DiP Systolic Array
DiP:面向矩阵乘加速的可扩展高能效 Systolic Array
Ahmed J. Abdelmaksoud, Shady Agwa, Themis Prodromakis
The University of Edinburgh
IEEE TCAS-I 2026
Presenter: wzw
Date: 2026-04-28
三句话看懂
- 瓶颈: 传统
weight-stationary (WS)systolic array 为了对齐输入/输出时序,需要额外FIFO,而且PE只能沿对角线逐步激活,TFPU = 2N - 1。 - 方法: DiP 用
diagonal-input + permutated weight重写数据流,在不引入大型adder tree的前提下直接去掉同步FIFO。 - 结果: 在
22nm、64x64阵列下,DiP 相对 WS 达到1.49xthroughput、1.21xlower power、1.93xenergy-efficiency-per-area;在 transformer workloads 上最高1.81xenergy gain。
背景:为什么是 WS
- Transformer 的
MHA/FFN本质上被大规模matrix multiplication主导,商业 AI 芯片普遍采用systolic array。 - 在常见 dataflow 里,作者认为
OS需要更高 memory bandwidth,RS有更多 data replication;因此他们聚焦更常用的WS。 WS的优点是 weight reuse 高、结构规整、易扩展到大阵列,这也是TPU-like设计的主流路线。- 但这篇论文的核心观点是:WS 真正拖后腿的不是 MAC 本身,而是同步与填充开销。
