Scratchpad Memory
Definition From Wikipedia
Scratchpad memory (SPM), also known as scratchpad, scratchpad RAM or local store in computer terminology, is a high-speed internal memory used for temporary storage of calculations, data, and other work in progress. In reference to a microprocessor (“CPU”), scratchpad refers to a special high-speed memory circuit used to hold small items of data for rapid retrieval. It is similar to the usage and size of a scratchpad in life: a pad of paper for preliminary notes or sketches or writings, etc.
In some systems it can be considered similar to the L1 cache in that it is the next closest memory to the ALU after the processor registers, with explicit instructions to move data to and from main memory, often using DMA-based data transfer. In contrast to a system that uses caches, a system with scratchpads is a system with non-uniform memory access latencies, because the memory access latencies to the different scratchpads and the main memory vary. Another difference from a system that employs caches is that a scratchpad commonly does not contain a copy of data that is also stored in the main memory.
Scratchpads are employed for simplification of caching logic, and to guarantee a unit can work without main memory contention in a system employing multiple processors, especially in multiprocessor system-on-chip for embedded systems. They are mostly suited for storing temporary results (as it would be found in the CPU stack) that typically wouldn’t need to always be committing to the main memory; however when fed by DMA, they can also be used in place of a cache for mirroring the state of slower main memory. The same issues of locality of reference apply in relation to efficiency of use; although some systems allow strided DMA to access rectangular data sets. Another difference is that scratchpads are explicitly manipulated by applications. They may be useful for realtime applications, where predictable timing is hindered by cache behaviour.
Scratchpads are not used in mainstream desktop processors where generality is required for legacy software to run from generation to generation, in which the available on-chip memory size may change. They are better implemented in embedded systems, special-purpose processors and game consoles, where chips are often manufactured as MPSoC, and where software is often tuned to one hardware configuration.
Definition From Computational Frameworks 3.3.2
Scratchpad memory (SPRAM) is a high-speed internal memory directly connected to the CPU core and used for temporary storage to hold very small items of data for rapid retrieval. Scratchpads are employed for simplification of caching logic and to guarantee a unit can work without main memory contention in a system employing multiple cores, especially in embedded MCSoC systems. They are suited to storing temporary results.
While a cache memory uses a complex hardware controller to decide which data to keep in cache memories (L1 or L2) and which data to prefetch, the SPRAM approach does not require any hardware support in addition to the memory itself, but requires software to take control of all data transfers to and from Scratchpad memories. It is therefore the responsibility of the programmer to identify data sections that should be placed in SPRAM or place code in the program to appropriately move data from on-chip memory to SPRAM. For this reason, SPRAMs are sometimes called “software controlled caches”. Figure 3.20 illustrates the memory subsystem architecture with two SPRAMs (levels 1 and 2).

Figure 3.20这张图L1/L2 SPRAM为什么会连接到Main memory? 这跟上文中提到的scratchpad memory和cache的区别不符合,反而更像是cache,下面这两张图是从google图片,更能够说明其定义。


Computer_Architecture_Learning_Notes
术语解释

In computing, interleaved memory is a design which compensates for the relatively slow speed of DRAM or core memory, by spreading memory addresses evenly across memory banks. That way, contiguous memory reads and writes use each memory bank in turn, resulting in higher memory throughout due to reduced waiting for memory banks to become ready for the operations.
It is different from multi-channel memory architectures, primarily as interleaved memory does not add more channels between the main memory and the memory controller. However, channel interleaving is also possible, for example in freescale i.MX6 processors, which allow interleaving to be done between two channels.
Intel Pin Tool Use Note
- Overview
- User’s Manual
- Tutorials
- Related Content
- Pin 3.18 User Guide
- How to Instrument with Pin
- Examples
- Building the Example Tools
- Simple Instruction Count (Instruction Instrumentation)
- Instruction Address Trace (Instruction Instrumentation)
- Memory Reference Trace (Instruction Instrumentation)
- Detecting the Loading and Unloading of Images (Image Instrumentation)
- More Efficient Instruction Counting (Trace Instrumentation)
- Procedure Instruction Count (Routine Instrumentation)
- Using PIN_SafeCopy()
- Order of Instrumentation
- Finding the Value of Function Arguments
- Finding Functions By Name on Windows
- Instrumenting Threaded Applications
- Using TLS
- Using the Fast Buffering APIs
- Finding the Static Properties of an Image
- Detaching Pin from the Application
- Replacing a Routine in Probe Mode
- Instrumenting Child Processes
- Instrumenting Before and After Forks
- Managed platforms support
- Callbacks
- Modifying Application Instructions
- The Pin Advanced Debugging Extensions
- Applying a Pintool to an Application
- Tips for Debugging a Pintool
- Logging Messages from a Pintool
- Performance Considerations
- Memory management
- PinTools Information and Restrictions
- Building Tools on windows
- Libraries for Windows
- Libraries for Linux
- Installation
- Building Your Own Tool
- Pin’s makefile Infrastructure
- Feedback
- Disclaimer and Legal Information
- Pin API reference
- Pin Command Line Switches
- Instrumentation Library
Overview
Pin是用于IA-32,x86-64和MIC指令集体系结构的动态二进制工具框架,可用于创建动态程序分析工具。Intel®VTune™ Amplifier,Intel®Inspector,Intel®Advisor和Intel®软件开发仿真器(Intel®SDE)都使用Pin进行构建。使用Pin创建的称为Pintools的工具可用于在Linux *,Windows *和macOS *上的用户空间应用程序上执行程序分析。作为动态二进制检测工具,检测在运行时对已编译的二进制文件进行。因此,它不需要重新编译源代码,并且可以支持动态生成代码的检测程序。
Pin提供了丰富的API,该API提取了底层的指令集特性,并允许将诸如寄存器内容之类的上下文信息作为参数传递给注入的代码。 Pin会自动保存和恢复被注入的代码覆盖的寄存器,因此应用程序可以继续工作。 也可以访问符号和调试信息。
Pin最初是作为用于计算机体系结构分析的工具而创建的,但是其灵活的API和活跃的社区(称为“ Pinheads”)为安全性,仿真和并行程序分析创建了各种各样的工具。
User’s Manual
Tutorials
- CGO 2013 [PDF 3.464MB] (February 2013, Shenzhen, China)
- CGO 2012/ISPASS 2012 [PPT 6.7MB] (April 2012 - San Jose, CA and New Brunswick, NJ)
- CGO 2011 [PPT 10.5MB] (April 2011, Chamonix, France)
- CGO 2010 [PPT 7MB] (April 2010, Toronto, Canada)
- Academia Sinica 2009 (May 2009 - Taipei, Taiwan) - Part 1 [PPT 469KB] and Part 2 [PPT 299KB]
- ISCA 2008 (June 2008 - Beijing, China) - Part 1 [PPT 469KB] and Part 2 [PPT 220KB]
- ASPLOS 2008 (March 2008 - Seattle, WA) - Slides [PPT 409KB] and Hands On [PDF 365KB] materials
- PLDI 2007 (June 2007 - San Diego, CA) - Slides [PDF 5.601MB]
Related Content
- GTPin - A Dynamic Binary Instrumentation Framework
- [Intel® Software Development Emulator]https://software.intel.com/content/www/cn/zh/develop/articles/intel-software-development-emulator.html)
- Pin - A Binary Instrumentation Tool - Downloads下载链接
- Pin - A Binary Instrumentation Tool - FAQ
- pinheads@groups.io - Newsgroup
- Pin - A Binary Instrumentation Tool - Papers
- Intel® X86 Encoder Decoder Software Library
- Pin - A Binary Instrumentation Tool - PinPoints
- Program Record/Replay Toolkit
- DrDebug: Deterministic Replay based Debugging with Pi
Pin 3.18 User Guide
Pin是用于程序检测的工具。它支持IA-32,Intel(R)64和Intel(R)Many Integrated Core体系结构的Linux *,macOS *和Windows *操作系统以及可执行文件。
Pin允许工具在可执行文件中的任意位置插入任意代码(用C或C ++编写)。该代码在可执行文件运行时动态添加。 这也使得可以将Pin附加到已经运行的进程。
Pin提供了一个丰富的API,可以抽象出底层的指令集特性,并允许将诸如寄存器内容之类的上下文信息作为参数传递给注入的代码。 Pin会自动保存和恢复被注入的代码覆盖的寄存器,因此应用程序可以继续工作。 也可以访问符号和调试信息。
Pin包含大量示例检测工具的源代码,例如基本块分析器,高速缓存模拟器,指令跟踪生成器等。使用这些示例作为模板很容易派生新工具。
How to Instrument with Pin
Pin
对Pin的最好的理解是一个“及时”(JIT)编译器。但是,此编译器的输入不是字节码,而是常规可执行文件。 Pin截取可执行文件的第一条指令的执行,并从该指令开始为直线代码序列生成(“编译”)新代码。然后将控制转移到生成的序列。生成的代码序列几乎与原始代码序列相同,但是Pin确保在分支退出序列时重新获得控制。重新获得控制权后,Pin为分支目标生成更多代码并继续执行。Pin通过将所有生成的代码保存在内存中来提高效率,以便可以重用并直接从一个序列分支到另一个序列。
在JIT模式下,曾经执行过的唯一代码是生成的代码。原始代码仅供参考。生成代码时,Pin使用户有机会注入自己的代码(Instrumentation)。
PIN会记录所有实际执行的指令。它们驻留在哪个部分中都没有关系。尽管条件分支有一些例外情况,但通常来说,如果从不执行一条指令,则不会对其进行检测。
Pintools
从概念上讲,代码注入包含两个组件:
- 一种决定在何处插入什么代码的机制
- 在插入点执行的代码
这两个组件是检测代码和分析代码。 这两个组件都位于一个可执行文件Pintool中。 Pintools可以看作是可以修改Pin内部代码生成过程的插件。
