Concerto
Concerto:面向大规模深度学习的自动通信优化与调度
Shenggan Cheng, Hao Wu, Ziming Liu, Shengjie Lin, Siyu Wang, Xuanlei Zhao, Lansong Diao, Chang Si, Jiangsu Du, Wei Lin, Yang You
NUS, GMU, Georgia Tech, Alibaba Group, Sun Yat-sen University
ASPLOS 2025
Presenter: wzw
Date: 2026-04-28
TL;DR
- 瓶颈: distributed training 里,collective communication 常常裸露在 critical path;现有优化大多绑定某一种 parallelism。
- 方法: Concerto 用 RCPSP/ILP scheduling + auto-decomposition,把 communication optimization 变成 compiler problem。
- 结果: 相比
Megatron-LM / JAX-XLA / DeepSpeed / Alpa,最高达到19.0% / 34% / 42.9% / 22.7%提速。
通信为什么还是慢
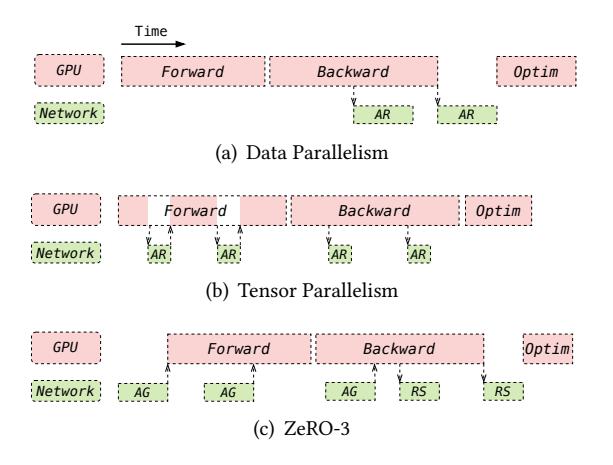
- 不同 parallelism 都会引入 collective communication,只是位置不同:
DP有 gradient sync,TP有 forward/backward all-reduce,ZeRO有 gather/scatter。 - 论文要解决的不是“某一个 all-reduce 太慢”,而是 整个训练图里的 communication 该怎么自动与 computation overlap。
手工 overlap 不够
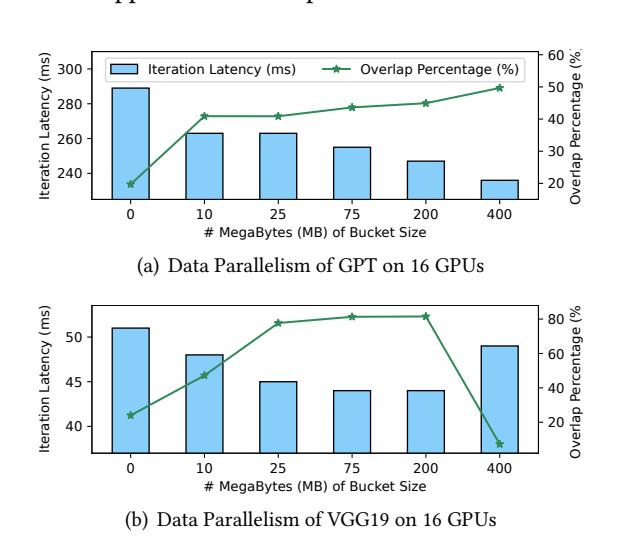
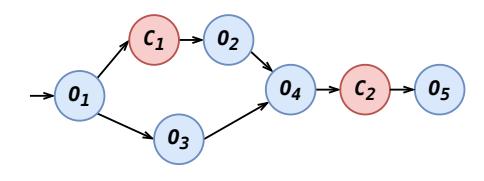
Figure 2说明 bucket size 没有通用最优点,不同模型最优设置差异明显。Figure 3说明只按 program order 发通信会错过 overlap 机会;真正的问题是 operator order + communication granularity 都要调。
关键观察
- Observation 1: 对
asynchronous communication,核心是重排 launch 次序,尽量把 communication 塞进 compute 空隙。 - Observation 2: 对
synchronous communication,仅靠调度不够,必须主动拆分上下文计算,制造新的 overlap 窗口。 - 所以 Concerto 不是只做 scheduler,也不是只做 decomposition,而是把二者放进同一个 compiler pipeline。
系统全景
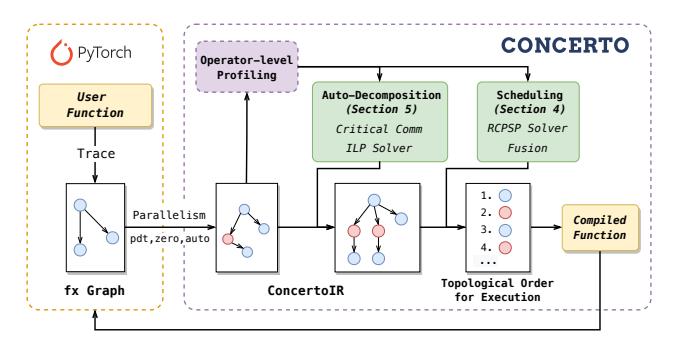
- 输入是
torch.fxgraph,输出是一个被重新排序、必要时被分解过的ConcertoIR。 - 两个核心 pass:
auto-decomposition找并拆critical communication;scheduling负责重排顺序并顺带做 fusion。
调度建模
- 目标可以直接写成:
min makespan,同时满足 dependency 与 resource 约束。 - 每个 operator 是一个 task,资源只分