WS 真瓶颈
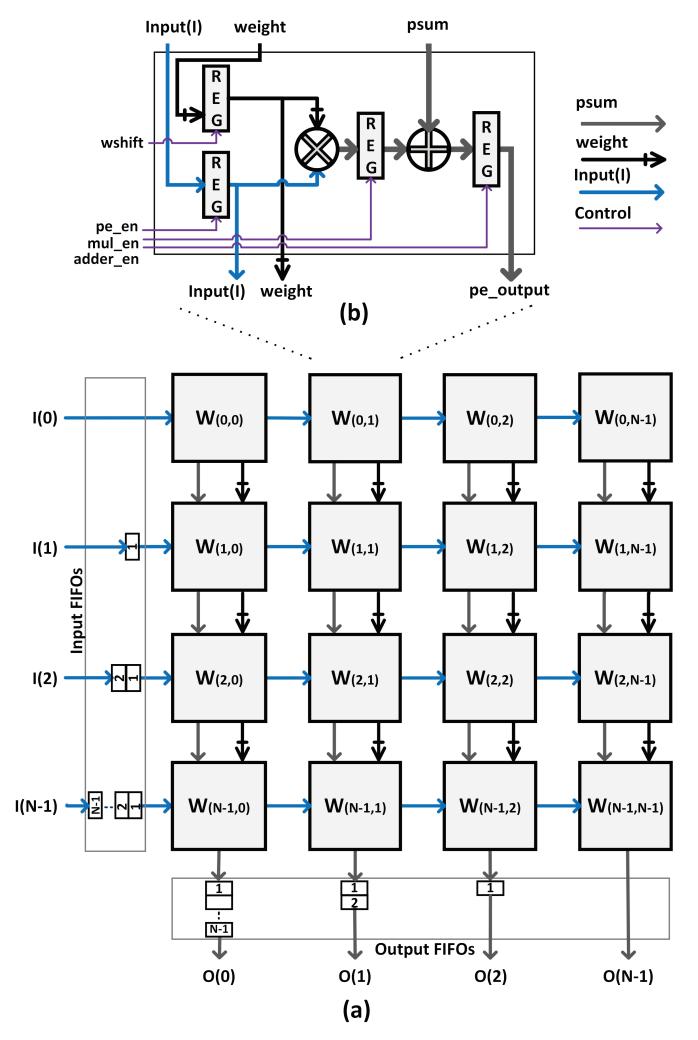
- 左图是标准
WS阵列:边界需要两组input/output FIFO做同步,额外吃掉 area、power、latency。 - 更致命的是计算波前从左上向右下传播,阵列在启动阶段长期 不能满载。
- 论文把这个 startup overhead 明确化成
TFPU,这让后面的 DiP 设计目标非常清楚。
关键观察
- Baseline 需要
TFPU_WS = 2N - 1cycles 才能满载;DiP 只需TFPU_DiP = N。 - 如果输入能按行更快铺满阵列,而不是继续沿 diagonal wave 慢慢扩散,startup waste 就会明显下降。
- 所以作者首先优化的不是 MAC 数量,而是 阵列满载时间。
为什么会更快
- Latency 从
3N + S - 3降到2N + S - 2,主导项直接少了一个N。 - 因此阵列越大,DiP 相对 WS 的 throughput gain 越明显;论文在
64x64时逼近1.49x。
DiP 总体架构
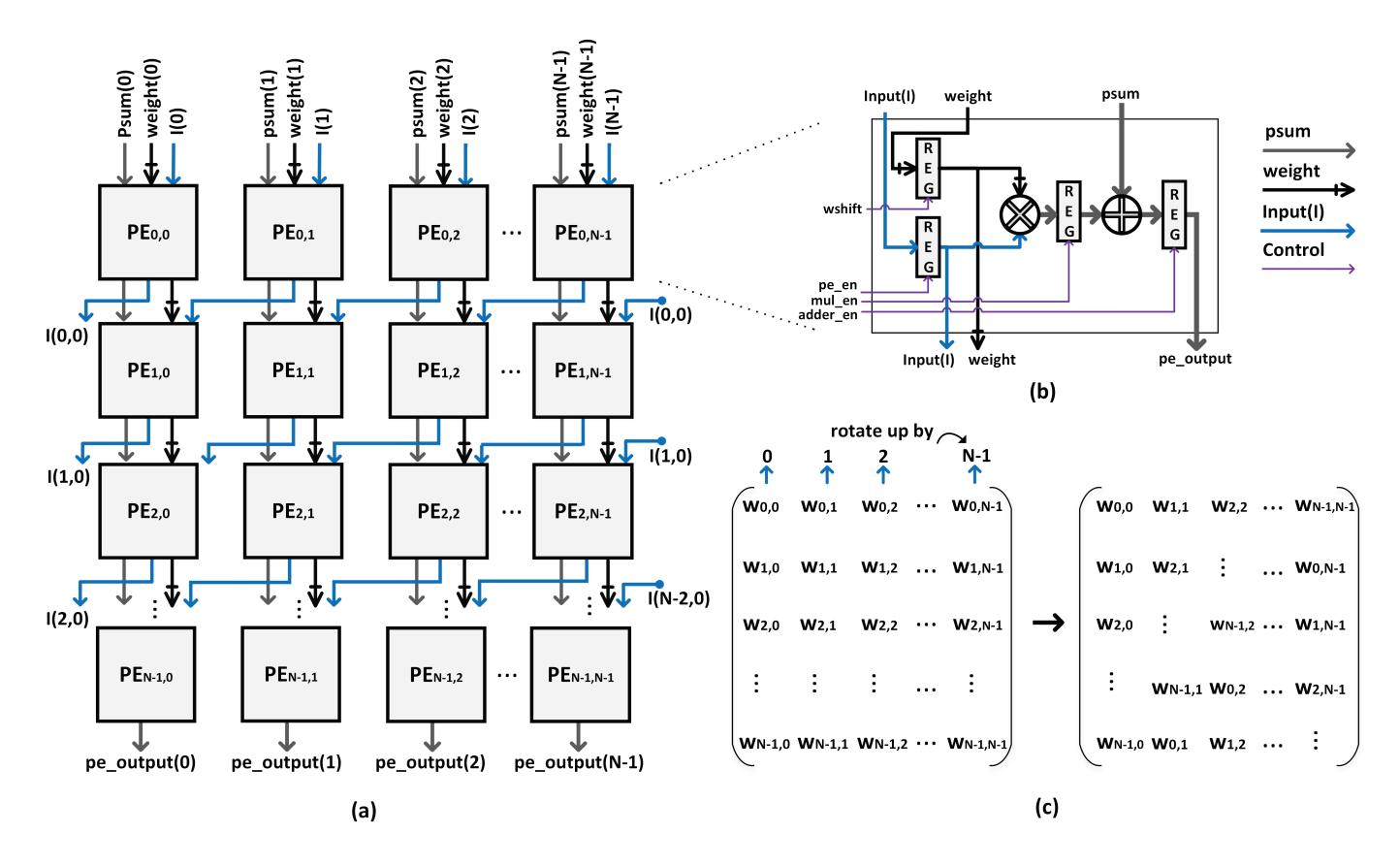
- 阵列本身仍是规则的
N x NPEmesh,单个PE仍然只是2-stage pipelined MAC + 4 registers。 - 变化点只有两个:输入改为 diagonal movement,权重按列索引做 permutation。