Pintool会在需要生成新代码的情况下在Pin中注册检测回调例程,该检测回调例程表示检测组件。 它检查要生成的代码,调查其静态属性,并确定是否以及在何处注入对分析函数的调用。
分析功能收集有关应用程序的数据。 PIN确保整数和浮点寄存器的状态在必要时得以保存和恢复,并允许将参数传递给函数。
Pintool还可以为诸如线程创建或派生之类的事件注册通知回调例程。 这些回调通常用于收集数据或工具初始化或清理。
Observations
由于Pintool像插件一样工作,因此它必须在与Pin和要检测的可执行文件相同的地址空间中运行。 因此,Pintool可以访问所有可执行文件的数据。 它还与可执行文件共享文件描述符和其他进程信息。
Pin和Pintool从第一条指令开始控制程序。 对于使用共享库编译的可执行文件,这意味着动态加载程序和所有共享库的执行对于Pintool都是可见的。
在编写工具时,调整分析代码比检测代码更重要。 这是因为检测仅执行一次,但是分析代码却被多次调用。
Instrumentation Granularity
如上所述,Pin的检测是“及时”(JIT)。在第一次执行代码序列之前立即进行检测。我们将这种操作称为跟踪检测模式。
跟踪检测使Pintool一次可以检查和检测一个可执行文件的跟踪。跟踪通常从采用分支的目标开始,以无条件分支结束,包括调用和返回。 Pin保证仅在顶部输入跟踪,但是它可以包含多个出口。如果分支连接到跟踪的中间,则Pin会构建一个以分支目标开头的新跟踪。Pin将迹线分为基本块BBL。BBL是单入口单出口指令序列。bbl中间的分支开始新的跟踪,并因此开始新的BBL。通常可以为BBL插入一个分析调用,而不是为每个指令插入一个分析调用。减少分析调用的数量可以提高检测效率。 跟踪检测利用TRACE_AddInstrumentFunction API调用。
但是请注意,由于Pin在执行程序时会动态发现程序的控制流,因此Pin的BBL可能不同于在编译器教科书中可以找到的BBL的经典定义。 例如,考虑为switch语句的主体生成的代码,如下所示:
1 | switch(i) |
它将生成类似这样的指令(对于IA-32架构):
1 | .L7: |
就经典基本块而言,每个addl指令都在单个指令基本块中。但是,由于执行了不同的switch情况,Pin会生成BBL,当输入.L7情况时,这些BBL包含所有四个指令,当输入.L6情况时,这些BBL包含三个指令,依此类推。这意味着,如果您认为Pin BBL与课本中的基本块相同,那么对引脚BBL进行计数就不太可能得到您期望的计数。例如,在这里,如果代码分支到.L7,则将计为一个Pin BBL,但是执行了四个经典基本块。
Pin还会破坏其他某些可能无法预料的指令上的BBL,例如cpuid,popf和REP前缀的指令会终止所有迹线,因此也会破坏BBL。由于REP前缀指令被视为隐式循环,因此,如果REP前缀指令多次迭代,则在第一个指令之后的迭代将导致生成单个指令BBL,因此在这种情况下,您将看到比预期更多的基本块执行。
为了方便Pintool编写者,Pin还提供了一种指令检测模式,该模式可使工具一次检查和检测可执行文件中的一条指令。这基本上与跟踪工具相同,在该工具中,Pintool编写器已摆脱了对跟踪内部的指令进行迭代的责任。如在跟踪检测中所述,某些BBL及其内部的指令可能会多次生成。指令检测利用INS_AddInstrumentFunction API调用。
但是,有时候,查看与跟踪不同的粒度可能会很有用。为此,Pin提供了两种附加模式:镜像和常规检测。这些模式是通过“缓存”检测请求来实现的,因此会产生空间开销,这些模式也被称为提前检测。
镜像检测使Pintool可以在首次加载时检查并检测整个IMG。Pintool可以遍历映像的部分SEC,部分的例程RTN和例程的指令INS。可以插入工具,以便在执行例程之前或之后或在执行指令之前或之后执行它。镜像检测利用IMG_AddInstrumentFunction API调用。镜像检测取决于符号信息来确定例程边界,因此必须在PIN_Init之前调用PIN_InitSymbols。
例程检测使Pintool在第一次加载包含其映像的图像时检查并检测整个例程。 Pintool可以执行例程的指令。没有足够的信息可用于将指令分解为BBL。可以插入工具,以便在执行例程之前或之后或在执行指令之前或之后执行它。如上一段所述,提供了例行检测程序,以方便Pintool编写者,也可以代替在Image检测程序中遍历映像的各节和例程。
常规检测利用RTN_AddInstrumentFunction API调用。在存在尾部调用或无法可靠地检测到返回指令的情况下,常规出口的检测不能可靠地工作。
请注意,在Image和Routine工具中,不可能知道例程是否会实际执行(因为这些工具是在图像加载时完成的)。通过标识作为例程开始的指令,可以仅遍历在Trace或Instruction工具例程中执行的例程的指令。请参阅工具Tests/parse_executed_rtns.cpp。
Managed platforms support
Symbols
Floating Point Support in Analysis Routines
Instrumenting Multi-threaded Applications
Avoiding Deadlocks in Multi-threaded Applications
Examples
Building the Example Tools
构建文件夹中所有例子(ia32架构)
1
2cd source/tools/ManualExamples
make all TARGET=Intel64构建文件夹中所有例子(Intel64架构)
1
2$ cd source/tools/ManualExamples
$ make all TARGET=intel64构建并运行某一例子
1
2$ cd source/tools/ManualExamples
$ make inscount0.test TARGET=intel64构建但不运行某一例子
1
2$ cd source/tools/ManualExamples
$ make obj-intel64/inscount0.test TARGET=intel64
Simple Instruction Count (Instruction Instrumentation)
下面的示例对一个程序进行计数,以计算所执行指令的总数。它在每条指令之前插入一个对docount的调用。 程序退出时,它将计数保存在文件inscount.out中。
1 | $ ../../../pin -t obj-intel64/inscount0.so -- /bin/ls |
如果需要指定输出文件,使用”-o
1 | $ ../../../pin -t obj-intel64/inscount0.so -o inscount0.log -- /bin/ls |
该示例可以在source/tools/ManualExamples/inscount0.cpp中找到:
1 |
|
Instruction Address Trace (Instruction Instrumentation)
在前面的示例中,我们没有将任何参数传递给分析过程docount。 在这个例子中,我们展示了如何传递参数。 调用分析过程时,Pin允许您传递指令指针,寄存器的当前值,存储器操作的有效地址,常量等。有关完整列表,请参见IARG_TYPE。
稍作更改,我们就可以将指令计数示例转换为Pintool,该Pintool将打印每条执行的指令的地址。该工具对于了解用于调试的程序的控制流或在模拟指令高速缓存时的处理器设计中很有用。
我们更改INS_InsertCall的参数,传递将要执行的指令的地址。我们用printip代替docount,它会打印指令地址。它将其输出写入文件itrace.out。
1 | $ ../../../pin -t obj-intel64/itrace.so -- /bin/ls |
该示例可以在source/tools/ManualExamples/itrace.cpp中找到:
1 |
|
Memory Reference Trace (Instruction Instrumentation)
前面的示例将检测所有指令。有时工具可能只想检测一类指令,例如内存操作或分支指令。工具可以通过使用Pin API来做到这一点,Pin API包括对指令进行分类和检查的功能。基本API对所有指令集都是通用的,在此进行描述。此外,还有针对IA-32 ISA的指令集特定的API。
在这个例子中,我们展示了如何通过检查指令来做更多的选择性检测。该工具生成程序引用的所有内存地址的跟踪。这对于调试和模拟处理器中的数据缓存也很有用。
我们仅检测读或写内存的指令。我们还使用INS_InsertPredicatedCall而不是INS_InsertCall来避免在断言为false时生成对断言指令的引用。在IA-32和Intel®64体系结构上,将CMOVcc,FCMOVcc和REP前缀字符串操作视为断言。对于CMOVcc和FCMOVcc,该预测是“cc”所隐含的条件测试,对于REP带有前缀的字符串ops,则是计数寄存器为非零。
由于每次执行一条指令时仅调用一次检测功能,而调用一次分析功能,因此与仅对内存操作进行检测相比,仅对内存操作进行检测要快得多。
这是运行它的方法和示例输出:
1 | $ ../../../pin -t obj-intel64/pinatrace.so -- /bin/ls |
该示例可以在source/tools/ManualExamples/pinatrace.cpp中找到
1 | /* |
Detecting the Loading and Unloading of Images (Image Instrumentation)
More Efficient Instruction Counting (Trace Instrumentation)
Procedure Instruction Count (Routine Instrumentation)
Using PIN_SafeCopy()
Order of Instrumentation
Finding the Value of Function Arguments
Finding Functions By Name on Windows
Instrumenting Threaded Applications
Using TLS
Using the Fast Buffering APIs
Finding the Static Properties of an Image
Detaching Pin from the Application
Replacing a Routine in Probe Mode
Instrumenting Child Processes
Instrumenting Before and After Forks
Managed platforms support
Callbacks
Modifying Application Instructions
The Pin Advanced Debugging Extensions
Applying a Pintool to an Application
Tips for Debugging a Pintool
Logging Messages from a Pintool
Performance Considerations
Memory management
PinTools Information and Restrictions
Building Tools on windows
Libraries for Windows
Libraries for Linux
Installation
Building Your Own Tool
Pin’s makefile Infrastructure
Feedback
Disclaimer and Legal Information
Pin API reference
Pin Command Line Switches
Instrumentation Library
Learning Gem5中文翻译
简介
这是本教程的简介,它说了很多有趣的事情。
本文档的目的是向读者提供有关如何使用gem5和gem5代码库的全面介绍。本文档的目的不是提供gem5中每个功能的详细描述。阅读完本文档后,您应该在教室和计算机体系结构研究中使用gem5感到很自在。另外,您应该能够修改和扩展gem5,然后将其改进贡献到主要的gem5存储库中。
这份文件的背景是我在威斯康星大学麦迪逊分校(University of Wisconsin-Madison)读研究生时在过去六年中对gem5的亲身经历。所提供的示例只是做到这一点的一种方法。 与Python不同,Python的口头禅是“应该有一种-最好只有一种-明显的方式来做到这一点。” (来自Python的Zen。请参见import this),在gem5中,有多种不同的方法可以完成同一件事。因此,本书提供的许多示例都是我认为最好的处理方式的观点。
我学到的重要一课(困难的方法)是,在使用诸如gem5之类的复杂工具时,在使用它之前实际了解其工作原理非常重要。
1 | Todo |
1 | Todo |
您可以在github上找到这本书的源代码: https://github.com/powerjg/learning_gem5
第一部分:gem5入门
构建gem5
本章详细介绍如何设置gem5开发环境和构建gem5。
1 | Todo |
gem5的环境要求
有关更多详细信息,请参见gem5要求。
在Ubuntu上,您可以使用以下命令安装所有必需的依赖项。 要求详细说明如下。
1 | sudo apt install build-essential git m4 scons zlib1g zlib1g-dev libprotobuf-dev protobuf-compiler libprotoc-dev libgoogle-perftools-dev python-dev python |
- git(Git)
gem5项目使用Git进行版本控制。 Git是一个分布式版本控制系统。 通过链接可以找到有关Git的更多信息。 默认情况下,应在大多数平台上安装Git。 但是,要在Ubuntu中安装Git,请使用:1
sudo apt-get install git
- gcc 4.8+
您可能需要使用环境变量来指向gcc的非默认版本。
在Ubuntu上,您可以使用以下命令安装开发环境:1
sudo apt-get install build-essential
- SCons
gem5使用SCons作为其构建环境。SCons就像在快速建筑上制造一样,并且在构建过程的所有方面都使用Python脚本,这是一个非常灵活(但很慢)的构建系统。
要在Ubuntu上使用SCons:1
sudo apt-get install scons
- Python 2.7+
gem5依赖于Python开发库。 要在Ubuntu上安装它们,请使用:1
sudo apt-get install python-dev
- protobuf 2.1+
“protocol buffers是一种与语言无关,与平台无关的可扩展机制,用于序列化结构化数据。” 在gem5中,protobuf库用于跟踪生成和回放。 protobuf不是必需的软件包,除非您计划将其用于跟踪生成和回放。1
sudo apt-get install libprotobuf-dev python-protobuf protobuf-compiler libgoogle-perftools-dev
获取代码
将目录更改为要下载gem5源的位置。 然后,要克隆存储库,请使用git clone命令。
1 | git clone https://gem5.googlesource.com/public/gem5 |
现在,您可以将目录更改为包含所有gem5代码的gem5。
你的第一次构建gem5
让我们开始构建一个基本的x86系统。当前,您必须为要模拟的每个ISA分别编译gem5。此外,如果使用Ruby简介,则每个缓存一致性协议都必须具有单独的编译。
要构建gem5,我们将使用SCons。SCons使用SConstruct文件(gem5/SConstruct)设置许多变量,然后在每个子目录中使用SConscript文件查找和编译所有gem5源。
第一次执行时,SCons会自动创建gem5/build目录。在此目录中,您会找到由SCons,编译器等生成的文件。用于编译gem5的每组选项(ISA和缓存一致性协议)将有一个单独的目录。
build_opts目录中有许多默认编译选项。这些文件指定最初构建gem5时传递给SCons的参数。我们将使用X86默认值,并指定我们要编译所有CPU模型。您可以查看文件build_opts/X86来查看Scons选项的默认值。您也可以在命令行上指定这些选项以覆盖任何默认值。
1 | scons build/X86/gem5.opt -j9 |
传递给SCons的主要参数是您要构建的内容 —— build/X86/gem5.opt。在这种情况下,我们将构建gem5.opt(带有调试符号的优化二进制文件)。 我们要在目录build/X86中构建gem5。由于该目录当前不存在,SCons将在build_opts中查找X86的默认参数。(注意:我在这里使用-j9在我的计算机上的8个内核中的9个内核上执行构建。您应该为计算机选择一个合适的编号,通常为cores + 1。)
输出应如下所示:
1 | Checking for C header file Python.h... yes |
编译完成后,您应该在build/X86/gem5.opt中有一个可运行的gem5可执行文件。编译可能会花费很长的时间,通常是15分钟或更长时间,尤其是在使用AFS或NFS之类的远程文件系统进行编译时。
gem5二进制类型
gem5中的SCons脚本当前具有5种可以为gem5构建的二进制文件:debug,opt,fast,prof和perf。 这些名称大多是不言自明的,但在下面进行了详细说明。
- debug
无需优化和调试符号即可构建。如果使用gem5的opt版本优化了要查看的变量,则使用调试器进行调试时,此二进制文件很有用。 与其他二进制文件相比,使用debug进行运行速度较慢。 - opt
该二进制文件是使用(例如-O3)的大多数优化构建的,但其中包含调试符号。该二进制文件比debug速度快得多,但是仍然包含足够的调试信息以能够调试大多数问题。 - fast
内置所有优化(包括受支持平台上的链接时优化),并且没有调试符号。 此外,所有断言都被删除,但仍然包括恐慌和致命事件。fast是性能最高的二进制文件,比opt小得多。但是,只有在您认为代码不太可能出现重大错误时,才需要使用fast。 - prof和perf
这两个二进制文件是为分析gem5而构建的。prof包含有关GNU Profiler(gprof)的分析信息,而perf包含有关Google性能工具(gperftools)的分析信息。
常见错误
略!!!
创建一个简单的配置脚本
本教程的这一章将引导您逐步了解如何为gem5设置简单的仿真脚本以及如何首次运行gem5。 假设您已完成本教程的第一章,并且已成功使用可执行文件build/X86/gem5.opt构建了gem5。
我们的配置脚本将为一个非常简单的系统建模。我们只有一个简单的CPU内核。 该CPU内核将连接到系统范围的内存总线。而且,我们将有一个DDR3内存通道,该通道也已连接到内存总线。
gem5配置脚本
