Early Termination for Hyperdimensional Computing Using Inferential Statistics
用推断统计实现 HDC 早停
Pu (Luke) Yi, Yifan Yang, Chae Young Lee, Sara Achour
Stanford University
ASPLOS 2025
Presenter: wzw
Date: 2026-04-27
TL;DR
- 瓶颈: 现有 HDC 早停靠 heuristic threshold,常常停早或停晚。
- 方法: OMEN 用 统计检验 判断当前 winner 是否已足够可靠。
- 结果: 19 个 benchmark 上最高
12.18xspeedup。
为什么 HDC 适合早停
- HDC 的 encoding 与 distance computation 都是 element-wise / streaming 的。
- 只处理前 $n$ 个维度时,系统已经拿到了一个 前缀距离估计。
- 所以难点不是“能否早停”,而是 何时停才不会误判。
现有方法卡在哪里
- 过去方法通常用
distance gap或absolute similarity作为 confidence metric,本质仍是 经验阈值。 - 这些方法没有统计保证:
- easy input 上可能 算太多
- hard input 上可能 停太早
- 对 edge inference 来说,主要成本就在 encoder 与 distance accumulation,这种不稳定直接变成 latency / energy 浪费。
关键观察:距离可以看成采样
- fully distributed 意味着,每个 element distance 都像同一分布中的 sample。
采样视角的核心式子
$$ Z_n(D) = \frac{1}{n}\sum_{i=1}^{n} D[i] $$
- 前缀距离因此是 sample mean estimator,早停问题也就能写成 hypothesis testing。
HDC 分类器长什么样
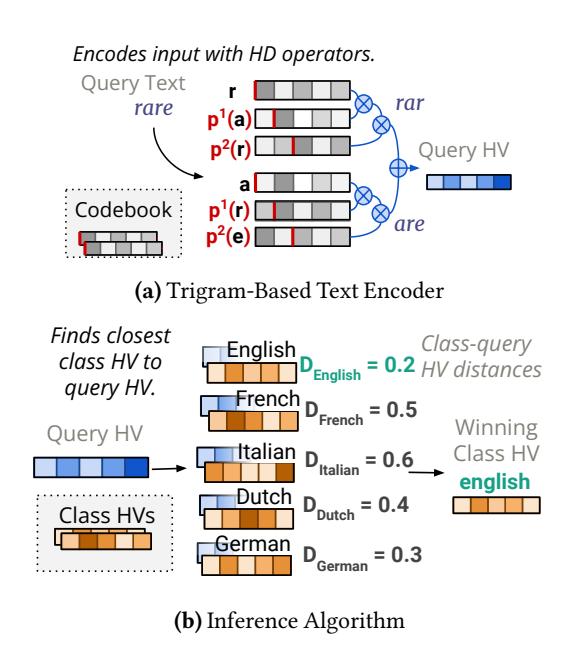
Figure 1给的是 language classifier: input 先被 encoder 映射成 query hypervector,再和多个 class hypervector 比距离。- 论文的切入点并不是改模型结构,而是在 inference loop 外面加一个动态停止控制器。
OMEN 的高层流程
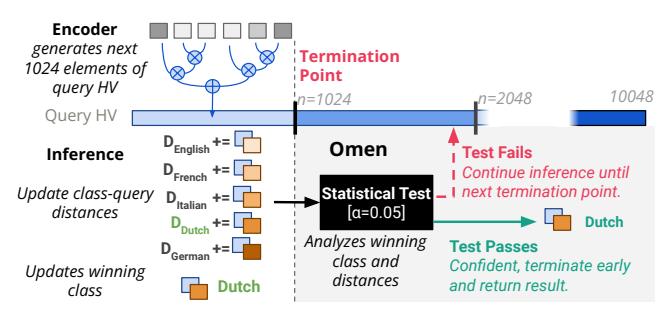
- 在若干 termination points 上,OMEN 检查当前 winner 是否对所有其他类别都已“显著更优”。
- 若检验通过就提前返回;否则继续处理更多维度。Q2 这类 easy input 只需处理 20.4% 维度即可停下。
一个请求如何走完整个机制
- encoder 逐维产生 query hypervector,并持续累计各 class 的 running distance。
- 到达 termination point 后,取