- 这是一种很“硬件保守”的改法:尽量不碰 PE 本体,把收益放在数据流重构上。
机制一:Diagonal Input
- 局部问题: baseline WS 的输入只在行内横向传递,导致下方
PE rows必须等待很久才能被喂饱。 - 新结构: DiP 让左边界
PE的寄存输入跨行对角连到下一行最右侧PE,输入会从一行“斜着”流向下一行。 - 直接收益: 阵列按行更快铺满,因此
TFPU从2N - 1降到N,大阵列下启动成本几乎减半。 - 工程判断: 这比引入复杂全局归约树更稳妥,因为连线模式变了,但
PE datapath没变。
机制二:Weight Permutation
- Diagonal input 会打乱原始 weight 到达时序,因此每列都要做循环平移。
- 公式是
W'_{j,i} = W_{(j+i)\bmod N,\,i};结果是PE仍在正确 cycle 看到目标 weight,因此能删掉FIFO。
3x3 生命周期
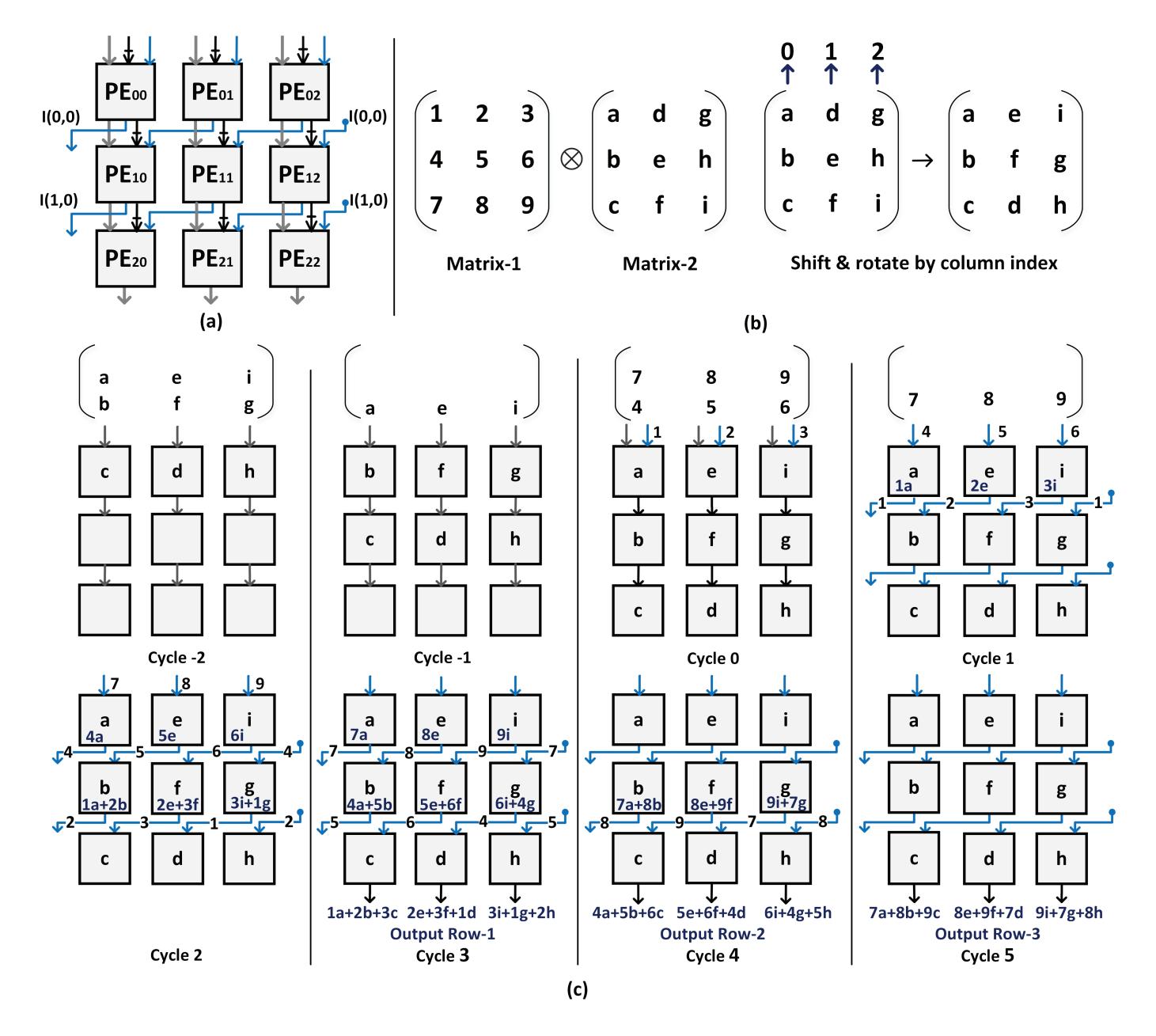
Cycle -2 ~ 0: 先按 permutation 后的顺序装入权重;Cycle 0同时装最后一行权重和第一行输入。Cycle 1 ~ 5: 输入先在Row-0计算,再通过 diagonal connection 变成下一行需要的顺序继续流动。- 这个例子最关键的 takeaway 是:FIFO 原来承担的时序对齐工作,现在被“输入走向 + 权重布局”共同吸收了。
硬件账单
| Size | Tput Gain | Power Gain | Area Gain | Overall Gain |