gem5二进制文件以设置和执行模拟的python脚本作为参数。在此脚本中,您将创建一个系统来模拟,创建系统的所有组件并指定系统组件的所有参数。然后,从脚本开始仿真。
该脚本是完全由用户定义的。您可以选择在配置脚本中使用任何有效的Python代码。本书提供了一个样式示例,该样式在Python中高度依赖类和继承。作为gem5用户,由您决定配置脚本的简单或复杂。
gem5在configs/examples中附带了许多示例配置脚本。 这些脚本大多数都是无所不包的,并允许用户在命令行上指定几乎所有选项。 在本书中,我们将从最简单的脚本开始,这些脚本可以运行gem5并从那里构建,而不是从这些复杂的脚本开始。 希望到本节结束时,您将对模拟脚本的工作原理有所了解。
创建一个配置文件
首先创建一个新的配置文件并打开它:
1 | mkdir configs/tutorial |
这只是一个普通的python文件,将由gem5可执行文件中的嵌入式python执行。因此,您可以使用python中可用的任何功能和库。
我们在此文件中要做的第一件事是导入m5库和我们已编译的所有SimObject。
1 | import m5 |
接下来,我们将创建第一个SimObject:我们将要模拟的系统。System对象将是我们模拟系统中所有其他对象的父对象。系统对象包含许多功能(非时序级别)信息,例如物理内存范围,根时钟域,根电压域,内核(在全系统仿真中)等。要创建系统SimObject,我们只是像普通的python类一样实例化它:
1 | system = System() |
现在我们已经有了要模拟的系统的参考,现在让我们在系统上设置时钟。我们首先必须创建一个时钟域。然后,我们可以在该域上设置时钟频率。 在SimObject上设置参数与在python中设置对象的成员完全相同,因此我们可以简单地将时钟设置为1 GHz。最后,我们必须为此时钟域指定一个电压域。由于我们现在不在乎系统电源,因此我们仅将默认选项用于电压域。
1 | system.clk_domain = SrcClockDomain() |
建立系统后,我们来设置如何模拟内存。我们将使用timing模式进行内存模拟。除非在特殊情况下(例如快速转发和从检查点还原),否则几乎将始终使用timing模式进行内存模拟。我们还将设置一个大小为512 MB的单个内存,这是一个非常小的系统。请注意,在python配置脚本中,每当需要size时,您都可以以常见的语言和单位(例如“ 512MB”)指定该大小。同样,您可以使用时间单位(例如“ 5ns”)。这些将分别自动转换为通用表示。
1 | system.mem_mode = 'timing' |
现在,我们可以创建一个CPU。 我们将从gem5中最简单的基于timing的CPU开始,即TimingSimpleCPU。该CPU模型每条指令在单个时钟周期内执行,以执行通过内存系统的内存请求(内存请求除外)。要创建CPU,您只需实例化该对象即可:
1 | system.cpu = TimingSimpleCPU() |
接下来,我们将创建系统范围的内存总线:
1 | system.membus = SystemXBar() |
现在我们有了一条内存总线,让我们将CPU上的缓存端口连接到它。在这种情况下,由于我们要模拟的系统没有任何缓存,因此我们将指令缓存和数据缓存端口直接连接到内存总线。在此示例系统中,我们没有缓存。
1 | system.cpu.icache_port = system.membus.slave |
接下来,我们需要连接其他几个端口,以确保我们的系统正常运行。 我们需要在CPU上创建一个I/O控制器,并将其连接到内存总线。 另外,我们需要将系统中的特殊端口连接到内存总线。 此端口是仅功能端口,用于允许系统读取和写入内存。
将PIO和中断端口连接到内存总线是x86特定的要求。 其他ISA(例如ARM)不需要这3条额外的线。
1 | system.cpu.createInterruptController() |
接下来,我们需要创建一个内存控制器并将其连接到membus。对于此系统,我们将使用一个简单的DDR3控制器,它将负责我们系统的整个内存范围。
1 | system.mem_ctrl = DDR3_1600_8x8() |
在完成这些最终连接之后,我们就完成了对模拟系统的实例化! 我们的系统应该看起来像没有缓存的简单系统配置。
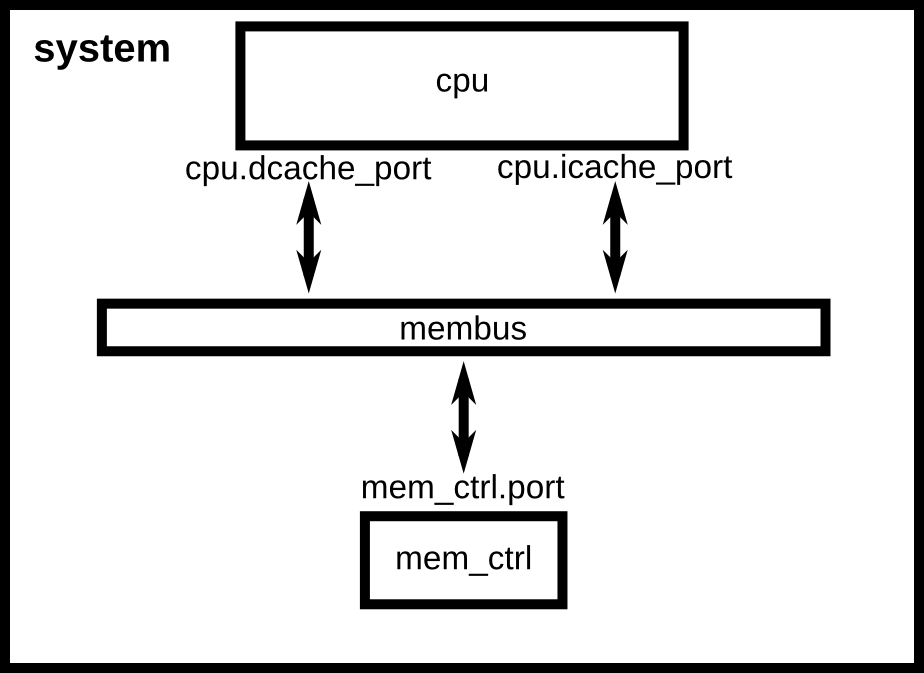
没有缓存的简单系统配置
接下来,我们需要设置希望CPU执行的进程。由于我们以系统调用仿真模式(System Emulation Mode, SE模式)执行,因此我们将CPU指向已编译的可执行文件。我们将执行一个简单的“ Hello world”程序。gem5附带了已编译的版本,因此我们将使用它。您可以指定任何为x86构建的应用程序,这些应用程序都是静态编译的。
首先,我们必须创建process(另一个SimObject)。然后,将process命令设置为要运行的命令。这是一个类似于argv的列表,可执行文件位于第一位置,而可执行文件的参数位于列表的其余部分。 然后,我们将CPU设置为使用进程作为其工作量,并最终在CPU中创建功能执行上下文。
1 | process = Process() |
我们需要做的最后一件事是实例化系统并开始执行。 首先,我们创建Root对象。 然后我们实例化仿真。 实例化过程遍历了我们在python中创建的所有SimObject,并创建了C ++等效项。
注意,您不必实例化python类,然后将参数明确指定为成员变量。 您还可以将参数作为命名参数传递,例如下面的Root对象。
1 | root = Root(full_system = False, system = system) |
最后,我们可以开始实际的模拟了! 顺便说一句,gem5现在正在使用Python 3样式的打印函数,因此print不再是语句,而必须作为函数调用。
1 | print("Beginning simulation!") |
模拟完成后,我们就可以检查系统状态。
1 | print('Exiting @ tick {} because {}' |
运行gem5
现在,我们已经创建了一个简单的模拟脚本(完整版本可以在gem5/configs/learning_gem5/part1/simple.py中找到),我们可以运行gem5。gem5可以采用许多参数,但只需要一个位置参数即模拟脚本。因此,我们可以简单地从根gem5目录运行gem5:
1 | build/X86/gem5.opt configs/tutorial/simple.py |
输出应为:
1 | gem5 Simulator System. http://gem5.org |
可以更改配置文件中的参数,并且结果应该不同。例如,如果您将系统时钟加倍,则模拟应更快地完成。或者,如果将DDR控制器更改为DDR4,性能应该会更好。
此外,您可以将CPU模型更改为MinorCPU以对正序CPU进行建模,或者更改为DerivO3CPU对乱序CPU进行建模。但是,请注意,DerivO3CPU当前无法与simple.py一起使用,因为DerivO3CPU需要一个具有独立指令和数据缓存的系统(DerivO3CPU确实适用于下一部分中的配置)。
接下来,我们将缓存添加到我们的配置文件中,以对更复杂的系统进行建模。
SimObjects私语
gem5的模块化设计围绕SimObject类型构建。 仿真系统中的大多数组件都是SimObject:CPU,缓存,内存控制器,总线等。gem5将所有这些对象从C ++实现导出到python。 因此,从python配置脚本中,您可以创建任何SimObject,设置其参数并指定SimObject之间的交互。
有关更多信息,请参见http://www.gem5.org/SimObjects。
完整系统与系统调用仿真
gem5可以在两种不同的模式下运行,分别称为“系统调用仿真”和“完整系统”或SE和FS模式。在完整系统模式下(稍后在第V部分:完整系统仿真中介绍),gem5仿真整个硬件系统并运行未修改的内核。 完整系统模式类似于运行虚拟机。
另一方面,SE模式不会仿真系统中的所有设备,而是着重于仿真CPU和内存系统。SE更易于配置,因为您无需实例化实际系统中所需的所有硬件设备。 但是,SE只能仿真Linux系统调用,因此只能模拟用户模式代码。
如果您不需要为研究问题建模操作系统,并且想要提高性能,则应使用SE模式。但是,如果您需要对系统进行高保真建模,或者像页面表漫游这样的OS交互很重要,则应使用FS模式。
将缓存添加到配置脚本
以先前的配置脚本为起点,本章将逐步介绍更复杂的配置。如下图所示,我们将向系统添加一个缓存层次结构。此外,本章还将介绍对gem5统计信息的理解,以及向脚本中添加命令行参数的方法。
具有两级缓存层次结构的系统配置
创建缓存对象
我们将使用经典的缓存,而不是Ruby,因为我们正在为单个CPU系统建模,并且我们不在乎对缓存一致性进行建模。我们将扩展Cache SimObject并为我们的系统配置它。首先,我们必须了解用于配置Cache对象的参数。
1 | Todo |
缓存
可以在src/mem/cache/Cache.py中找到Cache SimObject声明。该Python文件定义了您可以设置SimObject的参数。在后台,实例化SimObject时,会将这些参数传递给对象的C++实现。Cache SimObject继承自下面显示的BaseCache对象。
1 | from m5.params import * |
在BaseCache类中,有许多参数。例如,assoc是一个整数参数。在这种情况下,某些参数(例如write_buffers)具有默认值8。除非第一个参数是字符串,否则默认参数是(Param.*)的第一个参数。每个参数的字符串参数是对该参数的描述(例如,tag_latency = Param.Cycles(“ Tag lookup latency”)表示`tag_latency控制“此缓存的命中延迟”)。
其中许多参数没有默认值,因此我们需要在调用m5.instantiate()之前设置这些参数。
现在,要创建具有特定参数的缓存,我们首先要在与simple.py相同的目录configs/tutorial中创建一个新文件caches.py。第一步是导入我们将在此文件中扩展的SimObject。
1 | from m5.objects import Cache |
接下来,我们可以像对待其他任何Python类一样对待BaseCache对象并对其进行扩展。 我们可以根据需要命名新的缓存。让我们首先创建一个L1缓存。
1 | class L1Cache(Cache): |
在这里,我们正在设置BaseCache的一些没有默认值的参数。要查看所有可能的配置选项,并找出哪些是必需的,哪些是可选的,您必须查看SimObject的源代码。在这种情况下,我们正在使用BaseCache。
我们扩展了BaseCache,并在BaseCache SimObject中设置了大多数没有默认值的参数。接下来,让我们再讨论L1Cache的两个子类:L1DCache和L1ICache.
1 | class L1ICache(L1Cache): |
我们还创建一个带有一些合理参数的L2缓存。
1 | class L2Cache(Cache): |
既然我们已经指定了BaseCache所需的所有必要参数,那么我们要做的就是实例化子类并将缓存连接到互连。但是,将许多对象连接到复杂的互连可以使配置文件快速增长并变得不可读。因此,首先让我们向Cache的子类中添加一些辅助函数。请记住,这些只是Python类,因此我们可以对它们执行与Python类一样的任何操作。
在L1高速缓存中,我们添加两个功能:connectCPU将CPU连接到高速缓存,以及connectBus将高速缓存连接到总线。 我们需要将以下代码添加到L1Cache类中。
1 | def connectCPU(self, cpu): |
接下来,我们必须为指令和数据缓存定义一个单独的connectCPU函数,因为指令缓存和数据缓存端口具有不同的名称。现在,我们的L1ICache和L1DCache类变为:
1 | class L1ICache(L1Cache): |
最后,让我们向L2Cache添加函数以分别连接到内存侧和CPU侧总线。
1 | def connectCPUSideBus(self, bus): |
完整文件可在gem5源代码中找到,位于gem5/configs/learning_gem5/part1/caches.py。
添加缓存简单的配置文件
现在,让我们将刚刚创建的缓存添加到上一章中创建的配置脚本中。
首先,让我们将脚本复制到一个新名称。
1 | cp simple.py two_level.py |
首先,我们需要将名称从caches.py文件导入名称空间。我们可以将以下内容添加到文件顶部(在m5.objects导入之后),就像使用任何Python源代码一样。
1 | from caches import * |
现在,在创建CPU之后,让我们创建L1缓存:
1 | system.cpu.icache = L1ICache() |
并使用我们创建的helper函数将缓存连接到CPU端口。
1 | system.cpu.icache.connectCPU(system.cpu) |
我们无法将L1缓存直接连接到L2缓存,因为L2缓存只希望有一个端口连接到它。 因此,我们需要创建一个L2总线以将我们的L1缓存连接到L2缓存。然后,我们可以使用我们的helper函数将L1缓存连接到L2总线。
1 | system.l2bus = L2XBar() |
接下来,我们可以创建L2缓存并将其连接到L2总线和内存总线。
1 | system.l2cache = L2Cache() |
文件中的所有其他内容保持不变!现在,我们有了具有两级缓存层次结构的完整配置。如果您运行当前文件,则您现在应该在58513000个时钟完成操作。完整的脚本可以在gem5源代码中找到,位于gem5/configs/learning_gem5/part1/two_level.py。
向脚本添加参数
使用gem5进行实验时,您不想每次想用不同的参数测试系统时都编辑配置脚本。为了解决这个问题,您可以将命令行参数添加到gem5配置脚本中。同样,由于配置脚本只是Python,因此您可以使用支持参数解析的Python库。尽管optparse已被正式弃用,但gem5随附的许多配置脚本都使用了它,而不是py:mod:argparse,因为gem5的最低Python版本曾经是2.5。Python的最低版本现在是2.7,因此在编写不需要与当前gem5脚本进行交互的新脚本时,py:mod:argparse是一个更好的选择。要开始使用optparse,您可以查阅在线Python文档。
要在二级缓存配置中添加选项,请在导入缓存后添加一些选项。
1 | from optparse import OptionParser |
现在,您可以运行build/X86/gem5.opt configs/tutorial/two_level_opts.py –help,它将显示您刚刚添加的选项。
接下来,我们需要将这些选项传递到我们在配置脚本中创建的缓存上。为此,我们只需更改two_level.py即可将选项作为参数传递给缓存,作为其构造函数的参数,然后添加一个适当的构造函数。
1 | system.cpu.icache = L1ICache(options) |
在caches.py中,我们需要向每个类添加构造函数(Python中的__init__函数)。从基本L1缓存开始,我们将添加一个空的构造函数,因为我们没有适用于基本L1缓存的任何参数。但是,在这种情况下,我们不能忘记调用超类的构造函数。如果跳过对超类构造函数的调用,则在尝试实例化缓存对象时,gem5的SimObject属性查找功能将失败,并且结果将为“ RuntimeError:超出最大递归深度”。因此,在L1Cache中,我们需要在静态类成员之后添加以下内容。
1 | def __init__(self, options=None): |
接下来,在L1ICache中,我们需要使用我们创建的选项(l1i_size)来设置大小。 在下面的代码中,对于没有将选项传递给L1ICache构造函数以及是否在命令行上未指定选项的情况,有一些防护措施。 在这种情况下,我们将使用已经为尺寸指定的默认值。
1 | def __init__(self, options=None): |
我们可以对L1DCache使用相同的代码:
1 | def __init__(self, options=None): |
以及统一的L2Cache:
1 | def __init__(self, options=None): |
通过这些更改,您现在可以从命令行(如下所示)将缓存大小传递到脚本中。
1 | build/X86/gem5.opt configs/tutorial/two_level_opts.py --l2_size='1MB' --l1d_size='128kB' |
运行结果为:
1 | gem5 Simulator System. http://gem5.org |
完整的脚本可以在gem5源代码中找到,位于gem5/configs/learning_gem5/part1/caches.py和gem5/configs/learning_gem5/part1/two_level.py。
了解gem5统计信息和输出
在运行gem5之后,除了可以打印出模拟脚本的所有信息外,在名为m5out的目录中还生成了三个文件:
- config.ini
包含为仿真创建的每个SimObject及其参数值的列表。 - config.json
与config.ini相同,但格式为json。 - stats.txt
为模拟注册的所有gem5统计信息的文本表示形式。
这些文件的创建位置可以通过以下方式控制:
1 | --outdir=DIR, -d DIR |
要创建的目录,其中包含gem5输出文件,包括config.ini,config.json,stats.txt以及其他文件。如果该目录中的文件已经存在,则将其覆盖。
config.ini
该文件是模拟内容的确定版本。 此文件中显示了模拟的每个SimObject的所有参数,无论是在配置脚本中设置还是使用默认值。
下面是运行“创建简单配置脚本”中的simple.py配置文件时生成的config.ini。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59[root]
type=Root
children=system
eventq_index=0
full_system=false
sim_quantum=0
time_sync_enable=false
time_sync_period=100000000000
time_sync_spin_threshold=100000000
[system]
type=System
children=clk_domain cpu dvfs_handler mem_ctrl membus
boot_osflags=a
cache_line_size=64
clk_domain=system.clk_domain
default_p_state=UNDEFINED
eventq_index=0
exit_on_work_items=false
init_param=0
kernel=
kernel_addr_check=true
kernel_extras=
kvm_vm=Null
load_addr_mask=18446744073709551615
load_offset=0
mem_mode=timing
...