computation与communication。 - 重点是把 overlap 从 heuristic 变成 solver 可求的 optimization problem。
怎么让 ILP 可解
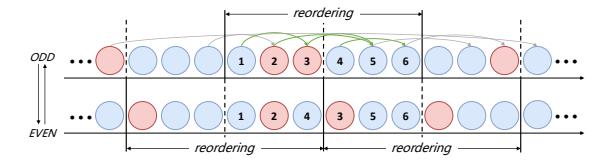
- 全图 RCPSP 是
NP-hard,直接在上万节点图上解 ILP 不现实。 - Concerto 用 odd-even scheduling: 先把当前顺序切成 blocks,局部求优;再整体平移半个 block,继续迭代。
- 这样把一次求解复杂度压到近似
O(k t_b n / b),在“解得动”与“接近最优”之间做工程折中。
机制1:自动拆分
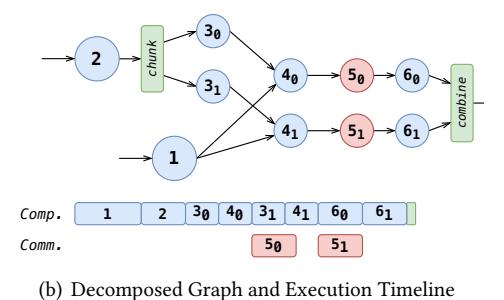
- 如果独立节点可提供的 overlap 时间仍小于某个通信算子的通信时间,它就是
critical communication。 - Concerto 沿张量维度向前/向后搜索 decomposition context,把一个“大而同步”的通信拆成多个能穿插 compute 的小块。
机制2:怎么选拆法
- 选择规则可以概括成:
cost = max(uncovered-comm, split-overhead, 0)。 cost同时衡量 未遮蔽通信 与 拆分开销。- slowdown 系数取
\alpha = 1.2,来自18.2% / 21.9% / 23.8%的实测退化。 - 若 TFLOP/s 掉太多或 HBM traffic 涨太多,solver 会直接选择“不拆”。
一次训练迭代怎么走
train_step -> torch.fx -> ConcertoIR,并插入 parallel method 对应的 communication ops。- profiling 得到各 operator 的
T_i,auto-decomposition 为关键同步通信生成候选策略。 - scheduler 求更优 topological order,并把可交换且同类型的 communication 做 fusion。
- runtime 只做双 stream 执行与依赖收尾:
comp进默认 stream,comm进通信 stream。 - 本质收益是把 写死在框架里的 overlap 变成 编译期自动发现的 overlap。
实验怎么做
- 硬件:
4 nodes / 32x A800-80GB,单节点8 GPU + NVLink 400 GB/s,跨节点带宽800 Gbps。 - 软件:
CUDA 12.0,PyTorch 2.1.2,NCCL 2.18.6。 - 模型:
GPT,ViT,Evoformer,WideResNet。 - 并行方式:
PTD,ZeRO-2/3,DAP,automatic parallelism。 - 基线:
Megatron-LM v3.0,JAX/XLA 0.4.30,DeepSpeed 0.12.4,Alpa 0.2.3。
PTD 与 JAX/XLA

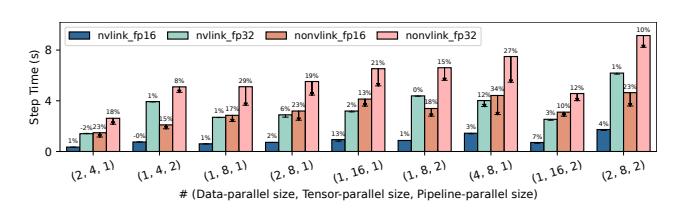
- 对
Megatron-LM,Concerto 在 GPT 上 最高+19.0%,平均+3.5%;在 NVLink 很强时增益变小,因为 baseline 已经高度手工优化。 - 对
JAX/XLA,Concerto 无 NVLink 最高+34%,有 NVLink 最高+13.4%;说明固定 heuristic 与固定 decomposition 对硬件变化不够鲁棒。
