB/s,ratio 为1.41。 - Pareto front 上同时出现
SPratio、SPspeed和Bitcomp-i0;其中SPratio压得最好,SPspeed跑得最快。
FP64 结果:DPratio 拉开 ratio
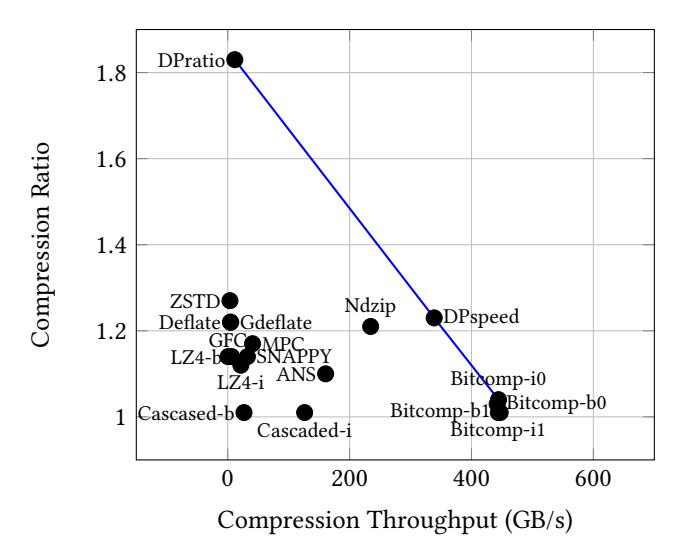
- 这页仍是 ratio vs. throughput,只是对象换成
FP64workload。 DPratio的核心卖点不是速度,而是 明显更高的 GPU 侧压缩率;Bitcomp的 ratio 只有1.04。- 这证明
FCM + adaptive top-bit elimination的确抓住了FP64的结构特征,只是代价是编码更慢。
CPU 结果与兼容性
SPspeed在Ryzen上比FPzip压缩快75x、解压快55x,说明这不是“只会在 GPU 上好看”的方案。DPspeed对比pFPC也约有10x吞吐优势,而且压缩率相近。- 更关键的是:只有本文四个方案和
Ndzip真正提供 CPU/GPU 兼容 bitstream;这在真实 pipeline 中比单次 benchmark 冠军更重要。 - 论文还专门指出,若把
nvCOMP不做 contiguous concatenation 的优势扣掉,本文方案的系统意义会更强。
为什么有些场景更强
SPspeed的 sweet spot 是 需要实时写入 / 高频解压 的场景,因为两级变换足够轻。SPratio更适合 带宽仍紧张但能容忍额外编码开销 的FP32数据归档。DPratio强在FP64压缩率,但它显然不适合最敏感的在线编码延迟路径。- 论文也明确承认:若数据 不平滑、低位高度随机,这些方法不会特别占优。
结论
- 这篇工作给出的不是一个 compressor,而是一套 面向 heterogeneous scientific workflow 的设计空间分解。
- 最重要的技术判断是:先把冗余转成 leading zeros / repeated high bits / short-distance matches,再交给 GPU-friendly primitive 处理。
- 从系统角度看,最有价值的结果不是某个单点冠军,而是 四个方案几乎始终站在 Pareto front 上。
我的评价
- 优点: 问题定义非常准,真正把
ratio + throughput + compatibility当成同等重要目标。 - 最强点:
DPratio没有硬套FP32思路,而是正面承认FP64随机性并重写变换链。 - 局限: 对 smooth data 依赖强,且
DPratio的排序与2x中间表示让工程成本不低。 - 后续: 最自然的下一步是 per-chunk adaptive pipeline selection,按数据特征动态切
speed/ratio路线。