[system.membus]
type=CoherentXBar
children=snoop_filter
clk_domain=system.clk_domain
default_p_state=UNDEFINED
eventq_index=0
forward_latency=4
frontend_latency=3
p_state_clk_gate_bins=20
p_state_clk_gate_max=1000000000000
p_state_clk_gate_min=1000
point_of_coherency=true
point_of_unification=true
power_model=
response_latency=2
snoop_filter=system.membus.snoop_filter
snoop_response_latency=4
system=system
use_default_range=false
width=16
master=system.cpu.interrupts.pio system.cpu.interrupts.int_slave system.mem_ctrl.port
slave=system.cpu.icache_port system.cpu.dcache_port system.cpu.interrupts.int_master system.system_port
[system.membus.snoop_filter]
type=SnoopFilter
eventq_index=0
lookup_latency=1
max_capacity=8388608
system=system在这里,我们看到,在每个SimObject的描述开始时,首先是它在配置文件中创建的名称被方括号(例如[system.membus])包围。
接下来,将显示SimObject的每个参数及其值,包括未在配置文件中明确设置的参数。例如,配置文件将时钟域设置为1 GHz(在这种情况下为1000 ticks)。但是,它没有设置高速缓存行大小(系统中为64)对象。
config.ini文件是确保您模拟自己想模拟的东西的有用工具。gem5中有许多设置默认值和覆盖默认值的可能方法。始终检查config.ini是一项明智的选择,这是对配置文件中设置的值是否传播到实际SimObject实例的健全性检查。
stats.txt
gem5具有灵活的统计信息生成系统。gem5 Wiki网站上详细介绍了gem5统计信息。SimObject的每个实例都有自己的统计信息。在模拟结束时,或发出特殊的统计信息转储命令时,所有SimObjects的统计信息的当前状态都转储到文件中。
首先,统计文件包含有关执行的常规统计信息:
1
2
3
4
5
6
7
8
9
10
11
12---------- Begin Simulation Statistics ----------
sim_seconds 0.000346 # Number of seconds simulated
sim_ticks 345518000 # Number of ticks simulated
final_tick 345518000 # Number of ticks from beginning of simulation (restored from checkpoints and never reset)
sim_freq 1000000000000 # Frequency of simulated ticks
host_inst_rate 144400 # Simulator instruction rate (inst/s)
host_op_rate 260550 # Simulator op (including micro ops) rate (op/s)
host_tick_rate 8718625183 # Simulator tick rate (ticks/s)
host_mem_usage 778640 # Number of bytes of host memory used
host_seconds 0.04 # Real time elapsed on the host
sim_insts 5712 # Number of instructions simulated
sim_ops 10314 # Number of ops (including micro ops) simulated统计转储以———-Begin Simulation Statistics———-开始。如果在gem5执行期间存在多个统计转储,则单个文件中可能有多个。 这对于长时间运行的应用程序或从检查点还原时很常见。
每个统计信息都有一个名称(第一列),一个值(第二列)和描述(最后一列以#开头)。
大多数统计信息从其描述中都是可以自我解释的。几个重要的统计信息包括sim_seconds(这是模拟的总模拟时间),sim_insts(这是CPU提交的指令数量)和host_inst_rate(告诉您gem5的性能)。
接下来,将打印SimObjects的统计信息。 例如,内存控制器统计信息。 它具有诸如每个组件读取的字节以及这些组件使用的平均带宽之类的信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25system.clk_domain.voltage_domain.voltage 1 # Voltage in Volts
system.clk_domain.clock 1000 # Clock period in ticks
system.mem_ctrl.pwrStateResidencyTicks::UNDEFINED 507841000 # Cumulative time (in ticks) in various power states
system.mem_ctrl.bytes_read::cpu.inst 58264 # Number of bytes read from this memory
system.mem_ctrl.bytes_read::cpu.data 7167 # Number of bytes read from this memory
system.mem_ctrl.bytes_read::total 65431 # Number of bytes read from this memory
system.mem_ctrl.bytes_inst_read::cpu.inst 58264 # Number of instructions bytes read from this memory
system.mem_ctrl.bytes_inst_read::total 58264 # Number of instructions bytes read from this memory
system.mem_ctrl.bytes_written::cpu.data 7160 # Number of bytes written to this memory
system.mem_ctrl.bytes_written::total 7160 # Number of bytes written to this memory
system.mem_ctrl.num_reads::cpu.inst 7283 # Number of read requests responded to by this memory
system.mem_ctrl.num_reads::cpu.data 1084 # Number of read requests responded to by this memory
system.mem_ctrl.num_reads::total 8367 # Number of read requests responded to by this memory
system.mem_ctrl.num_writes::cpu.data 941 # Number of write requests responded to by this memory
system.mem_ctrl.num_writes::total 941 # Number of write requests responded to by this memory
system.mem_ctrl.bw_read::cpu.inst 114728823 # Total read bandwidth from this memory (bytes/s)
system.mem_ctrl.bw_read::cpu.data 14112685 # Total read bandwidth from this memory (bytes/s)
system.mem_ctrl.bw_read::total 128841507 # Total read bandwidth from this memory (bytes/s)
system.mem_ctrl.bw_inst_read::cpu.inst 114728823 # Instruction read bandwidth from this memory (bytes/s)
system.mem_ctrl.bw_inst_read::total 114728823 # Instruction read bandwidth from this memory (bytes/s)
system.mem_ctrl.bw_write::cpu.data 14098901 # Write bandwidth from this memory (bytes/s)
system.mem_ctrl.bw_write::total 14098901 # Write bandwidth from this memory (bytes/s)
system.mem_ctrl.bw_total::cpu.inst 114728823 # Total bandwidth to/from this memory (bytes/s)
system.mem_ctrl.bw_total::cpu.data 28211586 # Total bandwidth to/from this memory (bytes/s)
system.mem_ctrl.bw_total::total 142940409 # Total bandwidth to/from this memory (bytes/s)该文件的后面是CPU统计信息,其中包含有关syscall数量,分支数量,已提交的指令总数等信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43system.cpu.dtb.walker.pwrStateResidencyTicks::UNDEFINED 507841000 # Cumulative time (in ticks) in various power states
system.cpu.dtb.rdAccesses 1084 # TLB accesses on read requests
system.cpu.dtb.wrAccesses 941 # TLB accesses on write requests
system.cpu.dtb.rdMisses 9 # TLB misses on read requests
system.cpu.dtb.wrMisses 7 # TLB misses on write requests
system.cpu.apic_clk_domain.clock 16000 # Clock period in ticks
system.cpu.interrupts.pwrStateResidencyTicks::UNDEFINED 507841000 # Cumulative time (in ticks) in various power states
system.cpu.itb.walker.pwrStateResidencyTicks::UNDEFINED 507841000 # Cumulative time (in ticks) in various power states
system.cpu.itb.rdAccesses 0 # TLB accesses on read requests
system.cpu.itb.wrAccesses 7284 # TLB accesses on write requests
system.cpu.itb.rdMisses 0 # TLB misses on read requests
system.cpu.itb.wrMisses 31 # TLB misses on write requests
system.cpu.workload.numSyscalls 11 # Number of system calls
system.cpu.pwrStateResidencyTicks::ON 507841000 # Cumulative time (in ticks) in various power states
system.cpu.numCycles 507841 # number of cpu cycles simulated
system.cpu.numWorkItemsStarted 0 # number of work items this cpu started
system.cpu.numWorkItemsCompleted 0 # number of work items this cpu completed
system.cpu.committedInsts 5712 # Number of instructions committed
system.cpu.committedOps 10313 # Number of ops (including micro ops) committed
system.cpu.num_int_alu_accesses 10204 # Number of integer alu accesses
system.cpu.num_fp_alu_accesses 0 # Number of float alu accesses
system.cpu.num_vec_alu_accesses 0 # Number of vector alu accesses
system.cpu.num_func_calls 221 # number of times a function call or return occured
system.cpu.num_conditional_control_insts 986 # number of instructions that are conditional controls
system.cpu.num_int_insts 10204 # number of integer instructions
system.cpu.num_fp_insts 0 # number of float instructions
system.cpu.num_vec_insts 0 # number of vector instructions
system.cpu.num_int_register_reads 19293 # number of times the integer registers were read
system.cpu.num_int_register_writes 7976 # number of times the integer registers were written
system.cpu.num_fp_register_reads 0 # number of times the floating registers were read
system.cpu.num_fp_register_writes 0 # number of times the floating registers were written
system.cpu.num_vec_register_reads 0 # number of times the vector registers were read
system.cpu.num_vec_register_writes 0 # number of times the vector registers were written
system.cpu.num_cc_register_reads 7020 # number of times the CC registers were read
system.cpu.num_cc_register_writes 3825 # number of times the CC registers were written
system.cpu.num_mem_refs 2025 # number of memory refs
system.cpu.num_load_insts 1084 # Number of load instructions
system.cpu.num_store_insts 941 # Number of store instructions
system.cpu.num_idle_cycles 0 # Number of idle cycles
system.cpu.num_busy_cycles 507841 # Number of busy cycles
system.cpu.not_idle_fraction 1 # Percentage of non-idle cycles
system.cpu.idle_fraction 0 # Percentage of idle cycles
system.cpu.Branches 1306 # Number of branches fetched
使用默认配置脚本
在本章中,我们将探索使用gem5随附的默认配置脚本。gem5附带了许多配置脚本,可让您非常快速地使用gem5。但是,常见的陷阱是使用这些脚本而没有完全了解要模拟的内容。在使用gem5进行计算机体系结构研究时,充分了解要模拟的系统非常重要。本章将引导您完成一些重要的选项以及默认配置脚本的各个部分。
在最后几章中,您是从头开始创建自己的配置脚本的。这非常强大,因为它允许您指定每个单个系统参数。但是,某些系统的设置非常复杂(例如,全系统ARM或x86计算机)。幸运的是,gem5开发人员提供了许多脚本来引导构建系统的过程。
目录结构浏览
gem5的所有配置文件都可以在configs/中找到。 目录结构如下所示:
1 | configs/boot: |
每个目录的简要说明如下:
- boot/
这些是在完整系统模式下使用的rcS文件。这些文件在Linux引导后由模拟器加载,并由Shell执行。在全系统模式下运行时,其中大多数用于控制基准。其中一些是实用程序功能,例如hack_back_ckpt.rcS。 这些文件将在全系统仿真一章中更深入地介绍。 - common/
该目录包含许多帮助程序脚本和创建模拟系统的功能。例如,Caches.py与前面各章中创建的caches.py和caches_opts.py文件相似。
Options.py包含可以在命令行上设置的各种选项。 像CPU的数量,系统时钟等等。 这是查看是否要更改的选项是否已包含命令行参数的好地方。
CacheConfig.py包含用于设置经典内存系统的缓存参数的选项和功能。
MemConfig.py提供了一些用于设置内存系统的帮助程序功能。
FSConfig.py包含必要的功能,可为许多不同类型的系统设置全系统仿真。全系统仿真将在本章中进一步讨论。
Simulation.py包含许多帮助函数,用于设置和运行gem5。此文件中包含的许多代码都用于管理保存和还原检查点。下列example/中的示例配置文件使用该文件中的功能来执行gem5仿真。该文件非常复杂,但是它在模拟的运行方式上也提供了很大的灵活性。 - dram/
包含用于测试DRAM的脚本。 - example/
该目录包含一些示例gem5配置脚本,可以直接使用它们来运行gem5。具体来说,se.py和fs.py非常有用。有关这些文件的更多信息,请参见下一部分。此目录中还有一些其他实用程序配置脚本。 - ruby/
此目录包含Ruby及其随附的缓存一致性协议的配置脚本。更多细节可以在Ruby一章中找到。 - splash2/
该目录包含用于运行splash2基准套件的脚本,其中包含一些用于配置模拟系统的选项。 - topologies/
该目录包含创建Ruby缓存层次结构时可以使用的拓扑的实现。更多细节可以在Ruby一章中找到。
使用se.py和fs.py
在本节中,我将讨论一些可以在命令行上传递给se.py和fs.py的常用选项。有关如何运行全系统模拟的更多详细信息,请参见“全系统模拟”一章。在这里,我将讨论两个文件共有的选项。
本节中讨论的大多数选项都可以在Options.py中找到,并已在addCommonOptions函数中注册。本节未详细介绍所有选项,要查看所有选项,请使用–help运行配置脚本,或阅读脚本的源代码。
首先,我们简单地运行不带任何参数的hello world程序:
1 | build/X86/gem5.opt configs/example/se.py --cmd=tests/test-progs/hello/bin/x86/linux/hello |
并获得以下输出:
1 | gem5 Simulator System. http://gem5.org |
但是,这根本不是一个非常有趣的模拟!默认情况下,gem5使用原子CPU并使用原子内存访问,因此没有实际的时序数据报告!要确认这一点,您可以查看m5out/config.ini。CPU显示在第46行:
1 | [system.cpu] |
要在计时模式下实际运行gem5,请指定CPU类型。在此期间,我们还可以指定L1缓存的大小。
1 | build/X86/gem5.opt configs/example/se.py --cmd=tests/test-progs/hello/bin/x86/linux/hello --cpu-type=TimingSimpleCPU --l1d_size=64kB --l1i_size=16kB |
现在,让我们检查config.ini文件,并确保将这些选项正确传播到最终系统。 如果在m5out/config.ini中搜索“cache”,则会发现未创建任何缓存! 即使我们指定了缓存的大小,也没有指定系统应使用缓存,因此未创建缓存。 正确的命令行应为:
1 | build/X86/gem5.opt configs/example/se.py --cmd=tests/test-progs/hello/bin/x86/linux/hello --cpu-type=TimingSimpleCPU --l1d_size=64kB --l1i_size=16kB --caches |
在最后一行,我们看到总时间从344986500个周期变为29480500个周期,速度要快得多!看起来缓存现在可能已启用。但是,最好再次检查config.ini文件。
1 | [system.cpu.dcache] |
se.py和fs.py一些常见的选项
运行如下指令时会打印所有可能的选项:
1 | build/X86/gem5.opt configs/example/se.py --help |
以下是该列表中的一些重要选项。
- –cpu-type=CPU_TYPE
要运行的cpu的类型。这是始终设置的重要参数。默认值为atomic,它不执行时序仿真。 - –sys-clock=SYS_CLOCK
以系统速度运行的块的顶层时钟。 - –cpu-clock=CPU_CLOCK
以CPU速度运行的块的时钟。这与上面的系统时钟是分开的。 - –mem-type=MEM_TYPE
要使用的内存类型。选项包括不同的DDR内存和ruby内存控制器。 - –caches
使用经典缓存执行仿真。 - –l2cache
如果使用经典缓存,请使用L2缓存执行仿真。 - –ruby
使用Ruby代替传统的高速缓存作为高速缓存系统模拟。 - -m TICKS, –abs-max-tick=TICKS
运行到指定的绝对模拟周期,包括来自已还原检查点的周期。如果您只想模拟一定数量的模拟时间,这将很有用。 - -I MAXINSTS, –maxinsts=MAXINSTS
要模拟的指令总数(默认值:永远运行)。如果要在执行一定数量的指令后停止仿真,此功能很有用。 - -c CMD, –cmd=CMD
在系统调用仿真模式下运行的二进制文件。 - -o OPTIONS, –options=OPTIONS
传递给二进制文件的选项,使用“”扩起整个字符串。当您运行带有选项的命令时,这很有用。您可以通过此变量传递参数和选项(例如–whatever)。 - –output=OUTPUT
将标准输出重定向到文件。如果您想将模拟应用程序的输出重定向到文件而不是打印到屏幕,这将很有用。注意:要重定向gem5输出,必须在配置脚本之前传递参数。 - –errout=ERROUT
将stderr重定向到文件。与上面类似。
第二部分:修改和扩展gem5
设置您的开发环境
这将谈论开始开发gem5的问题。
gem5样式准则
修改任何开源项目时,请务必遵循项目的样式准则。您可以在gem5 Wiki页面上找到有关gem5样式的详细信息。
为了帮助您符合样式准则,gem5包含一个脚本,该脚本在您在git中提交变更集时运行。首次构建gem5时,SCons应将此脚本自动添加到您的.git/config文件中。请不要忽略这些警告/错误。但是,在极少数情况下,如果您尝试提交不符合gem5样式准则的文件(例如,gem5源代码树之外的内容),则可以使用git选项–no-verify跳过运行 样式检查器。
样式指南的主要内容是:
- 使用4个空格,而不是制表符
- 排序包含
- 对于类名,请使用大写的驼峰大小写;对于成员变量,请使用驼峰大小写;对于局部变量,请使用下划线。
- 注释您的代码
git分支
大多数使用gem5开发的人都使用git的分支功能来跟踪他们的更改。这使得将更改提交回gem5非常简单。此外,使用分支可以使其他人进行的新更改更容易更新gem5,同时将您自己的更改分开Git书中有一章很棒,描述了如何使用分支的细节。
创建一个非常简单的SimObject
gem5中几乎所有对象都继承自基本SimObject类型。SimObjects将主接口导出到gem5中的所有对象。SimObject是包装的C ++对象,可从Python配置脚本访问。
SimObjects可以具有许多参数,这些参数是通过Python配置文件设置的。除了简单的参数(例如整数和浮点数)外,它们还可以具有其他SimObjects作为参数。这使您可以创建复杂的系统层次结构,例如真实的计算机。
在本章中,我们将逐步创建一个简单的“ HelloWorld” SimObject。目的是向您介绍如何创建SimObject,以及所有SimObject所需的样板代码。我们还将创建一个简单的Python配置脚本来实例化SimObject。
在接下来的几章中,我们将使用这个简单的SimObject并对其进行扩展,以包括调试支持,动态事件和参数。
步骤1:为新的SimObject创建一个Python类
每个SimObject都有一个与之关联的Python类。此类Python描述了可以从Python配置文件中控制的SimObject的参数。对于我们简单的SimObject,我们将从没有任何参数开始。因此,我们只需要为SimObject声明一个新类并设置其名称和C ++头文件即可定义SimObject的C ++类。
我们可以在src/learning_gem5中创建一个文件HelloObject.py
1 | from m5.params import * |
您可以在此处找到完整的文件。
不需要类型与类的名称相同,但这是约定。该类型是您与此Python SimObject包装的C ++类。仅在特殊情况下,类型和类名才可以不同。
cxx_header是包含用作类型参数的类的声明的文件。同样,惯例是将SimObject的名称全部使用小写和下划线,但这只是惯例。您可以在此处指定任何头文件。
步骤2:在C ++中实现SimObject
接下来,我们需要创建hello_object.hh和hello_object.cc,它们将实现hello对象。
我们将从C ++对象的头文件开始。按照约定,gem5将所有头文件包装在#ifndef /#endif中,并带有文件名和其所在目录,因此没有循环包含。
我们在文件中唯一需要做的就是声明我们的类。由于HelloObject是SimObject,因此它必须继承自C ++ SimObject类。在大多数情况下,您的SimObject的父级将是SimObject的子类,而不是SimObject本身。
SimObject类指定许多虚函数。 但是,这些功能都不是纯虚函数,因此在最简单的情况下,除了构造函数外,无需实现任何功能。
所有SimObjects的构造函数都假定它将接收一个参数对象。这个参数对象是由构建系统自动创建的,并且基于SimObject的Python类,就像我们上面创建的那样。该参数类型的名称是根据对象的名称自动生成的。对于我们的“ HelloObject”,参数类型的名称为“ HelloObject ** Params **”。
下面列出了我们的简单头文件所需的代码。
1 |
|
您可以在此处找到完整的文件。
接下来,我们需要在.cc文件中实现两个功能,而不仅仅是一个。第一个函数是HelloObject的构造函数。在这里,我们只是将参数对象传递给SimObject父对象,并输出“ Hello world!”。
通常,您永远不会在gem5中使用std::cout。相反,您应该使用调试标志。在下一章中,我们将对其进行修改以改为使用调试标志。但是,由于它很简单,我们暂时仅使用std::cout。
1 |
|
为了使SimObject完整,我们还必须实现另一个功能。我们必须为从SimObject Python声明隐式创建的参数类型实现一个函数,即create函数。此函数仅返回SimObject的新实例。 通常,此功能非常简单(如下所示)。
1 | HelloObject* |
您可以在此处找到完整的文件。
如果忘记为SimObject添加create函数,则在编译时会出现链接器错误。 它将类似于以下内容。
1 | build/X86/python/m5/internal/param_HelloObject_wrap.o: In function `_wrap_HelloObjectParams_create': |
对“ HelloObjectParams::create()”的未定义引用意味着您需要为SimObject实现create函数。
步骤3:注册SimObject和C ++文件
为了编译C ++文件和解析Python文件,我们需要将这些文件告知构建系统。gem5使用SCons作为构建系统,因此您只需在目录中使用SimObject的代码创建一个SConscript文件。如果该目录已经有一个SConscript文件,只需将以下声明添加到该文件中。
该文件只是普通的Python文件,因此您可以在该文件中编写所需的任何Python代码。一些脚本可能变得非常复杂。gem5利用此功能自动为SimObjects创建代码并编译特定于域的语言,例如SLICC和ISA语言。
在SConscript文件中,导入后会自动定义许多功能。请参阅有关该部分的内容…
1 | Todo |
要编译新的SimObject,只需在src/learning_gem5目录中创建一个名称为“SConscript”的新文件。在此文件中,您必须声明SimObject和.cc文件。以下是必需的代码。
1 | Import('*') |
您可以在此处找到完整的文件。
第4步:(重新)构建gem5
要编译和链接新文件,您只需要重新编译gem5。下面的示例假定您使用的是x86 ISA,但是我们的对象中没有任何东西需要ISA,因此,它可以与gem5的任何ISA一起使用。
1 | scons build/X86/gem5.opt |
步骤5:创建配置脚本以使用新的SimObject
既然已经实现了SimObject,并且已将其编译到gem5中,则需要创建或修改Python配置文件以实例化对象。由于您的对象非常简单,因此不需要系统对象!除了Root对象外,不需要CPU,缓存或其他任何东西。所有gem5实例都需要一个Root对象。
逐步创建一个非常简单的配置脚本,首先,导入m5和所有已编译的对象。
1 | import m5 |
接下来,您必须根据所有gem5实例的要求实例化Root对象。
1 | root = Root(full_system = False) |
现在,您可以实例化创建的HelloObject。您需要做的就是调用Python“构造函数”。稍后,我们将研究如何通过Python构造函数指定参数。除了创建对象的实例化之外,还需要确保它是root对象的子对象。只有作为Root对象的子对象的SimObjects才会在C ++中实例化。
1 | root.hello = HelloObject() |
最后,您需要在m5模块上调用实例化并实际运行仿真!