ZeRO / DAP / Alpa
| 场景 | Baseline | Concerto 提升 |
|---|---|---|
| ZeRO-2 | DeepSpeed | 最高 42.9%,平均 19.1% |
| ZeRO-3 | DeepSpeed | 最高 33.2%,平均 15.1% |
| DAP | FastFold-style impl | 平均 12.5% / 15.6% |
| Auto-parallel | Alpa | 最高 22.7%,平均 11.1% |
- ZeRO 场景收益最大,因为 compile-time scheduling 和 fusion 能显著减少保守同步。
- DAP 与 auto-parallel 更重要的意义是: Concerto 并不依赖某一个固定 parallelism 语义。
消融说明什么
| Case | Baseline | Concerto(S) | Concerto(S+AD) |
|---|---|---|---|
(1,16,1) NVLink FP16 |
0.974 | 0.860 | 0.817 |
(1,8,2) no-NVLink FP32 |
6.566 | 6.295 | 5.616 |
| GPU 数 | ZeRO-3 FP16 fusion 前 | fusion 后 |
|---|---|---|
| 8 | 0.517 | 0.505 |
| 16 | 0.531 | 0.504 |
| 32 | 0.614 | 0.468 |
Scheduling已经能带来稳定收益,但auto-decomposition在通信更重的场景还能继续放大。- communication fusion 不是配角;32 GPU FP16 里单靠 fusion 就能带来约
23.8%额外改善。
系统代价
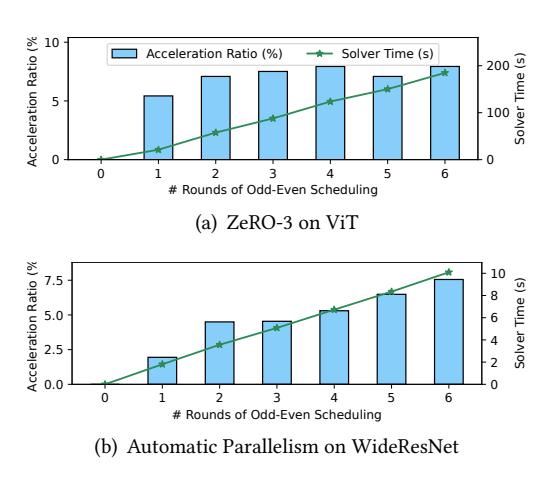
- 编译分三步:
profiling + auto-decomposition + scheduling。 - profiling 典型几十秒,auto-decomposition 通常
< 1s,odd-even scheduling 每轮约2s-30s。 - 它更像 compile-time optimizer;若 workload 或 batch size 高频变化,重新求解成本会开始显著。
我的结论
- 贡献1: 把 communication optimization 从“平行框架里的手工技巧”提升成了 compiler abstraction。
- 贡献2: 用
RCPSP + odd-even scheduling + auto-decomposition扩大了可搜索的 overlap 空间。 - 贡献3: 在
PTD / ZeRO / DAP / auto-parallel上都拿到可观收益,证明设计有跨范式泛化能力。
我的评价
- 最强点: 论文抓住的是“优化空间怎么表示”这个更本质的问题,而不是再发明一个更快 collective primitive。
- 脆弱假设: 两类资源建模过于粗糙,
intra-node与inter-node通信没有被显式区分;作者自己也承认这限制了最优性。 - 缺失实验: 没有覆盖更多真实生产网络扰动、多 batch size 动态变化、以及 cost estimation error 对求解结果的敏感性。
- 后续方向: 应把 scheduling 与 decomposition 做联合优化,再逐步引入 performance model,减少逐策略 profiling 的编译成本。