cand = argmin(dist),并与其余类别逐一做显著性检验。 - 只有当所有 null hypotheses 都被拒绝时才提前结束;否则继续处理更多维度。
机制一:Wald test
- 先定义 test statistic:
S_n = sqrt(n) * gap / sqrt(CD_n - gap^2) - 再把它映射成
p-value:W_n = 1 - Phi(S_n)
Wald test 在做什么
- 比较的是两个类别距离的 expected distance,不是简单看当前谁更小。
- $CD_n$ 处理 paired comparison,因为多个类别与同一个 query 比较时并 不独立。
- 对 BSC/Hamming distance,$CD_n$ 可 离线预计算。
机制二:Holm-Bonferroni
$$ p_i < \frac{\alpha}{j} $$
- 它把多个比较的总体误判概率压回 $\alpha$。
为什么这一步很关键
- 没有它,多个 pairwise test 的错误率会累加,confidence 就不再可信。
- 有了它,OMEN 才能说: early exit 引入的额外 estimation error 有显式上界。
理论扩展:从 iid 到 exchangeability
- 对 vanilla HDC,作者可把元素视作
iid;但对OnlineHD / LeHDC / LDC这类 learned hypervector,独立性往往被破坏。 - 论文进一步证明: 这些训练算法虽然不一定保留 iid,但会保留更弱的统计对称性 exchangeability。
- 这一步很关键,因为它把 OMEN 从“只适用于简单 HDC”扩展到 更现实的 learned classifier。
部署代价并不高
| Baseline | Encode | Distance | Stat Tests | Total |
|---|---|---|---|---|
| Unoptimized | 243.40 | 0.10 | - | 243.50 |
| Omen $\alpha=5\%$ | 77.67 | 0.04 | 0.59 | 78.30 |
- 在
OHD-BSC-ucihar上,statistical tests 只占总时延约0.76%。 - 论文不需要改 HDC training pipeline,也 不要求新硬件 block;主要额外代价是少量数值计算与 termination bookkeeping。
- 真正的弱点出现在
LDC-BSC, N=256:维度太短、且统计检验含 floating-point ops,优化空间被明显压缩。
实验方法学
- 任务:
lang / ucihar / isolet / mnist四类 edge-friendly classification。 - 模型:
OnlineHD / LeHDC / LDC,再配合BSC / MAP变体,总计 19 benchmarks。 - HV 大小:
10048 / 5056 / 256;termination 配置分别为512/64、512/64、16/4。 - 平台: 能装下的模型在
STM32U585AI MCU上跑;大 MAP 模型转到桌面i9-13900K单线程执行。 - 对比:
DIFF / ABSOLUTE / MEAN / Smaller Vector,覆盖主流 heuristic family。