1 | m5.instantiate() |
您可以在此处找到完整的文件。
输出应类似于以下内容:
1 | gem5 Simulator System. http://gem5.org |
恭喜!您已经编写了第一个SimObject。在下一章中,我们将扩展此SimObject,并探索您可以使用SimObjects进行的操作。
使用git分支
对于添加到gem5的每个新功能,通常都使用一个新的git分支。
添加新功能或修改gem5中的第一步时,是创建一个新分支来存储您的更改。 git分支的详细信息可以在Git书中找到。
1 | git checkout -b hello-simobject |
调试gem5
在前面的章节中,我们介绍了如何创建非常简单的SimObject。在本章中,我们将用gem5的调试支持将简单的打印内容替换为stdout。
gem5通过调试标志提供对printf样式的代码跟踪/调试的支持。这些标志允许每个组件具有许多调试打印语句,而不必同时启用所有这些语句。运行gem5时,您可以从命令行指定要启用的调试标志。
使用调试标志
例如,运行“创建简单配置脚本”中的第一个simple.py脚本时,如果启用DRAM调试标志,则会得到以下输出。 请注意,这会向控制台生成大量输出(大约7 MB)。
1 | build/X86/gem5.opt --debug-flags=DRAM configs/learning_gem5/part1/simple.py | head -n 50 |
1 | gem5 Simulator System. http://gem5.org |
或者,您可能希望根据CPU正在执行的确切指令进行调试。为此,Exec调试标志可能会很有用。该调试标志显示了模拟CPU如何执行每条指令的详细信息。
1 | build/X86/gem5.opt --debug-flags=Exec configs/learning_gem5/part1/simple.py | head -n 50 |
1 | gem5 Simulator System. http://gem5.org |
实际上,Exec标志实际上是多个调试标志的集合。通过使用–debug-help参数运行gem5,可以看到此信息以及所有可用的调试标志。
1 | build/X86/gem5.opt --debug-help |
1 | Base Flags: |
添加一个新的调试标志
在前面的章节中,我们使用了一个简单的std::cout从SimObject中进行打印。虽然可以在gem5中使用普通的C/C++ I/O,但强烈建议不要这样做。因此,我们现在将使用gem5的调试工具替换它。
创建新的调试标志时,我们首先必须在SConscript文件中对其进行声明。将以下内容添加到你的hello对象代码目录中(src/learning_gem5/)的SConscript文件中。
1 | DebugFlag('Hello') |
这声明调试标志为“ Hello”。现在,我们可以在SimObject的调试语句中使用它。
通过在SConscript文件中声明该标志,将自动生成一个调试标头,使我们可以使用调试标志。头文件在debug目录中,并且具有与我们在SConscript文件中声明的名称相同的名称(和大小写)。因此,我们需要在计划使用debug标志的任何文件中包含自动生成的头文件。
在hello_object.cc文件中,我们需要包括头文件。
1 |
现在我们已经包含了必要的头文件,让我们将std::cout调用替换为这样的调试语句。
1 | DPRINTF(Hello, "Created the hello object\n"); |
DPRINTF是C ++宏。第一个参数是已在SConscript文件中声明的调试标志。我们可以使用标志Hello,因为我们在src/learning_gem5/SConscript文件中声明了它。其余参数是可变的,可以是传递给printf语句的任何参数。
现在,如果重新编译gem5并使用“Hello”调试标志运行它,您将得到以下结果。
1 | build/X86/gem5.opt --debug-flags=Hello configs/learning_gem5/part2/run_hello.py |
1 | gem5 Simulator System. http://gem5.org |
您可以在这里找到更新的SConcript文件,并在这里找到更新的hello对象代码。
调试输出
略
使用DPRINTF以外的功能
DPRINTF是gem5中最常用的调试功能。但是,gem5提供了许多其他功能,这些功能在特定情况下很有用。
DPRINTF(Flag,__VA_ARGS__)
带有一个标志和一个格式字符串以及任何格式参数。此函数要求当前作用域中有一个name()函数(例如,从SimObject成员函数调用)。仅在启用标志时才打印格式化的字符串。DTRACE(Flag)
如果启用了标志(Flag),则返回true,否则返回false。仅当启用调试标志(标志)时,这对于执行某些代码很有用。DDUMP(Flag,data,count)
打印长度计数字节的二进制数据(数据)。以用户可读的方式将其格式化为十六进制。该宏还假定调用范围包含一个name()函数。DPRINTFS(Flag,SimObject,__VA_ARGS__)
像DPRINTF()一样,只是需要一个额外的参数,该参数是具有name()函数的对象,通常是SimObject。对于从具有指向其所有者的指针的SimObject的私有子类中进行调试,此功能很有用。DPRINTFR(Flag,__VA_ARGS__)
此函数输出调试语句,而不输出名称。对于在不是没有name()函数的SimObjects的对象中使用调试语句,这很有用。DDUMPN(data,count)
DPRINTFN(__VA_ARGS__)
这些函数与以前的函数DDUMP(),DPRINTF()和DPRINTFR()相似,不同之处在于它们不使用标志作为参数。因此,无论何时启用调试,这些语句将始终打印。DPRINTFNR(__VA_ARGS__)
只有在“ opt”或“ debug”模式下编译gem5时,才能启用所有这些功能。所有其他模式都为上述功能使用空的占位符宏。因此,如果要使用调试标志,则必须使用“ gem5.opt”或“ gem5.debug”。
事件驱动的编程
gem5是事件驱动的模拟器。在本章中,我们将探讨如何创建和安排事件。我们将从创建一个非常简单的SimObject的简单HelloObject进行构建。
创建一个简单的事件回调
在gem5的事件驱动模型中,每个事件都有一个回调函数来处理该事件。通常,这是一个从Event继承的类。但是,gem5提供了用于创建简单事件的包装器功能。
在HelloObject的头文件中,我们只需要声明一个每次事件触发时要执行的新函数(processEvent())。此函数必须不带任何参数,并且不返回任何值。
接下来,我们添加一个Event实例。 在这种情况下,我们将使用EventFunctionWrapper,它允许我们执行任何功能。
我们还添加了一个startup()函数,下面将对其进行说明。
1 | class HelloObject : public SimObject |
接下来,我们必须在HelloObject的构造函数中构造此事件。EventFuntionWrapper具有两个参数,一个要执行的函数和一个名称。该名称通常是拥有事件的SimObject的名称。打印名称时,名称末尾会自动附加一个“ .wrapped_function_event”。
第一个参数只是一个不带参数且没有返回值的函数(std :: function <void(void)>)。通常,这是一个调用成员函数的简单lambda函数。但是,它可以是您想要的任何功能。 下面,我们在lambda([this])中对其进行介绍,以便我们可以调用该类实例的成员函数。
1 | HelloObject::HelloObject(HelloObjectParams *params) : |
我们还必须定义流程功能的实现。 在这种情况下,如果要调试,我们将只打印一些内容。
1 | void |
调度事件
最后,对于要处理的事件,我们首先必须调度事件。为此,我们使用schedule()函数。此函数在将来的某个时间安排某个事件的某个实例(事件驱动的模拟不允许事件在过去执行)。
1 | schedule(Event *event, Tick when) |
Learning Gem5 (Chinese Version)
简介
这是本教程的简介,它说了很多有趣的事情。
本文档的目的是向读者提供有关如何使用gem5和gem5代码库的全面介绍。本文档的目的不是提供gem5中每个功能的详细描述。阅读完本文档后,您应该在教室和计算机体系结构研究中使用gem5感到很自在。另外,您应该能够修改和扩展gem5,然后将其改进贡献到主要的gem5存储库中。
这份文件的背景是我在威斯康星大学麦迪逊分校(University of Wisconsin-Madison)读研究生时在过去六年中对gem5的亲身经历。所提供的示例只是做到这一点的一种方法。 与Python不同,Python的口头禅是“应该有一种-最好只有一种-明显的方式来做到这一点。” (来自Python的Zen。请参见import this),在gem5中,有多种不同的方法可以完成同一件事。因此,本书提供的许多示例都是我认为最好的处理方式的观点。
我学到的重要一课(困难的方法)是,在使用诸如gem5之类的复杂工具时,在使用它之前实际了解其工作原理非常重要。
Todo
完成上一段,这是了解如何实际使用工具的一个好主意。
Todo
应该添加一个术语列表。 诸如“模拟系统”与“主机系统”之类的东西。
您可以在github上找到这本书的源代码: https://github.com/powerjg/learning_gem5
第一部分:gem5入门
构建gem5
本章详细介绍如何设置gem5开发环境和构建gem5。
Todo
添加一个指向gem5 docker镜像的指针。 实际上,我们可能希望每个部分都有一个docker映像。
gem5的环境要求
有关更多详细信息,请参见gem5要求。
在Ubuntu上,您可以使用以下命令安装所有必需的依赖项。 要求详细说明如下。
sudo apt install build-essential git m4 scons zlib1g zlib1g-dev libprotobuf-dev protobuf-compiler libprotoc-dev libgoogle-perftools-dev python-dev python
- git(Git)
gem5项目使用Git进行版本控制。 Git是一个分布式版本控制系统。 通过链接可以找到有关Git的更多信息。 默认情况下,应在大多数平台上安装Git。 但是,要在Ubuntu中安装Git,请使用:sudo apt-get install git
- gcc 4.8+
您可能需要使用环境变量来指向gcc的非默认版本。
在Ubuntu上,您可以使用以下命令安装开发环境:sudo apt-get install build-essential
- SCons
gem5使用SCons作为其构建环境。SCons就像在快速建筑上制造一样,并且在构建过程的所有方面都使用Python脚本,这是一个非常灵活(但很慢)的构建系统。
要在Ubuntu上使用SCons:sudo apt-get install scons
- Python 2.7+
gem5依赖于Python开发库。 要在Ubuntu上安装它们,请使用:sudo apt-get install python-dev
- protobuf 2.1+
“protocol buffers是一种与语言无关,与平台无关的可扩展机制,用于序列化结构化数据。” 在gem5中,protobuf库用于跟踪生成和回放。 protobuf不是必需的软件包,除非您计划将其用于跟踪生成和回放。sudo apt-get install libprotobuf-dev python-protobuf protobuf-compiler libgoogle-perftools-dev
获取代码
将目录更改为要下载gem5源的位置。 然后,要克隆存储库,请使用git clone命令。
现在,您可以将目录更改为包含所有gem5代码的gem5。
你的第一次构建gem5
让我们开始构建一个基本的x86系统。当前,您必须为要模拟的每个ISA分别编译gem5。此外,如果使用Ruby简介,则每个缓存一致性协议都必须具有单独的编译。
要构建gem5,我们将使用SCons。SCons使用SConstruct文件(gem5/SConstruct)设置许多变量,然后在每个子目录中使用SConscript文件查找和编译所有gem5源。
第一次执行时,SCons会自动创建gem5/build目录。在此目录中,您会找到由SCons,编译器等生成的文件。用于编译gem5的每组选项(ISA和缓存一致性协议)将有一个单独的目录。
build_opts目录中有许多默认编译选项。这些文件指定最初构建gem5时传递给SCons的参数。我们将使用X86默认值,并指定我们要编译所有CPU模型。您可以查看文件build_opts/X86来查看Scons选项的默认值。您也可以在命令行上指定这些选项以覆盖任何默认值。
scons build/X86/gem5.opt -j9
传递给SCons的主要参数是您要构建的内容 —— build/X86/gem5.opt。在这种情况下,我们将构建gem5.opt(带有调试符号的优化二进制文件)。 我们要在目录build/X86中构建gem5。由于该目录当前不存在,SCons将在build_opts中查找X86的默认参数。(注意:我在这里使用-j9在我的计算机上的8个内核中的9个内核上执行构建。您应该为计算机选择一个合适的编号,通常为cores + 1。)
输出应如下所示:
Checking for C header file Python.h… yes
Checking for C library pthread… yes
Checking for C library dl… yes
Checking for C library util… yes
Checking for C library m… yes
Checking for C library python2.7… yes
Checking for accept(0,0,0) in C++ library None… yes
Checking for zlibVersion() in C++ library z… yes
Checking for GOOGLE_PROTOBUF_VERIFY_VERSION in C++ library protobuf… yes
Checking for clock_nanosleep(0,0,NULL,NULL) in C library None… yes
Checking for timer_create(CLOCK_MONOTONIC, NULL, NULL) in C library None… no
Checking for timer_create(CLOCK_MONOTONIC, NULL, NULL) in C library rt… yes
Checking for C library tcmalloc… yes
Checking for backtrace_symbols_fd((void*)0, 0, 0) in C library None… yes
Checking for C header file fenv.h… yes
Checking for C header file linux/kvm.h… yes
Checking size of struct kvm_xsave … yes
Checking for member exclude_host in struct perf_event_attr…yes
Building in /local.chinook/gem5/gem5-tutorial/gem5/build/X86
Variables file /local.chinook/gem5/gem5-tutorial/gem5/build/variables/X86 not found,
using defaults in /local.chinook/gem5/gem5-tutorial/gem5/build_opts/X86
scons: done reading SConscript files.
scons: Building targets …
[ISA DESC] X86/arch/x86/isa/main.isa -> generated/inc.d
[NEW DEPS] X86/arch/x86/generated/inc.d -> x86-deps
[ENVIRONS] x86-deps -> x86-environs
[ CXX] X86/sim/main.cc -> .o
….
….
….
[ SHCXX] nomali/lib/mali_midgard.cc -> .os
[ SHCXX] nomali/lib/mali_t6xx.cc -> .os
[ SHCXX] nomali/lib/mali_t7xx.cc -> .os
[ AR] -> drampower/libdrampower.a
[ SHCXX] nomali/lib/addrspace.cc -> .os
[ SHCXX] nomali/lib/mmu.cc -> .os
[ RANLIB] -> drampower/libdrampower.a
[ SHCXX] nomali/lib/nomali_api.cc -> .os
[ AR] -> nomali/libnomali.a
[ RANLIB] -> nomali/libnomali.a
[ CXX] X86/base/date.cc -> .o
[ LINK] -> X86/gem5.opt
scons: done building targets.