|---|---|---|---|---|
32x32 |
1.48x |
1.25x lower |
1.09x smaller |
2.02x |
64x64 |
1.49x |
1.21x lower |
1.07x smaller |
1.93x |
- DiP 的优势不是只靠“更快”,而是 throughput 上升 + FIFO 删除 + active-cycle 更集中 共同作用。
64x64时仍能省面积,说明新增的 diagonal wiring 并没有把实现成本重新吃回来。- 论文在结论中还给出峰值点:
4096 PEs、8.192 TOPS、9.548 TOPS/W。
方法学
- 实现方式: 参数化
Verilog,从综合一直做到GDSII,工艺为商用22nm、频率1 GHz。 - 设计空间: 阵列规模从
4x4到64x64;analytical model 则从3x3到64x64比较 WS 与 DiP。 - Workloads:
MHA + FFN,覆盖Vanilla Transformer / T5 / BART / BERT / ALBERT / Transformer-XL / GPT-2 / GPT-3 / LLaMA。 - 对比对象: 一类是同工艺、同风格的
WS/TPU-likebaseline;另一类是跨论文的SOTA accelerators。
解析模型与扩展性
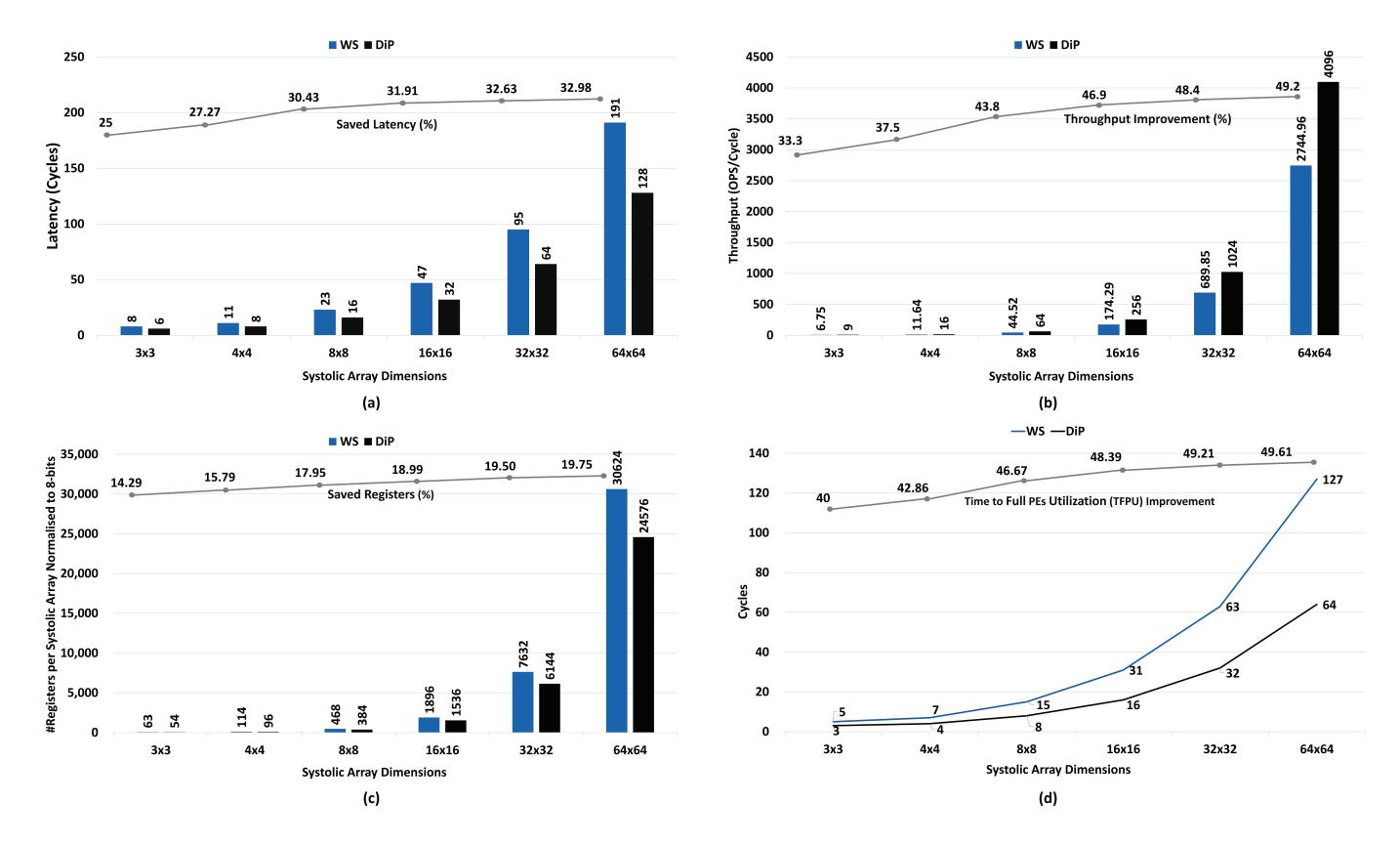