主结果:性能提升很扎实
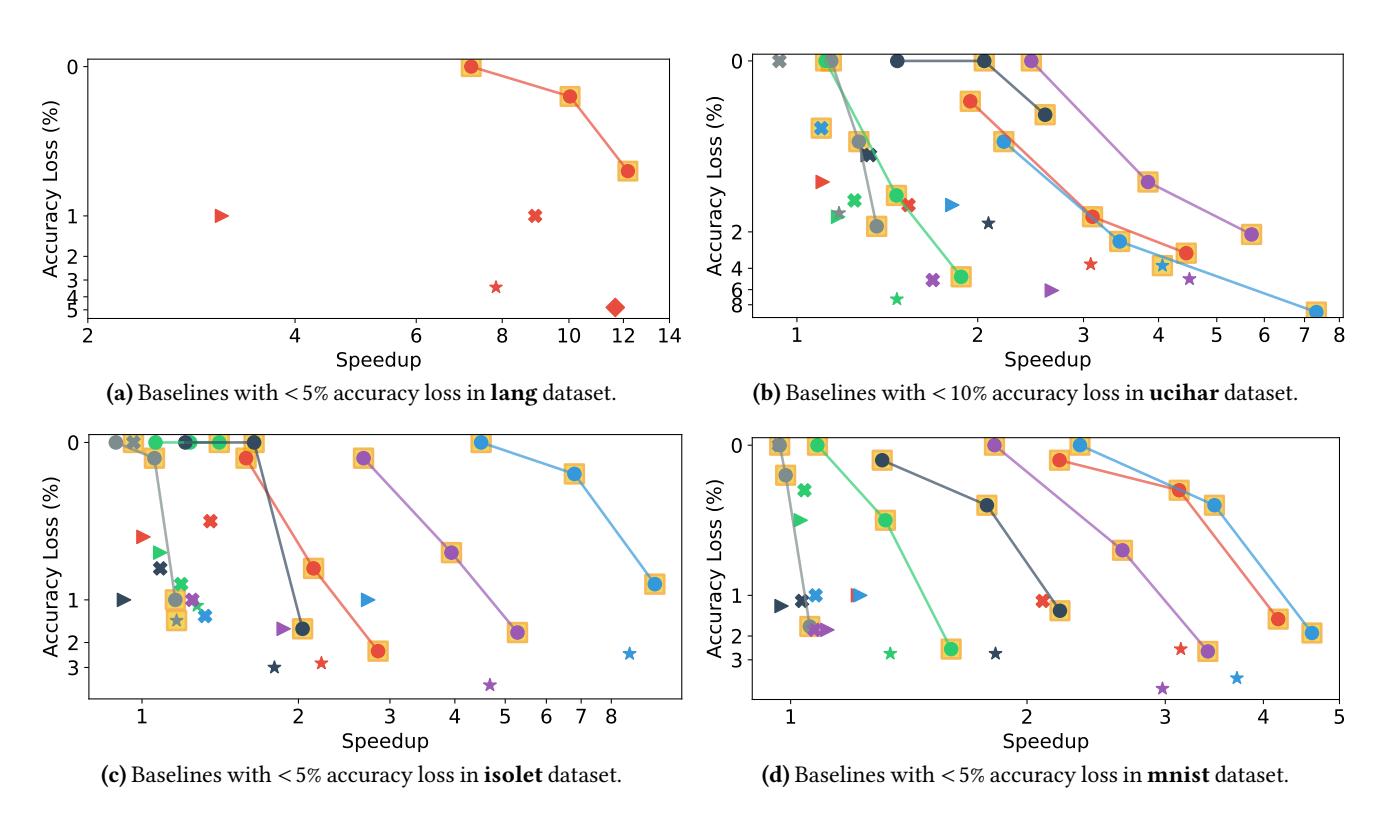
- $\alpha=1\%$:
1.08-7.21x - $\alpha=5\%$:
1.24-10.04x
主结果:更激进时更快
- $\alpha=10\%$:
1.41-12.18x - 大多数 OMEN 点落在 Pareto frontier 上,说明收益不是靠“粗暴牺牲精度”换来的。
- 真正的弱项集中在
LDC-BSC,因为N=256太短,能裁剪的冗余本来就少。
精度也基本守住了
- $\alpha=1\%$ 时,accuracy loss 只有
0.0-0.6%;其中 13 个 benchmark 是0%loss。 - $\alpha=5\%$ 时,accuracy loss 为
0.0-2.4%,且比SV少0.8-7.2%loss。 - 重点是 loss 基本跟着用户设定的 $\alpha$ 走。
为什么 speedup 能跟上 DRR
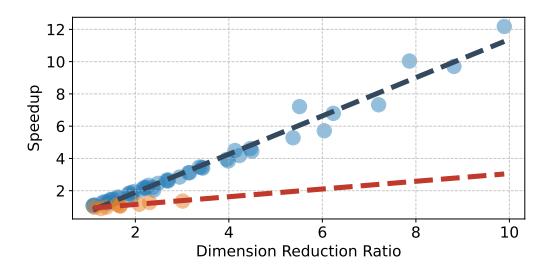
- 对 16 个非 LDC-BSC benchmark,论文拟合出
SUR = 1.187 * DRR - 0.483。 - 这说明 OMEN 的理论优势确实转成了真实 runtime gain,而不是被 control overhead 吃掉。
- LDC-BSC 斜率更差,正好暴露出 短 hypervector + floating-point test 的局限。
噪声硬件下依然成立
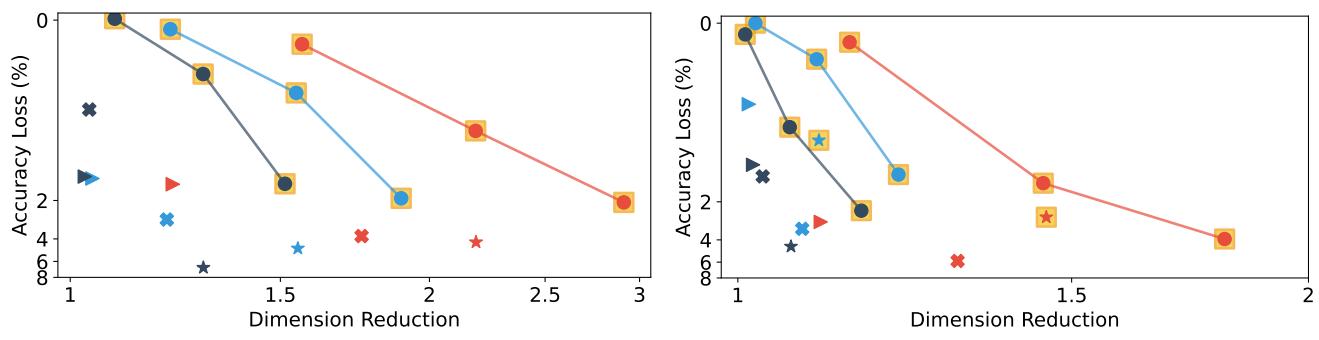
- 在 ReRAM 风格 bit corruption 下,OMEN 仍保持更好的 tradeoff。
LDC-BSC噪声实验里,$\alpha=5\%$ 仍有1.07-2.19xreduction,accuracy drop 仅0.3-1.4%。
这篇论文真正贡献了什么
- 把问题重新定义了: early termination 不再是调 threshold,而是做 sequential statistical decision。
- 把理论和工程接上了:
Wald + Holm-Bonferroni + CD precompute让保证不是停留在纸面上。 - 把适用面扩宽了: 通过 exchangeability,把方法推广到 learned HDC classifier,而不只是 toy iid setting。
我的批评与后续方向
- 最脆弱的点: Wald test 典型依赖 CLT,但对 learned hypervector,论文严格证明的是 exchangeability,不是 iid;理论闭环还不算完全闭合。
- 缺的实验: 动机是 edge efficiency,但主结果更偏 latency;若补上
energy / EDP,说服力会更完整。 - 工程余量: termination points 仍是人工设定的
it/ct,这层 policy 本身还可以继续优化。 - 后续方向: 把 termination schedule 也做成 learned/offline-optimized policy,或者迁移到其他 progressive inference 系统。