编译完成后,您应该在build/X86/gem5.opt中有一个可运行的gem5可执行文件。编译可能会花费很长的时间,通常是15分钟或更长时间,尤其是在使用AFS或NFS之类的远程文件系统进行编译时。
gem5二进制类型
gem5中的SCons脚本当前具有5种可以为gem5构建的二进制文件:debug,opt,fast,prof和perf。 这些名称大多是不言自明的,但在下面进行了详细说明。
- debug
无需优化和调试符号即可构建。如果使用gem5的opt版本优化了要查看的变量,则使用调试器进行调试时,此二进制文件很有用。 与其他二进制文件相比,使用debug进行运行速度较慢。 - opt
该二进制文件是使用(例如-O3)的大多数优化构建的,但其中包含调试符号。该二进制文件比debug速度快得多,但是仍然包含足够的调试信息以能够调试大多数问题。 - fast
内置所有优化(包括受支持平台上的链接时优化),并且没有调试符号。 此外,所有断言都被删除,但仍然包括恐慌和致命事件。fast是性能最高的二进制文件,比opt小得多。但是,只有在您认为代码不太可能出现重大错误时,才需要使用fast。 - prof和perf
这两个二进制文件是为分析gem5而构建的。prof包含有关GNU Profiler(gprof)的分析信息,而perf包含有关Google性能工具(gperftools)的分析信息。
常见错误
略!!!
创建一个简单的配置脚本
本教程的这一章将引导您逐步了解如何为gem5设置简单的仿真脚本以及如何首次运行gem5。 假设您已完成本教程的第一章,并且已成功使用可执行文件build/X86/gem5.opt构建了gem5。
我们的配置脚本将为一个非常简单的系统建模。我们只有一个简单的CPU内核。 该CPU内核将连接到系统范围的内存总线。而且,我们将有一个DDR3内存通道,该通道也已连接到内存总线。
gem5配置脚本
gem5二进制文件以设置和执行模拟的python脚本作为参数。在此脚本中,您将创建一个系统来模拟,创建系统的所有组件并指定系统组件的所有参数。然后,从脚本开始仿真。
该脚本是完全由用户定义的。您可以选择在配置脚本中使用任何有效的Python代码。本书提供了一个样式示例,该样式在Python中高度依赖类和继承。作为gem5用户,由您决定配置脚本的简单或复杂。
gem5在configs/examples中附带了许多示例配置脚本。 这些脚本大多数都是无所不包的,并允许用户在命令行上指定几乎所有选项。 在本书中,我们将从最简单的脚本开始,这些脚本可以运行gem5并从那里构建,而不是从这些复杂的脚本开始。 希望到本节结束时,您将对模拟脚本的工作原理有所了解。
创建一个配置文件
首先创建一个新的配置文件并打开它:
mkdir configs/tutorial
touch configs/tutorial/simple.py
这只是一个普通的python文件,将由gem5可执行文件中的嵌入式python执行。因此,您可以使用python中可用的任何功能和库。
我们在此文件中要做的第一件事是导入m5库和我们已编译的所有SimObject。
import m5
from m5.objects import *
接下来,我们将创建第一个SimObject:我们将要模拟的系统。System对象将是我们模拟系统中所有其他对象的父对象。系统对象包含许多功能(非时序级别)信息,例如物理内存范围,根时钟域,根电压域,内核(在全系统仿真中)等。要创建系统SimObject,我们只是像普通的python类一样实例化它:
system = System()
现在我们已经有了要模拟的系统的参考,现在让我们在系统上设置时钟。我们首先必须创建一个时钟域。然后,我们可以在该域上设置时钟频率。 在SimObject上设置参数与在python中设置对象的成员完全相同,因此我们可以简单地将时钟设置为1 GHz。最后,我们必须为此时钟域指定一个电压域。由于我们现在不在乎系统电源,因此我们仅将默认选项用于电压域。
system.clk_domain = SrcClockDomain()
system.clk_domain.clock = ‘1GHz’
system.clk_domain.voltage_domain = VoltageDomain()
建立系统后,我们来设置如何模拟内存。我们将使用timing模式进行内存模拟。除非在特殊情况下(例如快速转发和从检查点还原),否则几乎将始终使用timing模式进行内存模拟。我们还将设置一个大小为512 MB的单个内存,这是一个非常小的系统。请注意,在python配置脚本中,每当需要size时,您都可以以常见的语言和单位(例如“ 512MB”)指定该大小。同样,您可以使用时间单位(例如“ 5ns”)。这些将分别自动转换为通用表示。
system.mem_mode = ‘timing’
system.mem_ranges = [AddrRange(‘512MB’)]
现在,我们可以创建一个CPU。 我们将从gem5中最简单的基于timing的CPU开始,即TimingSimpleCPU。该CPU模型每条指令在单个时钟周期内执行,以执行通过内存系统的内存请求(内存请求除外)。要创建CPU,您只需实例化该对象即可:
system.cpu = TimingSimpleCPU()
接下来,我们将创建系统范围的内存总线:
system.membus = SystemXBar()
现在我们有了一条内存总线,让我们将CPU上的缓存端口连接到它。在这种情况下,由于我们要模拟的系统没有任何缓存,因此我们将指令缓存和数据缓存端口直接连接到内存总线。在此示例系统中,我们没有缓存。
system.cpu.icache_port = system.membus.slave
system.cpu.dcache_port = system.membus.slave
接下来,我们需要连接其他几个端口,以确保我们的系统正常运行。 我们需要在CPU上创建一个I/O控制器,并将其连接到内存总线。 另外,我们需要将系统中的特殊端口连接到内存总线。 此端口是仅功能端口,用于允许系统读取和写入内存。
将PIO和中断端口连接到内存总线是x86特定的要求。 其他ISA(例如ARM)不需要这3条额外的线。
system.cpu.createInterruptController()
system.cpu.interrupts[0].pio = system.membus.master
system.cpu.interrupts[0].int_master = system.membus.slave
system.cpu.interrupts[0].int_slave = system.membus.mastersystem.system_port = system.membus.slave
接下来,我们需要创建一个内存控制器并将其连接到membus。对于此系统,我们将使用一个简单的DDR3控制器,它将负责我们系统的整个内存范围。
system.mem_ctrl = DDR3_1600_8x8()
system.mem_ctrl.range = system.mem_ranges[0]
system.mem_ctrl.port = system.membus.master
在完成这些最终连接之后,我们就完成了对模拟系统的实例化! 我们的系统应该看起来像没有缓存的简单系统配置。
没有缓存的简单系统配置
接下来,我们需要设置希望CPU执行的进程。由于我们以系统调用仿真模式(System Emulation Mode, SE模式)执行,因此我们将CPU指向已编译的可执行文件。我们将执行一个简单的“ Hello world”程序。gem5附带了已编译的版本,因此我们将使用它。您可以指定任何为x86构建的应用程序,这些应用程序都是静态编译的。
首先,我们必须创建process(另一个SimObject)。然后,将process命令设置为要运行的命令。这是一个类似于argv的列表,可执行文件位于第一位置,而可执行文件的参数位于列表的其余部分。 然后,我们将CPU设置为使用进程作为其工作量,并最终在CPU中创建功能执行上下文。
process = Process()
process.cmd = [‘tests/test-progs/hello/bin/x86/linux/hello’]
system.cpu.workload = process
system.cpu.createThreads()
我们需要做的最后一件事是实例化系统并开始执行。 首先,我们创建Root对象。 然后我们实例化仿真。 实例化过程遍历了我们在python中创建的所有SimObject,并创建了C ++等效项。
注意,您不必实例化python类,然后将参数明确指定为成员变量。 您还可以将参数作为命名参数传递,例如下面的Root对象。
root = Root(full_system = False, system = system)
m5.instantiate()
最后,我们可以开始实际的模拟了! 顺便说一句,gem5现在正在使用Python 3样式的打印函数,因此print不再是语句,而必须作为函数调用。
print(“Beginning simulation!”)
exit_event = m5.simulate()
模拟完成后,我们就可以检查系统状态。
print(‘Exiting @ tick {} because {}’
.format(m5.curTick(), exit_event.getCause()))
运行gem5
现在,我们已经创建了一个简单的模拟脚本(完整版本可以在gem5/configs/learning_gem5/part1/simple.py中找到),我们可以运行gem5。gem5可以采用许多参数,但只需要一个位置参数即模拟脚本。因此,我们可以简单地从根gem5目录运行gem5:
build/X86/gem5.opt configs/tutorial/simple.py
输出应为:
gem5 Simulator System. http://gem5.org
gem5 is copyrighted software; use the –copyright option for details.gem5 compiled Mar 16 2018 10:24:24
gem5 started Mar 16 2018 15:53:27
gem5 executing on amarillo, pid 41697
command line: build/X86/gem5.opt configs/tutorial/simple.pyGlobal frequency set at 1000000000000 ticks per second
warn: DRAM device capacity (8192 Mbytes) does not match the address range assigned (512 Mbytes)
0: system.remote_gdb: listening for remote gdb on port 7000
Beginning simulation!
info: Entering event queue @ 0. Starting simulation…
Hello world!
Exiting @ tick 507841000 because exiting with last active thread context
可以更改配置文件中的参数,并且结果应该不同。例如,如果您将系统时钟加倍,则模拟应更快地完成。或者,如果将DDR控制器更改为DDR4,性能应该会更好。
此外,您可以将CPU模型更改为MinorCPU以对正序CPU进行建模,或者更改为DerivO3CPU对乱序CPU进行建模。但是,请注意,DerivO3CPU当前无法与simple.py一起使用,因为DerivO3CPU需要一个具有独立指令和数据缓存的系统(DerivO3CPU确实适用于下一部分中的配置)。
接下来,我们将缓存添加到我们的配置文件中,以对更复杂的系统进行建模。
SimObjects私语
gem5的模块化设计围绕SimObject类型构建。 仿真系统中的大多数组件都是SimObject:CPU,缓存,内存控制器,总线等。gem5将所有这些对象从C ++实现导出到python。 因此,从python配置脚本中,您可以创建任何SimObject,设置其参数并指定SimObject之间的交互。
有关更多信息,请参见http://www.gem5.org/SimObjects。
完整系统与系统调用仿真
gem5可以在两种不同的模式下运行,分别称为“系统调用仿真”和“完整系统”或SE和FS模式。在完整系统模式下(稍后在第V部分:完整系统仿真中介绍),gem5仿真整个硬件系统并运行未修改的内核。 完整系统模式类似于运行虚拟机。
另一方面,SE模式不会仿真系统中的所有设备,而是着重于仿真CPU和内存系统。SE更易于配置,因为您无需实例化实际系统中所需的所有硬件设备。 但是,SE只能仿真Linux系统调用,因此只能模拟用户模式代码。
如果您不需要为研究问题建模操作系统,并且想要提高性能,则应使用SE模式。但是,如果您需要对系统进行高保真建模,或者像页面表漫游这样的OS交互很重要,则应使用FS模式。
将缓存添加到配置脚本
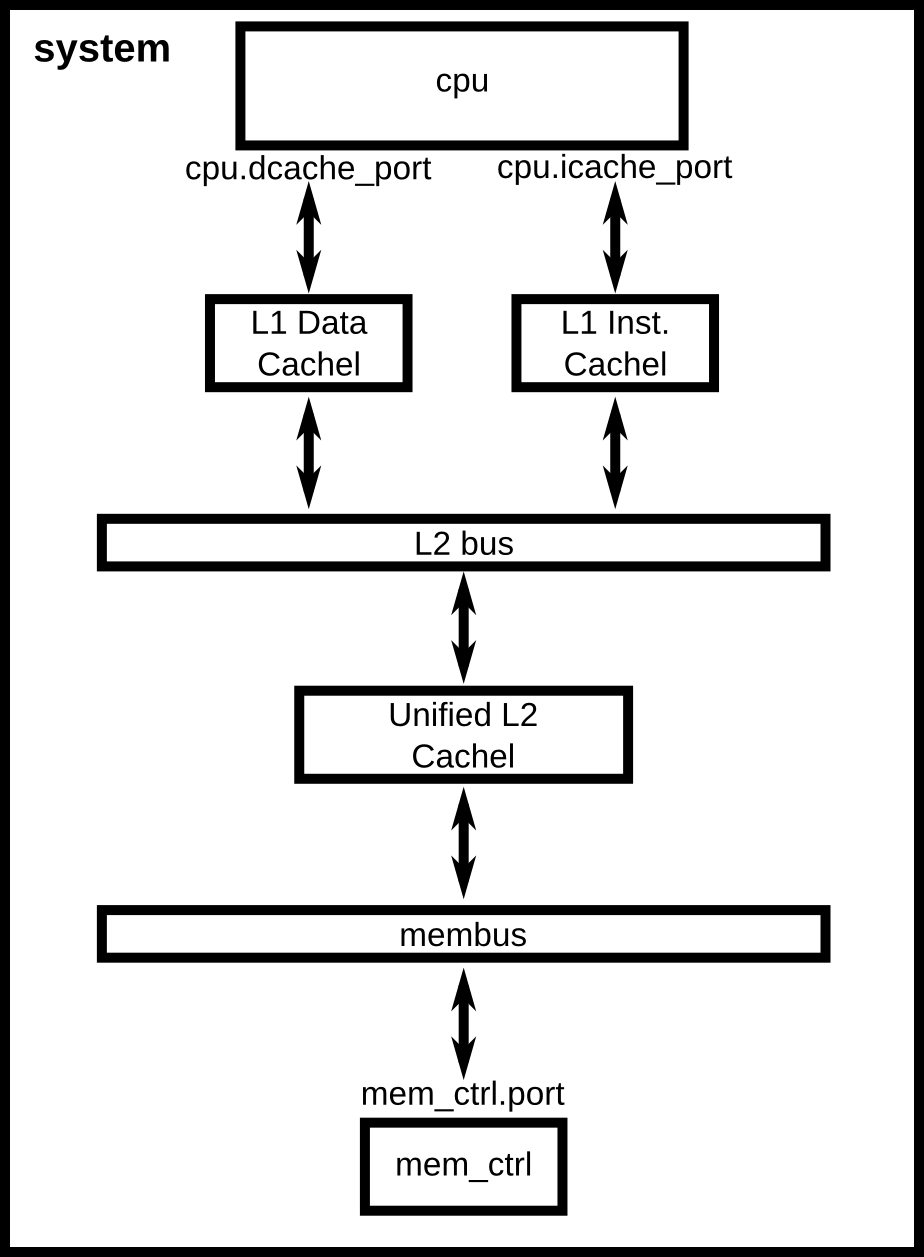
以先前的配置脚本为起点,本章将逐步介绍更复杂的配置。如下图所示,我们将向系统添加一个缓存层次结构。此外,本章还将介绍对gem5统计信息的理解,以及向脚本中添加命令行参数的方法。
具有两级缓存层次结构的系统配置
创建缓存对象
我们将使用经典的缓存,而不是Ruby,因为我们正在为单个CPU系统建模,并且我们不在乎对缓存一致性进行建模。我们将扩展Cache SimObject并为我们的系统配置它。首先,我们必须了解用于配置Cache对象的参数。
Todo
我们应该添加指向SimObjects的链接(例如Cache),以指向gem5位置上的doxygen。
缓存
可以在src/mem/cache/Cache.py中找到Cache SimObject声明。该Python文件定义了您可以设置SimObject的参数。在后台,实例化SimObject时,会将这些参数传递给对象的C++实现。Cache SimObject继承自下面显示的BaseCache对象。
from m5.params import *
from m5.proxy import *
from MemObject import MemObject
from Prefetcher import BasePrefetcher
from ReplacementPolicies import *
from Tags import *class BaseCache(MemObject):
type = ‘BaseCache’
abstract = True
cxx_header = “mem/cache/base.hh”size = Param.MemorySize("Capacity") assoc = Param.Unsigned("Associativity") tag_latency = Param.Cycles("Tag lookup latency") data_latency = Param.Cycles("Data access latency") response_latency = Param.Cycles("Latency for the return path on a miss"); warmup_percentage = Param.Percent(0, "Percentage of tags to be touched to warm up the cache") max_miss_count = Param.Counter(0, "Number of misses to handle before calling exit") mshrs = Param.Unsigned("Number of MSHRs (max outstanding requests)") demand_mshr_reserve = Param.Unsigned(1, "MSHRs reserved for demand access") tgts_per_mshr = Param.Unsigned("Max number of accesses per MSHR") write_buffers = Param.Unsigned(8, "Number of write buffers") is_read_only = Param.Bool(False, "Is this cache read only (e.g. inst)") prefetcher = Param.BasePrefetcher(NULL,"Prefetcher attached to cache") prefetch_on_access = Param.Bool(False, "Notify the hardware prefetcher on every access (not just misses)") tags = Param.BaseTags(BaseSetAssoc(), "Tag store") replacement_policy = Param.BaseReplacementPolicy(LRURP(), "Replacement policy") sequential_access = Param.Bool(False, "Whether to access tags and data sequentially") cpu_side = SlavePort("Upstream port closer to the CPU and/or device") mem_side = MasterPort("Downstream port closer to memory") addr_ranges = VectorParam.AddrRange([AllMemory], "Address range for the CPU-side port (to allow striping)") system = Param.System(Parent.any, "System we belong to")# Enum for cache clusivity, currently mostly inclusive or mostly