Fig.4(a)(b)表明阵列变大时,DiP 的 latency saving 从约28%走到33%,throughput gain 从33.3%逼近49.2%。Fig.4(c)说明仅靠删除同步FIFO,寄存器开销在64x64就可省到约20%。Fig.4(d)最重要:DiP 用Ncycles 即可满载,而 WS 需要2N-1;这解释了它为什么尤其擅长小到中等 tile。
Transformer 结果
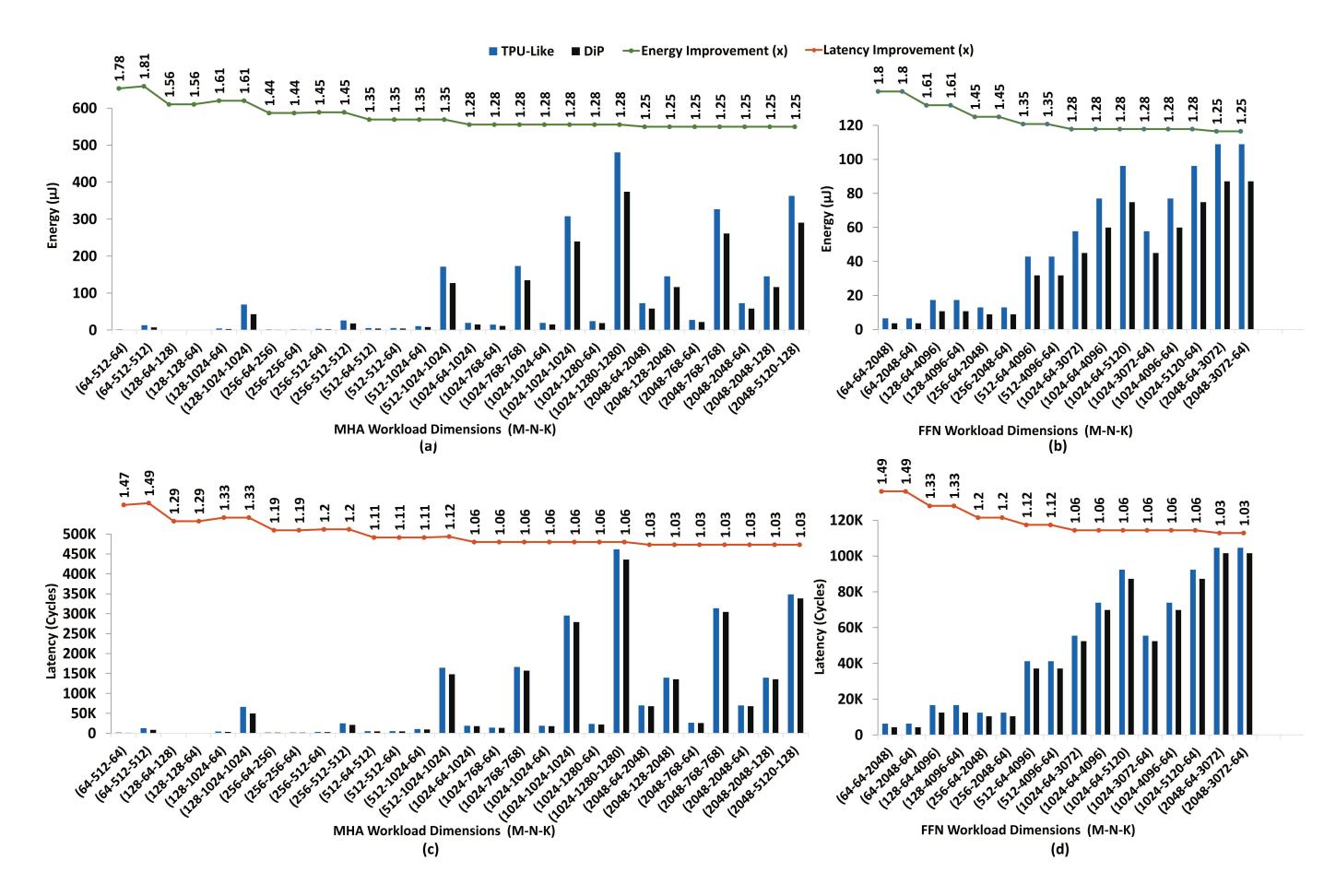
- 在
64x64TPU-like baseline 上,DiP 对MHA/FFNworkload 的 energy gain 为1.25x ~ 1.81x,latency gain 为1.03x ~ 1.49x。 - 最大收益出现在小到中等 workload,因为 baseline WS 每次装新
M2 tile时都要重新支付更高的TFPU。 - 随着 workload 变大,baseline 可以逐渐隐藏 startup cost,所以 latency 优势会回落到接近
1.03x。
与相关工作比较
| Metric | DiP | TPUv4i | Groq TSP | DTATrans |
|---|---|---|---|---|
| Peak Throughput | 8.192 |
138 |
820 |
1.304 |
| Energy Eff. | 9.548 |
0.786 |
2.733 |
1.623 |
| Area Eff. @22nm | 8.192 |
0.017 |
0.412 |
2.984 |
- 按论文的
22nm归一化口径,DiP 的 energy efficiency / area efficiency 很强,尤其优于 system-level 大芯片。 - 但这里要主动提醒听众:这张表混合了
core-level、system-level、post-silicon、post-synthesis和post-layout,只能看趋势,不能当严格公平比较。 - 因此真正最可信的证据,仍然是它和同风格
WS/TPU-likebaseline 的 head-to-head 对比。
总结
- DiP 的真正贡献是把 同步 FIFO 的问题转化为 dataflow 问题,而不是继续堆更重的计算/归约结构。
- 这个设计同时改善了
latency、throughput、area、power,并且解释链路很完整:lower TFPU + no FIFO + better PE utilization。 - 如果只记一句话:DiP 不是更复杂的 systolic array,而是更聪明的 WS systolic array。
我的评价
- 优点: 贡献集中、解析模型清楚、实现路径保守,属于“真能落后端”的 microarchitecture 改进。
- 最漂亮的点:
3x3lifecycle 例子把整个想法讲得很透,说明作者对 dataflow correctness 的把握是到 cycle 级的。 - 主要疑问: 论文把
weight permutation说成几乎零开销,但没有充分量化地址生成、bank conflict 和 memory scheduling 代价。 - 后续方向: 我更想看
multi-core DiP、非整除 tile、以及真实 system memory hierarchy 下它还能保留多少收益。