# exclusive.
class Clusivity(Enum): vals = [‘mostly_incl’, ‘mostly_excl’]class Cache(BaseCache):
type = ‘Cache’
cxx_header = ‘mem/cache/cache.hh’# Control whether this cache should be mostly inclusive or mostly # exclusive with respect to upstream caches. The behaviour on a # fill is determined accordingly. For a mostly inclusive cache, # blocks are allocated on all fill operations. Thus, L1 caches # should be set as mostly inclusive even if they have no upstream # caches. In the case of a mostly exclusive cache, fills are not # allocating unless they came directly from a non-caching source, # e.g. a table walker. Additionally, on a hit from an upstream # cache a line is dropped for a mostly exclusive cache. clusivity = Param.Clusivity('mostly_incl', "Clusivity with upstream cache") # Determine if this cache sends out writebacks for clean lines, or # simply clean evicts. In cases where a downstream cache is mostly # exclusive with respect to this cache (acting as a victim cache), # the clean writebacks are essential for performance. In general # this should be set to True for anything but the last-level # cache. writeback_clean = Param.Bool(False, "Writeback clean lines")
在BaseCache类中,有许多参数。例如,assoc是一个整数参数。在这种情况下,某些参数(例如write_buffers)具有默认值8。除非第一个参数是字符串,否则默认参数是(Param.*)的第一个参数。每个参数的字符串参数是对该参数的描述(例如,tag_latency = Param.Cycles(“ Tag lookup latency”)表示`tag_latency控制“此缓存的命中延迟”)。
其中许多参数没有默认值,因此我们需要在调用m5.instantiate()之前设置这些参数。
现在,要创建具有特定参数的缓存,我们首先要在与simple.py相同的目录configs/tutorial中创建一个新文件caches.py。第一步是导入我们将在此文件中扩展的SimObject。
from m5.objects import Cache
接下来,我们可以像对待其他任何Python类一样对待BaseCache对象并对其进行扩展。 我们可以根据需要命名新的缓存。让我们首先创建一个L1缓存。
class L1Cache(Cache):
assoc = 2
tag_latency = 2
data_latency = 2
response_latency = 2
mshrs = 4
tgts_per_mshr = 20
在这里,我们正在设置BaseCache的一些没有默认值的参数。要查看所有可能的配置选项,并找出哪些是必需的,哪些是可选的,您必须查看SimObject的源代码。在这种情况下,我们正在使用BaseCache。
我们扩展了BaseCache,并在BaseCache SimObject中设置了大多数没有默认值的参数。接下来,让我们再讨论L1Cache的两个子类:L1DCache和L1ICache.
class L1ICache(L1Cache):
size = ‘16kB’class L1DCache(L1Cache):
size = ‘64kB’
我们还创建一个带有一些合理参数的L2缓存。
class L2Cache(Cache):
size = ‘256kB’
assoc = 8
tag_latency = 20
data_latency = 20
response_latency = 20
mshrs = 20
tgts_per_mshr = 12
既然我们已经指定了BaseCache所需的所有必要参数,那么我们要做的就是实例化子类并将缓存连接到互连。但是,将许多对象连接到复杂的互连可以使配置文件快速增长并变得不可读。因此,首先让我们向Cache的子类中添加一些辅助函数。请记住,这些只是Python类,因此我们可以对它们执行与Python类一样的任何操作。
在L1高速缓存中,我们添加两个功能:connectCPU将CPU连接到高速缓存,以及connectBus将高速缓存连接到总线。 我们需要将以下代码添加到L1Cache类中。
def connectCPU(self, cpu):
# need to define this in a base class!
raise NotImplementedErrordef connectBus(self, bus):
self.mem_side = bus.slave
接下来,我们必须为指令和数据缓存定义一个单独的connectCPU函数,因为指令缓存和数据缓存端口具有不同的名称。现在,我们的L1ICache和L1DCache类变为:
class L1ICache(L1Cache):
size = ‘16kB’def connectCPU(self, cpu): self.cpu_side = cpu.icache_portclass L1DCache(L1Cache):
size = ‘64kB’def connectCPU(self, cpu): self.cpu_side = cpu.dcache_port
最后,让我们向L2Cache添加函数以分别连接到内存侧和CPU侧总线。
def connectCPUSideBus(self, bus):
self.cpu_side = bus.masterdef connectMemSideBus(self, bus):
self.mem_side = bus.slave
完整文件可在gem5源代码中找到,位于gem5/configs/learning_gem5/part1/caches.py。
添加缓存简单的配置文件
现在,让我们将刚刚创建的缓存添加到上一章中创建的配置脚本中。
首先,让我们将脚本复制到一个新名称。
cp simple.py two_level.py
首先,我们需要将名称从caches.py文件导入名称空间。我们可以将以下内容添加到文件顶部(在m5.objects导入之后),就像使用任何Python源代码一样。
from caches import *
现在,在创建CPU之后,让我们创建L1缓存:
system.cpu.icache = L1ICache()
system.cpu.dcache = L1DCache()
并使用我们创建的helper函数将缓存连接到CPU端口。
system.cpu.icache.connectCPU(system.cpu)
system.cpu.dcache.connectCPU(system.cpu)
我们无法将L1缓存直接连接到L2缓存,因为L2缓存只希望有一个端口连接到它。 因此,我们需要创建一个L2总线以将我们的L1缓存连接到L2缓存。然后,我们可以使用我们的helper函数将L1缓存连接到L2总线。
system.l2bus = L2XBar()
system.cpu.icache.connectBus(system.l2bus)
system.cpu.dcache.connectBus(system.l2bus)
接下来,我们可以创建L2缓存并将其连接到L2总线和内存总线。
system.l2cache = L2Cache()
system.l2cache.connectCPUSideBus(system.l2bus)system.l2cache.connectMemSideBus(system.membus)
文件中的所有其他内容保持不变!现在,我们有了具有两级缓存层次结构的完整配置。如果您运行当前文件,则您现在应该在58513000个时钟完成操作。完整的脚本可以在gem5源代码中找到,位于gem5/configs/learning_gem5/part1/two_level.py。
向脚本添加参数
使用gem5进行实验时,您不想每次想用不同的参数测试系统时都编辑配置脚本。为了解决这个问题,您可以将命令行参数添加到gem5配置脚本中。同样,由于配置脚本只是Python,因此您可以使用支持参数解析的Python库。尽管optparse已被正式弃用,但gem5随附的许多配置脚本都使用了它,而不是py:mod:argparse,因为gem5的最低Python版本曾经是2.5。Python的最低版本现在是2.7,因此在编写不需要与当前gem5脚本进行交互的新脚本时,py:mod:argparse是一个更好的选择。要开始使用optparse,您可以查阅在线Python文档。
要在二级缓存配置中添加选项,请在导入缓存后添加一些选项。
from optparse import OptionParser
parser = OptionParser()
parser.add_option(‘–l1i_size’, help=”L1 instruction cache size”)
parser.add_option(‘–l1d_size’, help=”L1 data cache size”)
parser.add_option(‘–l2_size’, help=”Unified L2 cache size”)(options, args) = parser.parse_args()
现在,您可以运行build/X86/gem5.opt configs/tutorial/two_level_opts.py –help,它将显示您刚刚添加的选项。
接下来,我们需要将这些选项传递到我们在配置脚本中创建的缓存上。为此,我们只需更改two_level.py即可将选项作为参数传递给缓存,作为其构造函数的参数,然后添加一个适当的构造函数。
system.cpu.icache = L1ICache(options)
system.cpu.dcache = L1DCache(options)
…
system.l2cache = L2Cache(options)
在caches.py中,我们需要向每个类添加构造函数(Python中的__init__函数)。从基本L1缓存开始,我们将添加一个空的构造函数,因为我们没有适用于基本L1缓存的任何参数。但是,在这种情况下,我们不能忘记调用超类的构造函数。如果跳过对超类构造函数的调用,则在尝试实例化缓存对象时,gem5的SimObject属性查找功能将失败,并且结果将为“ RuntimeError:超出最大递归深度”。因此,在L1Cache中,我们需要在静态类成员之后添加以下内容。
def init(self, options=None):
super(L1Cache, self).init()
pass
接下来,在L1ICache中,我们需要使用我们创建的选项(l1i_size)来设置大小。 在下面的代码中,对于没有将选项传递给L1ICache构造函数以及是否在命令行上未指定选项的情况,有一些防护措施。 在这种情况下,我们将使用已经为尺寸指定的默认值。
def init(self, options=None):
super(L1ICache, self).init(options)
if not options or not options.l1i_size:
return
self.size = options.l1i_size
我们可以对L1DCache使用相同的代码:
def init(self, options=None):
super(L1DCache, self).init(options)
if not options or not options.l1d_size:
return
self.size = options.l1d_size
以及统一的L2Cache:
def init(self, options=None):
super(L2Cache, self).init()
if not options or not options.l2_size:
return
self.size = options.l2_size
通过这些更改,您现在可以从命令行(如下所示)将缓存大小传递到脚本中。
build/X86/gem5.opt configs/tutorial/two_level_opts.py –l2_size=’1MB’ –l1d_size=’128kB’
运行结果为:
gem5 Simulator System. http://gem5.org
gem5 is copyrighted software; use the –copyright option for details.gem5 compiled Sep 6 2015 14:17:02
gem5 started Sep 6 2015 15:06:51
gem5 executing on galapagos-09.cs.wisc.edu
command line: build/X86/gem5.opt ../tutorial/_static/scripts/part1/two_level_opts.py –l2_size=1MB –l1d_size=128kBGlobal frequency set at 1000000000000 ticks per second
warn: DRAM device capacity (8192 Mbytes) does not match the address range assigned (512 Mbytes)
0: system.remote_gdb.listener: listening for remote gdb #0 on port 7000
Beginning simulation!
info: Entering event queue @ 0. Starting simulation…
Hello world!
Exiting @ tick 56742000 because target called exit()
完整的脚本可以在gem5源代码中找到,位于gem5/configs/learning_gem5/part1/caches.py和gem5/configs/learning_gem5/part1/two_level.py。
了解gem5统计信息和输出
在运行gem5之后,除了可以打印出模拟脚本的所有信息外,在名为m5out的目录中还生成了三个文件:
- config.ini
包含为仿真创建的每个SimObject及其参数值的列表。 - config.json
与config.ini相同,但格式为json。 - stats.txt
为模拟注册的所有gem5统计信息的文本表示形式。
这些文件的创建位置可以通过以下方式控制:
–outdir=DIR, -d DIR
要创建的目录,其中包含gem5输出文件,包括config.ini,config.json,stats.txt以及其他文件。如果该目录中的文件已经存在,则将其覆盖。
config.ini
该文件是模拟内容的确定版本。 此文件中显示了模拟的每个SimObject的所有参数,无论是在配置脚本中设置还是使用默认值。
下面是运行“创建简单配置脚本”中的simple.py配置文件时生成的config.ini。[root]
type=Root
children=system
eventq_index=0
full_system=false
sim_quantum=0
time_sync_enable=false
time_sync_period=100000000000
time_sync_spin_threshold=100000000[system]
type=System
children=clk_domain cpu dvfs_handler mem_ctrl membus
boot_osflags=a
cache_line_size=64
clk_domain=system.clk_domain
default_p_state=UNDEFINED
eventq_index=0
exit_on_work_items=false
init_param=0
kernel=
kernel_addr_check=true
kernel_extras=
kvm_vm=Null
load_addr_mask=18446744073709551615
load_offset=0
mem_mode=timing…
[system.membus]
type=CoherentXBar
children=snoop_filter
clk_domain=system.clk_domain
default_p_state=UNDEFINED
eventq_index=0
forward_latency=4
frontend_latency=3
p_state_clk_gate_bins=20
p_state_clk_gate_max=1000000000000
p_state_clk_gate_min=1000
point_of_coherency=true
point_of_unification=true
power_model=
response_latency=2
snoop_filter=system.membus.snoop_filter
snoop_response_latency=4
system=system
use_default_range=false
width=16
master=system.cpu.interrupts.pio system.cpu.interrupts.int_slave system.mem_ctrl.port
slave=system.cpu.icache_port system.cpu.dcache_port system.cpu.interrupts.int_master system.system_port[system.membus.snoop_filter]
type=SnoopFilter
eventq_index=0
lookup_latency=1
max_capacity=8388608
system=system在这里,我们看到,在每个SimObject的描述开始时,首先是它在配置文件中创建的名称被方括号(例如[system.membus])包围。
接下来,将显示SimObject的每个参数及其值,包括未在配置文件中明确设置的参数。例如,配置文件将时钟域设置为1 GHz(在这种情况下为1000 ticks)。但是,它没有设置高速缓存行大小(系统中为64)对象。
config.ini文件是确保您模拟自己想模拟的东西的有用工具。gem5中有许多设置默认值和覆盖默认值的可能方法。始终检查config.ini是一项明智的选择,这是对配置文件中设置的值是否传播到实际SimObject实例的健全性检查。
stats.txt
gem5具有灵活的统计信息生成系统。gem5 Wiki网站上详细介绍了gem5统计信息。SimObject的每个实例都有自己的统计信息。在模拟结束时,或发出特殊的统计信息转储命令时,所有SimObjects的统计信息的当前状态都转储到文件中。
首先,统计文件包含有关执行的常规统计信息:
———- Begin Simulation Statistics ———-
sim_seconds 0.000346 # Number of seconds simulated
sim_ticks 345518000 # Number of ticks simulated
final_tick 345518000 # Number of ticks from beginning of simulation (restored from checkpoints and never reset)
sim_freq 1000000000000 # Frequency of simulated ticks
host_inst_rate 144400 # Simulator instruction rate (inst/s)
host_op_rate 260550 # Simulator op (including micro ops) rate (op/s)
host_tick_rate 8718625183 # Simulator tick rate (ticks/s)
host_mem_usage 778640 # Number of bytes of host memory used
host_seconds 0.04 # Real time elapsed on the host
sim_insts 5712 # Number of instructions simulated
sim_ops 10314 # Number of ops (including micro ops) simulated统计转储以———-Begin Simulation Statistics———-开始。如果在gem5执行期间存在多个统计转储,则单个文件中可能有多个。 这对于长时间运行的应用程序或从检查点还原时很常见。
每个统计信息都有一个名称(第一列),一个值(第二列)和描述(最后一列以#开头)。
大多数统计信息从其描述中都是可以自我解释的。几个重要的统计信息包括sim_seconds(这是模拟的总模拟时间),sim_insts(这是CPU提交的指令数量)和host_inst_rate(告诉您gem5的性能)。
接下来,将打印SimObjects的统计信息。 例如,内存控制器统计信息。 它具有诸如每个组件读取的字节以及这些组件使用的平均带宽之类的信息。
system.clk_domain.voltage_domain.voltage 1 # Voltage in Volts
system.clk_domain.clock 1000 # Clock period in ticks
system.mem_ctrl.pwrStateResidencyTicks::UNDEFINED 507841000 # Cumulative time (in ticks) in various power states
system.mem_ctrl.bytes_read::cpu.inst 58264 # Number of bytes read from this memory
system.mem_ctrl.bytes_read::cpu.data 7167 # Number of bytes read from this memory
system.mem_ctrl.bytes_read::total 65431 # Number of bytes read from this memory
system.mem_ctrl.bytes_inst_read::cpu.inst 58264 # Number of instructions bytes read from this memory
system.mem_ctrl.bytes_inst_read::total 58264 # Number of instructions bytes read from this memory
system.mem_ctrl.bytes_written::cpu.data 7160 # Number of bytes written to this memory
system.mem_ctrl.bytes_written::total 7160 # Number of bytes written to this memory
system.mem_ctrl.num_reads::cpu.inst 7283 # Number of read requests responded to by this memory
system.mem_ctrl.num_reads::cpu.data 1084 # Number of read requests responded to by this memory
system.mem_ctrl.num_reads::total 8367 # Number of read requests responded to by this memory
system.mem_ctrl.num_writes::cpu.data 941 # Number of write requests responded to by this memory
system.mem_ctrl.num_writes::total 941 # Number of write requests responded to by this memory
system.mem_ctrl.bw_read::cpu.inst 114728823 # Total read bandwidth from this memory (bytes/s)
system.mem_ctrl.bw_read::cpu.data 14112685 # Total read bandwidth from this memory (bytes/s)
system.mem_ctrl.bw_read::total 128841507 # Total read bandwidth from this memory (bytes/s)
system.mem_ctrl.bw_inst_read::cpu.inst 114728823 # Instruction read bandwidth from this memory (bytes/s)
system.mem_ctrl.bw_inst_read::total 114728823 # Instruction read bandwidth from this memory (bytes/s)
system.mem_ctrl.bw_write::cpu.data 14098901 # Write bandwidth from this memory (bytes/s)
system.mem_ctrl.bw_write::total 14098901 # Write bandwidth from this memory (bytes/s)
system.mem_ctrl.bw_total::cpu.inst 114728823 # Total bandwidth to/from this memory (bytes/s)
system.mem_ctrl.bw_total::cpu.data 28211586 # Total bandwidth to/from this memory (bytes/s)
system.mem_ctrl.bw_total::total 142940409 # Total bandwidth to/from this memory (bytes/s)该文件的后面是CPU统计信息,其中包含有关syscall数量,分支数量,已提交的指令总数等信息。
system.cpu.dtb.walker.pwrStateResidencyTicks::UNDEFINED 507841000 # Cumulative time (in ticks) in various power states
system.cpu.dtb.rdAccesses 1084 # TLB accesses on read requests
system.cpu.dtb.wrAccesses 941 # TLB accesses on write requests
system.cpu.dtb.rdMisses 9 # TLB misses on read requests
system.cpu.dtb.wrMisses 7 # TLB misses on write requests
system.cpu.apic_clk_domain.clock 16000 # Clock period in ticks
system.cpu.interrupts.pwrStateResidencyTicks::UNDEFINED 507841000 # Cumulative time (in ticks) in various power states
system.cpu.itb.walker.pwrStateResidencyTicks::UNDEFINED 507841000 # Cumulative time (in ticks) in various power states
system.cpu.itb.rdAccesses 0 # TLB accesses on read requests
system.cpu.itb.wrAccesses 7284 # TLB accesses on write requests
system.cpu.itb.rdMisses 0 # TLB misses on read requests
system.cpu.itb.wrMisses 31 # TLB misses on write requests
system.cpu.workload.numSyscalls 11 # Number of system calls
system.cpu.pwrStateResidencyTicks::ON 507841000 # Cumulative time (in ticks) in various power states
system.cpu.numCycles 507841 # number of cpu cycles simulated
system.cpu.numWorkItemsStarted 0 # number of work items this cpu started
system.cpu.numWorkItemsCompleted 0 # number of work items this cpu completed
system.cpu.committedInsts 5712 # Number of instructions committed
system.cpu.committedOps 10313 # Number of ops (including micro ops) committed
system.cpu.num_int_alu_accesses 10204 # Number of integer alu accesses
system.cpu.num_fp_alu_accesses 0 # Number of float alu accesses
system.cpu.num_vec_alu_accesses 0 # Number of vector alu accesses
system.cpu.num_func_calls 221 # number of times a function call or return occured
system.cpu.num_conditional_control_insts 986 # number of instructions that are conditional controls
system.cpu.num_int_insts 10204 # number of integer instructions
system.cpu.num_fp_insts 0 # number of float instructions
system.cpu.num_vec_insts 0 # number of vector instructions
system.cpu.num_int_register_reads 19293 # number of times the integer registers were read
system.cpu.num_int_register_writes 7976 # number of times the integer registers were written
system.cpu.num_fp_register_reads 0 # number of times the floating registers were read
system.cpu.num_fp_register_writes 0 # number of times the floating registers were written
system.cpu.num_vec_register_reads 0 # number of times the vector registers were read
system.cpu.num_vec_register_writes 0 # number of times the vector registers were written
system.cpu.num_cc_register_reads 7020 # number of times the CC registers were read
system.cpu.num_cc_register_writes 3825 # number of times the CC registers were written
system.cpu.num_mem_refs 2025 # number of memory refs
system.cpu.num_load_insts 1084 # Number of load instructions
system.cpu.num_store_insts 941 # Number of store instructions
system.cpu.num_idle_cycles 0 # Number of idle cycles
system.cpu.num_busy_cycles 507841 # Number of busy cycles
system.cpu.not_idle_fraction 1 # Percentage of non-idle cycles
system.cpu.idle_fraction 0 # Percentage of idle cycles
system.cpu.Branches 1306 # Number of branches fetched
使用默认配置脚本
在本章中,我们将探索使用gem5随附的默认配置脚本。gem5附带了许多配置脚本,可让您非常快速地使用gem5。但是,常见的陷阱是使用这些脚本而没有完全了解要模拟的内容。在使用gem5进行计算机体系结构研究时,充分了解要模拟的系统非常重要。本章将引导您完成一些重要的选项以及默认配置脚本的各个部分。
在最后几章中,您是从头开始创建自己的配置脚本的。这非常强大,因为它允许您指定每个单个系统参数。但是,某些系统的设置非常复杂(例如,全系统ARM或x86计算机)。幸运的是,gem5开发人员提供了许多脚本来引导构建系统的过程。
目录结构浏览
gem5的所有配置文件都可以在configs/中找到。 目录结构如下所示:
configs/boot:
ammp.rcS halt.sh micro_tlblat2.rcS netperf-stream-udp-local.rcS
…configs/common:
Benchmarks.py cpu2000.py Options.py
Caches.py FSConfig.py O3_ARM_v7a.py SysPaths.py
CacheConfig.py CpuConfig.py MemConfig.py Simulation.pyconfigs/dram:
sweep.pyconfigs/example:
fs.py read_config.py ruby_mem_test.py ruby_random_test.py
memtest.py ruby_direct_test.py ruby_network_test.py se.pyconfigs/ruby:
MESI_Three_Level.py MI_example.py MOESI_CMP_token.py Network_test.py
MESI_Two_Level.py MOESI_CMP_directory.py MOESI_hammer.py Ruby.pyconfigs/splash2:
cluster.py run.pyconfigs/topologies:
BaseTopology.py Cluster.py Crossbar.py MeshDirCorners.py Mesh.py Pt2Pt.py Torus.py
每个目录的简要说明如下:
- boot/
这些是在完整系统模式下使用的rcS文件。这些文件在Linux引导后由模拟器加载,并由Shell执行。在全系统模式下运行时,其中大多数用于控制基准。其中一些是实用程序功能,例如hack_back_ckpt.rcS。 这些文件将在全系统仿真一章中更深入地介绍。 - common/
该目录包含许多帮助程序脚本和创建模拟系统的功能。例如,Caches.py与前面各章中创建的caches.py和caches_opts.py文件相似。
Options.py包含可以在命令行上设置的各种选项。 像CPU的数量,系统时钟等等。 这是查看是否要更改的选项是否已包含命令行参数的好地方。
CacheConfig.py包含用于设置经典内存系统的缓存参数的选项和功能。
MemConfig.py提供了一些用于设置内存系统的帮助程序功能。
FSConfig.py包含必要的功能,可为许多不同类型的系统设置全系统仿真。全系统仿真将在本章中进一步讨论。
Simulation.py包含许多帮助函数,用于设置和运行gem5。此文件中包含的许多代码都用于管理保存和还原检查点。下列example/中的示例配置文件使用该文件中的功能来执行gem5仿真。该文件非常复杂,但是它在模拟的运行方式上也提供了很大的灵活性。 - dram/
包含用于测试DRAM的脚本。 - example/
该目录包含一些示例gem5配置脚本,可以直接使用它们来运行gem5。具体来说,se.py和fs.py非常有用。有关这些文件的更多信息,请参见下一部分。此目录中还有一些其他实用程序配置脚本。 - ruby/
此目录包含Ruby及其随附的缓存一致性协议的配置脚本。更多细节可以在Ruby一章中找到。 - splash2/
该目录包含用于运行splash2基准套件的脚本,其中包含一些用于配置模拟系统的选项。 - topologies/
该目录包含创建Ruby缓存层次结构时可以使用的拓扑的实现。更多细节可以在Ruby一章中找到。
使用se.py和fs.py
在本节中,我将讨论一些可以在命令行上传递给se.py和fs.py的常用选项。有关如何运行全系统模拟的更多详细信息,请参见“全系统模拟”一章。在这里,我将讨论两个文件共有的选项。
本节中讨论的大多数选项都可以在Options.py中找到,并已在addCommonOptions函数中注册。本节未详细介绍所有选项,要查看所有选项,请使用–help运行配置脚本,或阅读脚本的源代码。
首先,我们简单地运行不带任何参数的hello world程序:
build/X86/gem5.opt configs/example/se.py –cmd=tests/test-progs/hello/bin/x86/linux/hello
并获得以下输出:
gem5 Simulator System. http://gem5.org
gem5 is copyrighted software; use the –copyright option for details.gem5 compiled Jan 14 2015 16:11:34
gem5 started Feb 2 2015 15:22:24
gem5 executing on mustardseed.cs.wisc.edu
command line: build/X86/gem5.opt configs/example/se.py –cmd=tests/test-progs/hello/bin/x86/linux/hello
Global frequency set at 1000000000000 ticks per second
warn: DRAM device capacity (8192 Mbytes) does not match the address range assigned (512 Mbytes)
0: system.remote_gdb.listener: listening for remote gdb #0 on port 7000
** REAL SIMULATION **
info: Entering event queue @ 0. Starting simulation…
Hello world!
Exiting @ tick 5942000 because target called exit()
但是,这根本不是一个非常有趣的模拟!默认情况下,gem5使用原子CPU并使用原子内存访问,因此没有实际的时序数据报告!要确认这一点,您可以查看m5out/config.ini。CPU显示在第46行:
[system.cpu]
type=AtomicSimpleCPU
children=apic_clk_domain dtb interrupts isa itb tracer workload
branchPred=Null
checker=Null
clk_domain=system.cpu_clk_domain
cpu_id=0
do_checkpoint_insts=true
do_quiesce=true
do_statistics_insts=true
要在计时模式下实际运行gem5,请指定CPU类型。在此期间,我们还可以指定L1缓存的大小。
build/X86/gem5.opt configs/example/se.py –cmd=tests/test-progs/hello/bin/x86/linux/hello –cpu-type=TimingSimpleCPU –l1d_size=64kB –l1i_size=16kB
gem5 Simulator System. http://gem5.org
gem5 is copyrighted software; use the –copyright option for details.gem5 compiled Jan 14 2015 16:11:34
gem5 started Feb 2 2015 15:26:57
gem5 executing on mustardseed.cs.wisc.edu
command line: build/X86/gem5.opt configs/example/se.py –cmd=tests/test-progs/hello/bin/x86/linux/hello –cpu-type=TimingSimpleCPU –l1d_size=64kB –l1i_size=16kB
Global frequency set at 1000000000000 ticks per second
warn: DRAM device capacity (8192 Mbytes) does not match the address range assigned (512 Mbytes)
0: system.remote_gdb.listener: listening for remote gdb #0 on port 7000
** REAL SIMULATION **
info: Entering event queue @ 0. Starting simulation…
Hello world!
Exiting @ tick 344986500 because target called exit()
现在,让我们检查config.ini文件,并确保将这些选项正确传播到最终系统。 如果在m5out/config.ini中搜索“cache”,则会发现未创建任何缓存! 即使我们指定了缓存的大小,也没有指定系统应使用缓存,因此未创建缓存。 正确的命令行应为:
build/X86/gem5.opt configs/example/se.py –cmd=tests/test-progs/hello/bin/x86/linux/hello –cpu-type=TimingSimpleCPU –l1d_size=64kB –l1i_size=16kB –caches
gem5 Simulator System. http://gem5.org
gem5 is copyrighted software; use the –copyright option for details.gem5 compiled Jan 14 2015 16:11:34
gem5 started Feb 2 2015 15:29:20
gem5 executing on mustardseed.cs.wisc.edu
command line: build/X86/gem5.opt configs/example/se.py –cmd=tests/test-progs/hello/bin/x86/linux/hello –cpu-type=TimingSimpleCPU –l1d_size=64kB –l1i_size=16kB –caches
Global frequency set at 1000000000000 ticks per second
warn: DRAM device capacity (8192 Mbytes) does not match the address range assigned (512 Mbytes)
0: system.remote_gdb.listener: listening for remote gdb #0 on port 7000
** REAL SIMULATION **
info: Entering event queue @ 0. Starting simulation…
Hello world!
Exiting @ tick 29480500 because target called exit()
在最后一行,我们看到总时间从344986500个周期变为29480500个周期,速度要快得多!看起来缓存现在可能已启用。但是,最好再次检查config.ini文件。
[system.cpu.dcache]
type=BaseCache
children=tags
addr_ranges=0:18446744073709551615
assoc=2
clk_domain=system.cpu_clk_domain
demand_mshr_reserve=1
eventq_index=0
forward_snoops=true
hit_latency=2
is_top_level=true
max_miss_count=0
mshrs=4
prefetch_on_access=false
prefetcher=Null
response_latency=2
sequential_access=false
size=65536
system=system
tags=system.cpu.dcache.tags
tgts_per_mshr=20
two_queue=false
write_buffers=8
cpu_side=system.cpu.dcache_port
mem_side=system.membus.slave[2]
se.py和fs.py一些常见的选项
运行如下指令时会打印所有可能的选项:
build/X86/gem5.opt configs/example/se.py –help
以下是该列表中的一些重要选项。
- –cpu-type=CPU_TYPE
要运行的cpu的类型。这是始终设置的重要参数。默认值为atomic,它不执行时序仿真。 - –sys-clock=SYS_CLOCK
以系统速度运行的块的顶层时钟。 - –cpu-clock=CPU_CLOCK
以CPU速度运行的块的时钟。这与上面的系统时钟是分开的。 - –mem-type=MEM_TYPE
要使用的内存类型。选项包括不同的DDR内存和ruby内存控制器。 - –caches
使用经典缓存执行仿真。 - –l2cache
如果使用经典缓存,请使用L2缓存执行仿真。 - –ruby
使用Ruby代替传统的高速缓存作为高速缓存系统模拟。 - -m TICKS, –abs-max-tick=TICKS
运行到指定的绝对模拟周期,包括来自已还原检查点的周期。如果您只想模拟一定数量的模拟时间,这将很有用。 - -I MAXINSTS, –maxinsts=MAXINSTS
要模拟的指令总数(默认值:永远运行)。如果要在执行一定数量的指令后停止仿真,此功能很有用。 - -c CMD, –cmd=CMD
在系统调用仿真模式下运行的二进制文件。 - -o OPTIONS, –options=OPTIONS
传递给二进制文件的选项,使用“”扩起整个字符串。当您运行带有选项的命令时,这很有用。您可以通过此变量传递参数和选项(例如–whatever)。 - –output=OUTPUT
将标准输出重定向到文件。如果您想将模拟应用程序的输出重定向到文件而不是打印到屏幕,这将很有用。注意:要重定向gem5输出,必须在配置脚本之前传递参数。 - –errout=ERROUT
将stderr重定向到文件。与上面类似。
Hello World
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
Quick Start
Create a new post
1 | $ hexo new "My New Post" |
More info: Writing
Run server
1 | $ hexo server |
More info: Server
Generate static files
1 | $ hexo generate |
More info: Generating
Deploy to remote sites
1 | $ hexo deploy |
More info: Deployment